Mạng nơ-ron tích chập (P2-hết)
Phần 1 Học sâu (Deep learning) Bạn có thể thấy rằng các đầu vào cho mỗi layer (mảng hai chiều) trông rất giống đầu ra (cũng mảng hai chiều). Vì vậy, chúng ta có thể xếp chồng chúng như những mẩu Lego. Những hình ảnh gốc được filtered (lọc), rectified (tinh chỉnh) và pooled (gộp lại) để tạo ...
Phần 1
Học sâu (Deep learning)
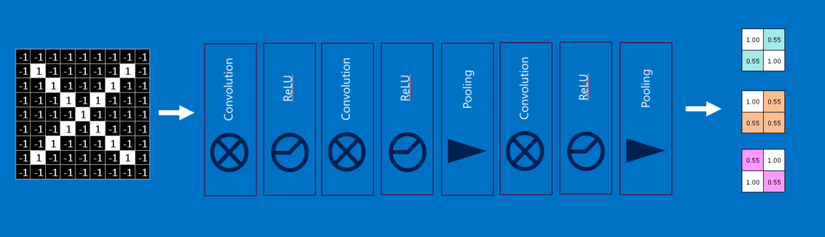
Bạn có thể thấy rằng các đầu vào cho mỗi layer (mảng hai chiều) trông rất giống đầu ra (cũng mảng hai chiều). Vì vậy, chúng ta có thể xếp chồng chúng như những mẩu Lego. Những hình ảnh gốc được filtered (lọc), rectified (tinh chỉnh) và pooled (gộp lại) để tạo ra một tập các hình ảnh đã được lọc và thu gọn. Chúng có thể được lọc và thu gọn lại liên tục. Mỗi lần như vậy, các feature trở nên lớn hơn và phức tạp hơn, và hình ảnh trở nên nhỏ gọn hơn. Điều này giúp các layer thấp hơn đại diện cho các khía cạnh đơn giản của hình ảnh, chẳng hạn như các cạnh và các điểm sáng. Các layer cao hơn có thể đại diện cho các khía cạnh tinh vi hơn của hình ảnh, chẳng hạn như các hình khối (shape) và các hình mẫu (pattern). Dễ thấy được điều này. Ví dụ, trong một CNN được đào tạo nhận diện mặt người, các lớp cao nhất đại diện cho các mẫu giống khuôn mặt người rất rõ ràng.

Các layer được kết nối đầy đủ (Fully connected layers)
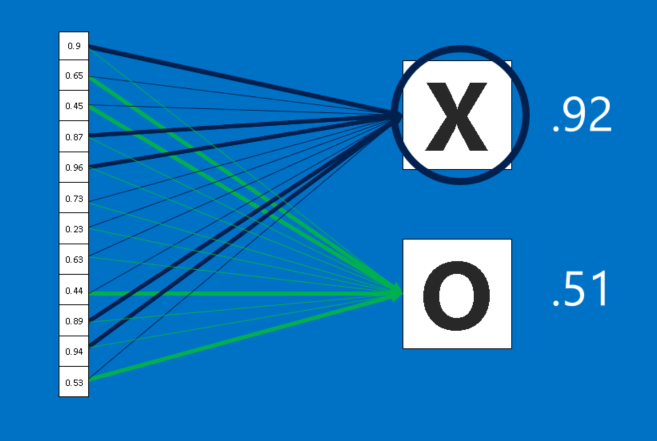
Các CNN còn có một thứ vũ khí nữa. Các layer được kết nối đầy đủ lấy các hình ảnh đã lọc ở cấp cao và chuyển chúng thành các phiếu bầu (vote). Trường hợp của chúng ta, chỉ phải quyết định giữa hai loại, X và O. Các layer được kết nối đầy đủ là một khối chính của mạng nơ-ron truyền thống. Thay vì coi đầu vào như một mảng hai chiều, chúng được coi như một list đơn và tất cả đều được xử lý giống nhau. Mỗi giá trị bỏ phiếu riêng bầu cho hình ảnh hiện tại là X hay O. Tuy nhiên, quá trình này không hoàn toàn dân chủ. Một số giá trị cho biết hình ảnh là một X tốt hơn nhiều so với những giá trị khác, và một số lại đặc biệt tốt khi cho biết hình ảnh là một O. Chúng có giá trị bỏ phiếu lớn hơn so với những cái khác. Chúng được thể hiện như trọng số (weight), hoặc là mức độ kết nối, giữa mỗi giá trị (trong list) và mỗi loại (X hay O).
Khi một hình ảnh mới được đưa vào CNN, nó sẽ thấm qua các lớp thấp hơn cho đến khi cuối cùng nó đạt đến các layer được kết nối đầy đủ. Sau đó, một cuộc bầu chọn được tổ chức. Câu trả lời có nhiều phiếu nhất sẽ thắng và được tuyên bố là thuộc loại nào (X hay O).

