Marketing với Python Part 3 - Dự đoán lợi nhuận từ khách hàng
Dự đoán lợi nhuận từ khách hàng Xây dựng mô hình dự đoán sử dụng XGBoost Multi-classification Loạt bài bài viết được thiết kế để giải thích làm thế nào sử dụng Python để phát triển công ty theo hướng phân tích dữ liệu. Các bài viết sẽ bao gồm các kỹ thuật như: lập trình python, phân ...
Dự đoán lợi nhuận từ khách hàng
Xây dựng mô hình dự đoán sử dụng XGBoost Multi-classification
Loạt bài bài viết được thiết kế để giải thích làm thế nào sử dụng Python để phát triển công ty theo hướng phân tích dữ liệu. Các bài viết sẽ bao gồm các kỹ thuật như: lập trình python, phân tích dữ liệu, máy học. Chúng ta sẽ đi tìm hiểu các chủ đề sau:
- Hiểu dữ liệu của bạn
- Phân khúc khách hàng
- Dự đoán lợi nhuận từ khách hàng
- Dự đoán khách hàng rời bỏ sử dụng dịch vụ của công ty
- Dự đoán ngày mua hàng tiếp theo của khách hàng
- Dự đoán tình hình kinh doanh
- Kiểm thử đánh giá các chiến dịch Marketing
- Upsell
- A/B testing
Bài viết sử dụng Python và Pandas, nên nếu các bạn chưa biết thì có thể tìm hiểu trước Python và Pandas nhé. Hoặc các bạn làm Marketing chưa biết code, vẫn có thể đọc qua bài viết để hiểu ý tưởng sử dụng dữ liệu hiện có để phát triển công ty.
Sometimes you gotta run before you can walk - Tony Stark
Yêu cầu hệ thống: cài Jupyter Notebook và Python
Phần 3: Dự đoán lợi nhuận từ khách hàng (Customer Lifetime value)
Trong bài viết trước, chúng tra đã biết cách phân loại khách hàng, và tìm ra được tập khách hàng tốt nhất. Trong bài này, chúng ta tiếp tục tìm hiểu và đo lường thông số quan trong nhất trong kinh doanh: Customer Lifetime Value
Theo wiki, Customer Lifetime value ( CLV ) là một dự đoán giá trị lợi nhuận từ khách hàng mang về cho công ty trong suốt quá trình sử dụng sản phẩm, dịch vụ. Có thể hiểu là, đây là thông số để đo đếm số tiền mang lại cho công ty từ khách hàng sau khi đã trừ đi các chi phí marketing, vận hành dịch vụ...
Lifetime Value = Tổng doanh thu - Tổng chi phí
Để bán được sản phẩm dịch vụ, chúng ta đã đầu tư rất nhiều vào marketing, các chương trình khuyến mãi, giảm giá... để tạo ra doanh thu và lợi nhuận. Thường thì sau một chương lược kinh doanh, sẽ mang về cho công ty khách hàng và doanh thu cho công ty, cũng có lúc doanh thu tăng nhưng lợi nhuận lại giảm. Chúng ta cần phải xác định nhóm khách hàng nào mang lại lợi nhuận cho công ty, nhóm nào không để ra chiến lược kinh doanh hiệu quả.
Theo nguyên tắc Pareto trong kinh doanh, chỉ ra rằng 20% khách hàng sẽ đại diện cho 80% doanh thu. Vậy làm thế nào để xác định được nhóm 20% khách hàng này trong quá khứ và tương lai? CLV sẽ là công cụ để chúng ta làm được điều này.
Trước tiên, chúng ta cần phải tính lợi nhuận của từng khách hàng trong một khoảng thời gian nào đó trong quá khứ ( 3, 6, 12, 24 tháng). Nếu chúng ta thấy doanh thu không bằng chi phí bỏ ra, thì cần phải điều chỉnh lại chiến lược kinh doanh ngay, và cũng có thể ngay thời điểm nhận ra vấn đề này để điều chỉnh thì đã quá muộn, công ty thua lỗ... Vì vậy, chúng ta cần phải thấy trước được việc đó có xảy ra trong tương lai hay không bằng cách sử dụng các thuật toán máy học:

Chúng ta sẽ xây dựng mô hình máy học đơn giản để dự đoán CLV.