Các layer được kết nối đầy đủ, giống như các layer khác, có thể được xếp chồng lên nhau vì đầu ra của chúng (một list các vote) trông giống với đầu vào (một list các giá trị). Trong thực tế, một vài các layer được kết nối đầy đủ thường được xếp chồng lên cùng với nhau, với mỗi layer trung gian bỏ phiếu cho các loại "ẩn". Mỗi layer bổ sung sẽ cho phép mạng học các tổ hợp tinh vi hơn của các feature và sẽ giúp nó đưa ra quyết định tốt hơn.
Lan truyền ngược (Backpropagation)
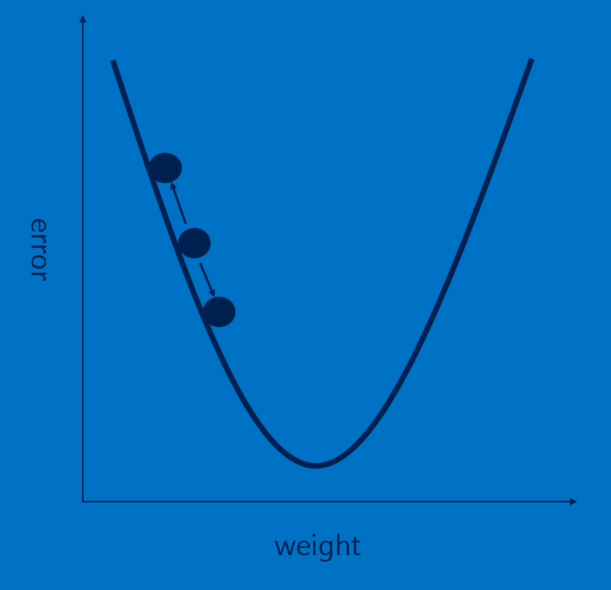
Câu chuyện của chúng ta đang được lấp đầy, nhưng nó vẫn có một lỗ hổng lớn - Các feature đến từ đâu? và Làm thế nào để tìm trọng số trong các layer được kết nối đầy đủ? Nếu chúng phải chọn bằng tay, CNN hẳn sẽ kém phổ biến hơn giờ. May mắn thay, một chút ma thuật của học máy (machine learning) gọi là lan truyền ngược (backpropagation) làm việc này giúp chúng ta.
Để sử dụng lan truyền ngược, chúng ta cần một tập các hình ảnh mà chúng ta đã biết câu trả lời. Điều này có nghĩa rằng một số thanh niên kiên nhẫn sẽ lật qua hàng ngàn hình ảnh và gán cho chúng một nhãn X hoặc O. Chúng ta sử dụng chúng với một CNN chưa được huấn luyện, nghĩa là mỗi điểm ảnh của mỗi feature và mỗi trọng số trong mỗi các layer được kết nối đầy đủ được đặt một giá trị ngẫu nhiên. Sau đó ta bắt đầu đưa các hình ảnh đi qua nó, từng cái một.
Mỗi hình ảnh CNN xử lý cho kết quả là một phiếu bầu (vote). Số lượng nhầm lẫn trong phiếu bầu, gọi là sai số (error), cho ta biết mức độ tốt của các feature và trọng số chúng ta đang có. Các feature và trọng số sau đó có thể được điều chỉnh để làm cho các sai số ít hơn. Mỗi giá trị được điều chỉnh cao hơn một chút và thấp hơn một chút, và tính toán các sai số mới mỗi lần. Điều chỉnh nào làm cho các sai số ít đi sẽ được giữ lại. Sau khi làm điều này cho mỗi điểm ảnh feature trong mỗi layer tích chập và mỗi trọng số trong mỗi các layer được kết nối đầy đủ, các trọng số mới sẽ đưa ra câu trả lời tốt hơn một chút cho hình ảnh đó. Điều này sau đó được lặp đi lặp lại với mỗi hình ảnh tiếp theo trong tập các hình ảnh đã được gắn nhãn. Các khuyết tật xảy ra trong một hình ảnh nhanh chóng bị lãng quên, nhưng hình mẫu (pattern) xuất hiện trong rất nhiều hình ảnh được chế biến thành các feature và các trọng số kết nối. Nếu bạn có đủ các hình ảnh đã được gắn nhãn, chúng sẽ hình thành một tập ổn định hoạt động khá tốt trên một loạt các trường hợp.
Có lẽ là rõ ràng, lan truyền ngược lại là một bước tính toán đắt đỏ nữa, và sẽ lại là một động lực để phát triển phần cứng tính toán chuyên dụng.
Siêu tham số (Hyperparameters)
Thật không may, không phải mọi khía cạnh của các CNN có thể học được một cách đơn giản. Hiện vẫn còn một danh sách dài các quyết định mà một nhà thiết kế CNN phải làm.
- Đối với mỗi layer tích chập, bao nhiêu feature? bao nhiêu điểm ảnh trong mỗi feature?
- Đối với mỗi layer pooling, kích cỡ ô vuông cửa sổ như thế nào? duyệt mỗi bước bao nhiêu?
- Đối với mỗi các layer được kết nối đầy đủ thêm vào, bao nhiêu nơron ẩn?