Dự đoán lợi nhuận
Chúng ta sẽ tiếp tục sử dụng tập dữ liệu như các bài viết trước, các bạn có thể download tại đây. Trước tiên chúng ta cần phải xác định các yếu tố sau:
- Chọn khung thời gian hợp lý (2,4,12, 14 tháng ...) để tính CLV
- Xác định các thuộc tính được sử dụng để dự đoán CLV
- Tính toán CLV
- Xây dựng và chạy mô hình máy học
- Đánh giá mô hình xem có tốt hay không
Việc chọn khung thời gian tính toán CLV tùy thuộc vào ngành nghề, lĩnh vực kinh doanh, chiến lược... Có một số ngành nghề, 1 năm là một khoảng thời gian dài, trong khi nó lại là ngắn so với ngành nghề khác. Trong bài viết này, chúng ta sẽ lấy khoảng thời gian 6 tháng để làm ví dụ.
Ta thấy, điểm số RFM của từng khách hàng được tính như bài viết trước sẽ được chọn là thuộc tính tốt nhất để dự đoán CLV. Để tính toán đúng, chúng ta cần chia tập dữ liệu: lấy tập 3 tháng để tính RFM, và dùng nó để dự đoán CLV 6 tháng tiếp theo. Vì vậy, chúng ta tạo ra 2 tập dữ liệu và tính toán RFM trên 2 tập dữ liệu đó:
#import libraries
from datetime import datetime, timedelta,date
import pandas as pd
%matplotlib inline
from sklearn.metrics import classification_report,confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from __future__ import division
from sklearn.cluster import KMeans
import plotly.plotly as py
import plotly.offline as pyoff
import plotly.graph_objs as go
import xgboost as xgb
from sklearn.model_selection import KFold, cross_val_score, train_test_split
import xgboost as xgb
#initate plotly
pyoff.init_notebook_mode()
#read data from csv and redo the data work we done before
tx_data = pd.read_csv('data.csv')
tx_data['InvoiceDate'] = pd.to_datetime(tx_data['InvoiceDate'])
tx_uk = tx_data.query("Country=='United Kingdom'").reset_index(drop=True)
#create 3m and 6m dataframes
tx_3m = tx_uk[(tx_uk.InvoiceDate < date(2011,6,1)) & (tx_uk.InvoiceDate >= date(2011,3,1))].reset_index(drop=True)
tx_6m = tx_uk[(tx_uk.InvoiceDate >= date(2011,6,1)) & (tx_uk.InvoiceDate < date(2011,12,1))].reset_index(drop=True)
#create tx_user for assigning clustering
tx_user = pd.DataFrame(tx_3m['CustomerID'].unique())
tx_user.columns = ['CustomerID']
#order cluster method
def order_cluster(cluster_field_name, target_field_name,df,ascending):
new_cluster_field_name = 'new_' + cluster_field_name
df_new = df.groupby(cluster_field_name)[target_field_name].mean().reset_index()
df_new = df_new.sort_values(by=target_field_name,ascending=ascending).reset_index(drop=True)
df_new['index'] = df_new.index
df_final = pd.merge(df,df_new[[cluster_field_name,'index']], on=cluster_field_name)
df_final = df_final.drop([cluster_field_name],axis=1)
df_final = df_final.rename(columns={"index":cluster_field_name})
return df_final
#calculate recency score
tx_max_purchase = tx_3m.groupby('CustomerID').InvoiceDate.max().reset_index()
tx_max_purchase.columns = ['CustomerID','MaxPurchaseDate']
tx_max_purchase['Recency'] = (tx_max_purchase['MaxPurchaseDate'].max() - tx_max_purchase['MaxPurchaseDate']).dt.days
tx_user = pd.merge(tx_user, tx_max_purchase[['CustomerID','Recency']], on='CustomerID')
kmeans = KMeans(n_clusters=4)
kmeans.fit(tx_user[['Recency']])
tx_user['RecencyCluster'] = kmeans.predict(tx_user[['Recency']])
tx_user = order_cluster('RecencyCluster', 'Recency',tx_user,False)
#calcuate frequency score
tx_frequency = tx_3m.groupby('CustomerID').InvoiceDate.count().reset_index()
tx_frequency.columns = ['CustomerID','Frequency']
tx_user = pd.merge(tx_user, tx_frequency, on='CustomerID')
kmeans = KMeans(n_clusters=4)
kmeans.fit(tx_user[['Frequency']])
tx_user['FrequencyCluster'] = kmeans.predict(tx_user[['Frequency']])
tx_user = order_cluster('FrequencyCluster', 'Frequency',tx_user,True)
#calcuate revenue score
tx_3m['Revenue'] = tx_3m['UnitPrice'] * tx_3m['Quantity']
tx_revenue = tx_3m.groupby('CustomerID').Revenue.sum().reset_index()
tx_user = pd.merge(tx_user, tx_revenue, on='CustomerID')
kmeans = KMeans(n_clusters=4)
kmeans.fit(tx_user[['Revenue']])
tx_user['RevenueCluster'] = kmeans.predict(tx_user[['Revenue']])
tx_user = order_cluster('RevenueCluster', 'Revenue',tx_user,True)
#overall scoring
tx_user['OverallScore'] = tx_user['RecencyCluster'] + tx_user['FrequencyCluster'] + tx_user['RevenueCluster']
tx_user['Segment'] = 'Low-Value'
tx_user.loc[tx_user['OverallScore']>2,'Segment'] = 'Mid-Value'
tx_user.loc[tx_user['OverallScore']>4,'Segment'] = 'High-Value'
Chúng ta đã tạo và tính toán RFM:
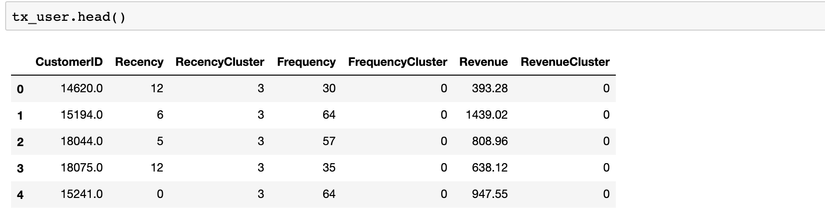
Tiếp tục, chúng ta tính toán CLV của mỗi khách hàng trong 6 tháng, dữ liệu này sẽ được sử dụng để huấn luyện mô hình. Vì trong tập dữ liệu không có giá trị chi phí, nên lợi nhuận cũng chính là các giá trị CLV này. Nếu dữ liệu của bạn có giá trị này, thì CLV sẽ được tính như công thức ở đầu bài viết.
#calculate revenue and create a new dataframe for it
tx_6m['Revenue'] = tx_6m['UnitPrice'] * tx_6m['Quantity']
tx_user_6m = tx_6m.groupby('CustomerID')['Revenue'].sum().reset_index()
tx_user_6m.columns = ['CustomerID','m6_Revenue']
#plot LTV histogram
plot_data = [
go.Histogram(
x=tx_user_6m.query('m6_Revenue < 10000')['m6_Revenue']
)
]
plot_layout = go.Layout(
title='6m Revenue'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
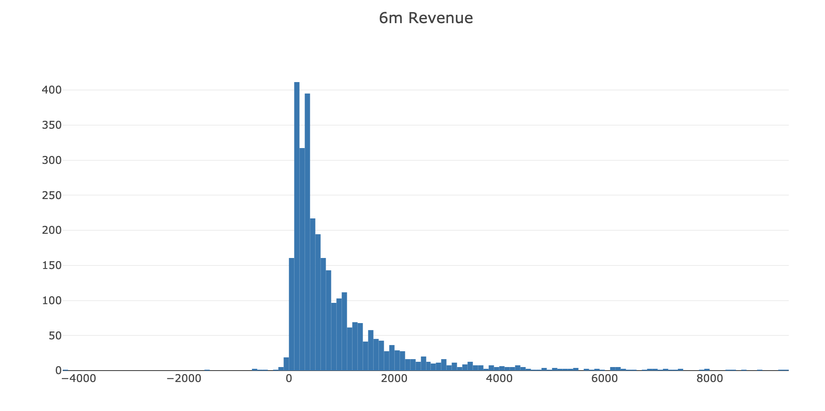
Theo biểu đồ, chúng ta thấy có một số khách hàng mang về lợi nhuận âm, và cũng có một vài dữ liệu nhiễu (dữ liệu khác với bình thường: mang giá trị quá lớn, hoặc quá nhỏ...). Chúng ta cần phải loại bỏ các dữ liệu loại này.