Ngoài ra còn có những quyết định về kiến trúc ở cấp cao hơn cần thực hiện: Số lượng mỗi layer thêm vào là bao nhiêu? Theo thứ tự nào? Một số mạng nơron học sâu có thể có hơn một ngàn layer, mở ra rất nhiều khả năng.
Với rất nhiều tổ hợp và hoán vị, chỉ một phần nhỏ các cấu hình có thể của CNN đã được thử nghiệm. Các thiết kế CNN có xu hướng được dẫn dắt bởi kiến thức tích lũy từ cộng đồng, thỉnh thoảng các biến thể lại cho thấy những bước nhảy đáng ngạc nhiên về hiệu năng. Và trong khi chúng ta bàn về các khối xây dựng nên một CNN thuần, thì có rất nhiều cách tinh chỉnh khác đã được thử và cho thấy hiệu quả, chẳng hạn như các loại layer mới và những cách phức tạp hơn để kết nối các layer với nhau.
Ngoài các hình ảnh

Trong khi ví dụ X và O liên quan đến hình ảnh, các CNN còn có thể được sử dụng để phân loại các loại dữ liệu khác. Bí quyết là, bất cứ loại dữ liệu nào, hãy biến đổi để làm cho nó trông giống như một hình ảnh. Ví dụ, các tín hiệu âm thanh có thể được cắt nhỏ thành các khối thời gian ngắn, và sau đó mỗi đoạn chia thành âm trầm, âm trung, âm cao, hoặc dải tần số tốt hơn. Cái này có thể được biểu diễn như là một mảng hai chiều trong đó mỗi cột là một đoạn thời gian và mỗi hàng là một băng tần. "Các điểm ảnh" trong hình ảnh giả này mà ở gần nhau có liên quan chặt chẽ. Các CNN hoạt động tốt với cái này. Các nhà nghiên cứu khá sáng tạo. Họ đã dùng dữ liệu văn bản để xử lý ngôn ngữ tự nhiên và ngay cả dữ liệu hóa chất để phát hiện ma túy.
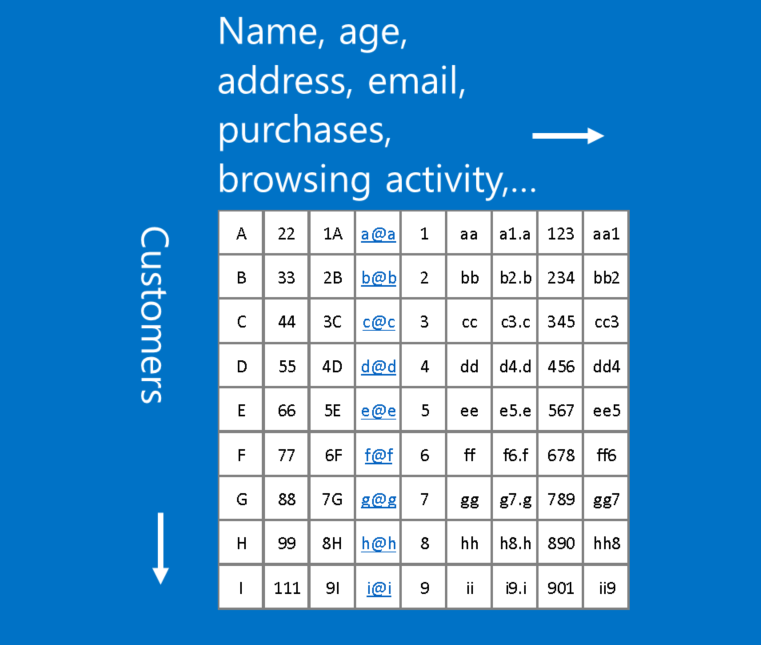
Một ví dụ về dữ liệu không phù hợp với định dạng này là dữ liệu khách hàng, trong đó mỗi hàng trong một bảng đại diện cho một khách hàng, và mỗi cột thể hiện các thông tin về họ, chẳng hạn như tên, địa chỉ, email, lịch sử duyệt và mua hàng. Trong trường hợp này, vị trí của các hàng và cột không thực sự quan trọng. Hàng có thể được sắp xếp lại và cột có thể được xếp đặt lại mà không bị mất bất kỳ tính hữu dụng của dữ liệu. Ngược lại, sắp xếp lại các hàng và cột của một hình ảnh làm cho nó hầu như vô dụng.
Một nguyên tắc: Nếu dữ liệu của bạn vẫn hữu ích sau khi tráo các cột với nhau, thì bạn không nên sử dụng Mạng nơ-ron tích chập.
Tuy nhiên nếu bạn có thể làm cho vấn đề của bạn giống như bài toán tìm kiếm các hình mẫu trong ảnh, thì các CNN có lẽ là chính xác những gì bạn cần.
Tham khảo
- Bài viết gốc http://brohrer.github.io/how_convolutional_neural_networks_work.html
- Tham khảo thuật ngữ https://ongxuanhong.wordpress.com/2015/12/29/convolutional-neural-networks-la-gi/
- Tham khảo https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner's-Guide-To-Understanding-Convolutional-Neural-Networks/