Tiếp theo, chúng ta gôm 2 dữ liệu 3 tháng và 6 tháng lại thành một để có cái nhìn tổng quan hơn về mối liên hệ giữa LTV và các thuộc tính khác với nhau:
tx_merge = pd.merge(tx_user, tx_user_6m, on='CustomerID', how='left')
tx_merge = tx_merge.fillna(0)
tx_graph = tx_merge.query("m6_Revenue < 30000")
plot_data = [
go.Scatter(
x=tx_graph.query("Segment == 'Low-Value'")['OverallScore'],
y=tx_graph.query("Segment == 'Low-Value'")['m6_Revenue'],
mode='markers',
name='Low',
marker= dict(size= 7,
line= dict(awidth=1),
color= 'blue',
opacity= 0.8
)
),
go.Scatter(
x=tx_graph.query("Segment == 'Mid-Value'")['OverallScore'],
y=tx_graph.query("Segment == 'Mid-Value'")['m6_Revenue'],
mode='markers',
name='Mid',
marker= dict(size= 9,
line= dict(awidth=1),
color= 'green',
opacity= 0.5
)
),
go.Scatter(
x=tx_graph.query("Segment == 'High-Value'")['OverallScore'],
y=tx_graph.query("Segment == 'High-Value'")['m6_Revenue'],
mode='markers',
name='High',
marker= dict(size= 11,
line= dict(awidth=1),
color= 'red',
opacity= 0.9
)
),
]
plot_layout = go.Layout(
yaxis= {'title': "6m LTV"},
xaxis= {'title': "RFM Score"},
title='LTV'
)
fig = go.Figure(data=plot_data, layout=plot_layout)
pyoff.iplot(fig)
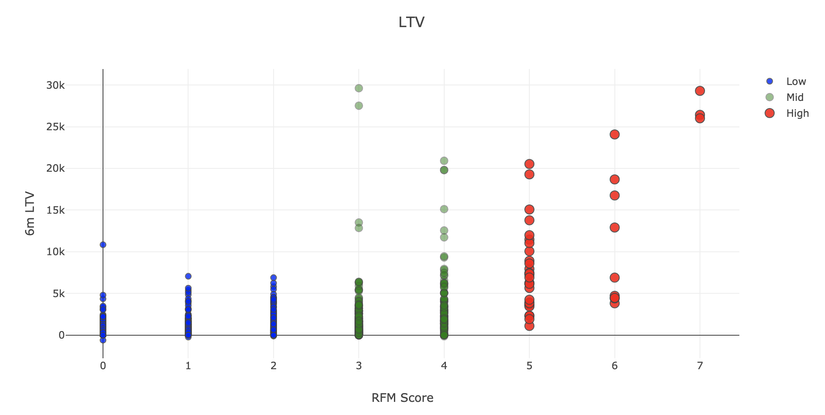
Ta thấy, điểm số RFM càng cao thì LTV càng cao.
Trước khi tiến hành xây dựng mô hình máy học, chúng ta cần phải xác định được vấn đề chúng ta cần giải quyết là gì. Một mô hình máy học có thể dự đoán được giá trị LTV, nhưng ở đây, chúng ta cần phải phân nhóm các giá trị TLV để có hành động hợp lý hơn đối với các nhóm LTV này. Bằng các áp dụng thuật toán phân nhóm gôm cụm K-means, chúng ta dễ dàng phân nhóm LTV và xây dựng phân khúc khách hàng trên đó.
Giả định rằng, toàn bộ chiến lược kinh doanh của công ty hoàn toàn dựa trên các phân tích này, chúng ta cần đối xử với từng khách hàng một cách khách nhau dựa trên dự đoán LTV của họ. Trong bài viết này, chúng ta gôm cụm và phân thành 3 phân khúc khách hàng: ( số lượng phân khúc khách hàng này phụ thuộc vào chiến lược kinh doanh của từng công ty)
- Low LTV
- Mid LTV
- High LTV
Chúng ta tiến hành phân nhóm gôm cụm khách hàng:
#remove outliers
tx_merge = tx_merge[tx_merge['m6_Revenue']<tx_merge['m6_Revenue'].quantile(0.99)]
#creating 3 clusters
kmeans = KMeans(n_clusters=3)
kmeans.fit(tx_merge[['m6_Revenue']])
tx_merge['LTVCluster'] = kmeans.predict(tx_merge[['m6_Revenue']])
#order cluster number based on LTV
tx_merge = order_cluster('LTVCluster', 'm6_Revenue',tx_merge,True)
#creatinga new cluster dataframe
tx_cluster = tx_merge.copy()
#see details of the clusters
tx_cluster.groupby('LTVCluster')['m6_Revenue'].describe()
hàm .describe() sẽ cho ta biết dữ liệu của chúng ta được phối như thế nào;
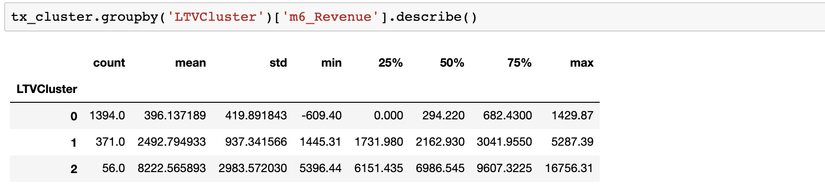
Ta thấy, cụm 2 tốt nhất với giá trị LTV trung bình là 8.2k, trong khi cụm 0 chỉ mang lại lợi nhuận trung bình là 396.
Tiếp theo, khi đã có dữ liệu đầu vào đầy đủ, chúng ta sẽ tiến hành huấn luyện mô hình máy học.
Chúng ta cần làm một số bước chuẩn bị dữ liệu trước khí huấn luyện:
- Một số cột dữ liệu cần phải chuyển về dạng số
- Kiểm ta mối tương quan, liên hệ giữa các thuộc tính với LTV
- Chia các các thuộc tính khác và LTV thành X và Y. Chúng ta sẽ dùng X để dự đoán giá trị Y.
- Tạo ra 2 tập dữ liệu là tập huấn luyện và tập kiểm thử (training và test dataset). Tập huấn luyện dùng để huấn luyện mô hình, và tập kiểm thử dùng để đánh giá mô hình.
#convert categorical columns to numerical tx_class = pd.get_dummies(tx_cluster) #calculate and show correlations corr_matrix = tx_class.corr() corr_matrix['LTVCluster'].sort_values(ascending=False) #create X and y, X will be feature set and y is the label - LTV X = tx_class.drop(['LTVCluster','m6_Revenue'],axis=1) y = tx_class['LTVCluster'] #split training and test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.05, random_state=56)
hàm .get_dummies() dùng để chuyển giá trị về 0-1. Dữ liệu sau khi chạy trước khi chạy code trên:
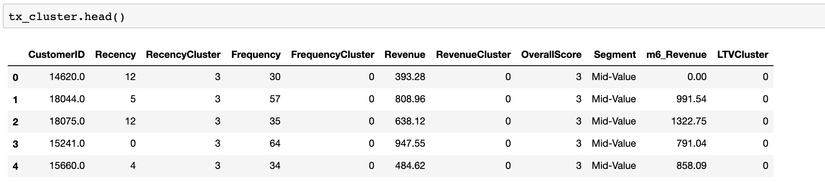
Dữ liệu sau khi chạy .get_dummies():
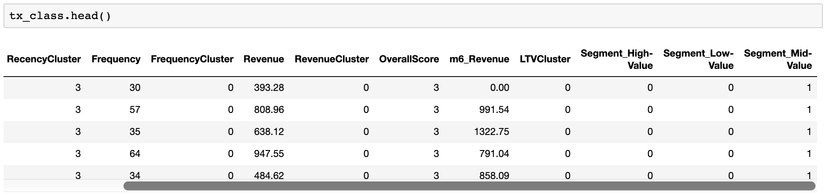
Ta thấy, cột Segment được chuyển thành 3 cột tương ứng: Segment_Hight-Value, Segment_Low-Value, và Segment_Mid-Value. Các giá trị này có giá trị 0-1 và mô hình máy học có thể sử dụng được các giá trị này, thay vì các giá trị chuỗi.
2 dòng code
#calculate and show correlations corr_matrix = tx_class.corr() corr_matrix['LTVCluster'].sort_values(ascending=False)
cho ta thấy sự tương quan của các thuộc tính với nhau
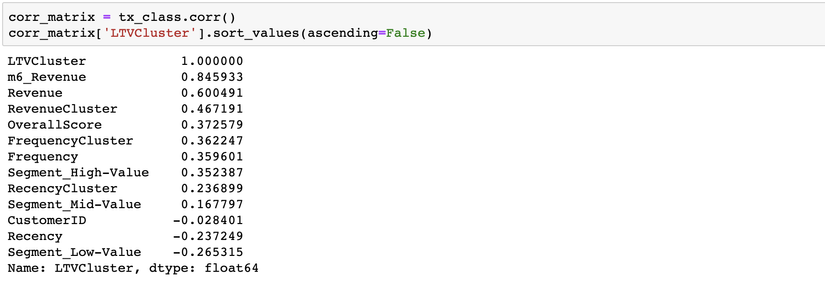
Chúng ta có thể thấy các giá 3 tháng Revenue, Frequency và điểm RFM rất thích hợp để làm đầu vào cho mô hình máy học của chúng ta.
Khi đã chuẩn bị đầy đủ dữ liệu, chúng ta có thể xây dựng được mô hình máy học:
#XGBoost Multiclassification Model
ltv_xgb_model = xgb.XGBClassifier(max_depth=5, learning_rate=0.1,objective= 'multi:softprob',n_jobs=-1).fit(X_train, y_train)
print('Accuracy of XGB classifier on training set: {:.2f}'
.format(ltv_xgb_model.score(X_train, y_train)))
print('Accuracy of XGB classifier on test set: {:.2f}'
.format(ltv_xgb_model.score(X_test[X_train.columns], y_test)))
y_pred = ltv_xgb_model.predict(X_test)
print(classification_report(y_test, y_pred))
Chúng ta dùng thuật toán XGBoost để phân loại dữ liệu thành 3 nhóm.

Độ chính xác của mô hình đạt 84% trên tập dữ liệu test. Để đánh giá được mô hình tốt hay không, chúng ta cần xem xét thêm:
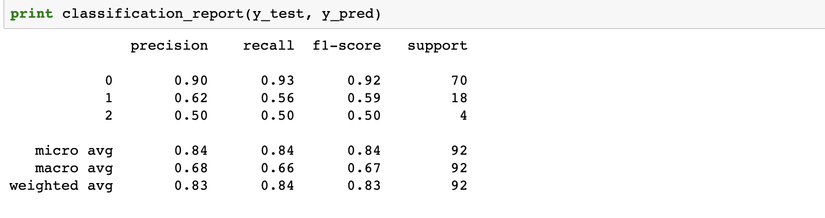
Chúng ta thấy, độ chính xác trên 3 cụm là khác nhau. Ở cụm 0, nếu mô hình dự đoán khách hàng thuộc cụm này, thì độ chính xác lên đến 90%. Còn trên các cụm khác, độ chính xác không được ổn lắm. Ví dụ cụm 3, mid LTV, chỉ đạt được 50%. Để xậy dựng mô hình dự đoán hiệu quả hơn, cần phải cải thiện thêm:
- tìm ra nhiều thuộc tính thêm đê mô hình máy học phân loại tốt hơn
- Xử dụng các thuật toán, mô hình khác
- điều chỉnh thông số chạy thuật toán
- thêm nhiều dữ liệu
Giờ chúng ta đã có mô hình máy học để dự đoán khách hàng sẽ thuộc phân nhóm LTV nào. Dựa vào đó, chúng ta sẽ có các hành động, chiến lược marketing một các phù hợp. Bài viết tiếp theo, chúng ta sẽ dự đoán một khách hàng sẽ tiếp tục sử dụng dịch vụ, sản phẩm của công ty nữa hay không, để có hành động cụ thể, nhầm tránh mất khách hàng tiềm năng của chúng ta.
