[MLE - 03] Where should we experience ?
Chào các bạn! Trong bài viết trước chúng ta đã hiểu được tầm quan trọng của "tấm bia" và "thước" trong quá trình phát triển một dự án sử dụng Machine Learning. Hôm nay chúng ta sẽ tìm hiểu về "tấm bia" này nhé ! "Tấm bia" là nơi ta thực hiện việc đo đạc performance của hệ thống, độ chính xác của ...
Chào các bạn! Trong bài viết trước chúng ta đã hiểu được tầm quan trọng của "tấm bia" và "thước" trong quá trình phát triển một dự án sử dụng Machine Learning. Hôm nay chúng ta sẽ tìm hiểu về "tấm bia" này nhé ! "Tấm bia" là nơi ta thực hiện việc đo đạc performance của hệ thống, độ chính xác của nó, tốt như thế nào, liệu mô hình có quá phức tạp hay quá đơn giản không ? Vậy nên "tấm bia" này chính là các tập dữ liệu (Chú ý rằng tập dữ liệu ở đây không phải là các tập dữ liệu khác nhau cho những bài toán khác nhau mà là các tập dữ liệu của cùng một nội dung, cùng một bài toán, cùng một vấn đề). Hãy điểm qua những tập dữ liệu điển hình trong Machine Learning.
1. Training set:
Khỏi phải giới thiệu, chỉ với cái tên của nó các bạn đã biết nó dùng cho mục đích gì. Đây là tập dữ liệu các bạn sử dụng trong quá trình training và thường xuyên được dùng để đo đếm nhiều vấn đề trong mô hình bạn đang làm. Nói cách khác, đây chính là sách vở, bài tập bạn học trong quá trình chuẩn bị cho kì thi. Nếu các bạn học chăm học và đủ trí nhớ và thông minh để học hết được những sách vở, bài tập đó thì việc thi những bài tập hay kiến thức trong đó hoàn toàn không phải là vấn đề. Khi ta đo performance của mô hình trên tập dữ liệu này, nếu độ chính xác thấp, sai số lớn thì không phải bàn cãi gì cả, bạn thực sự học "dốt". Nhưng liệu performance tốt thì bạn có "giỏi không" ? Xin trả lời bạn rằng là chúng ta không chắc ! Giả dụ như khi học bài, bạn chỉ đơn thuần ... học thuộc lòng chúng, hay nói cách khác bạn học vẹt! Với bài tập đã học, với nội dung có trong cuốn sách bạn học thuộc, bạn có thể trả lời "vanh vách" như sách vậy. Nhưng nếu như bài tập hơi khác một chút, kiến thức cần suy luận một chút, có thể bạn sẽ dễ dàng bị "bó tay". Nói một cách khác quá trình học của bạn đã trở nên quá máy móc, dập khuôn, bạn không có khả năng ứng dụng những gì mình đã học. Đây chính là vấn đề của khi mô hình của bạn quá phức tạp, chúng có thể hoàn toàn "học vẹt" toàn bộ dữ liệu của bạn mà lại không thể "hiểu" được cái "kiến thức" trong tập dữ liệu bạn cho nó, vấn đề này được gọi "Overfitting", nó trái ngược với khi bạn "học dốt" - được gọi là "Underfitting".
2. Dev set: (Validation set or Cross Validation set)
Vậy là với Training set, bạn có thể biết được mình có "học dốt" hay Underfitting hay không ? Còn bạn không thể xác định được rằng mình có học máy móc hay không hay có bị Overfitting hay không ? Đó là lý do chúng ta cần thêm một tập dữ liệu khác để xem mô hình có thực sự "học" được gì không !
Dev set là tập dữ liệu các bạn dùng để kiểm tra sai số của mô hình sau khi biết chắc nó tốt trên Training set, hay nó không bị Underfitting. Nếu như mô hình của bạn bị Overfitting, sai số trên Dev set của nó sẽ lớn. Nếu các bạn thắc mắc sai số ở đây là gì thì đó chính là thước đo của bạn, vậy nên đừng vội quan tâm tới nó ở đây.
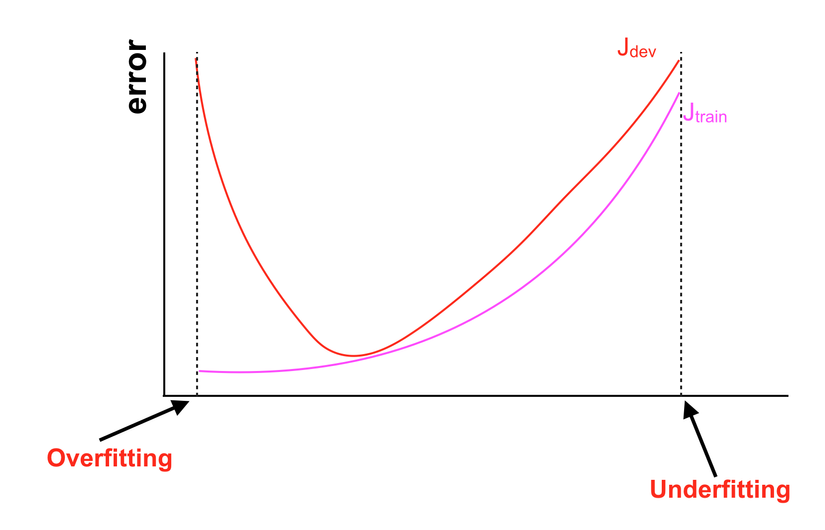 Tôi xin giải thích một chút về hình vẽ trên.
Tôi xin giải thích một chút về hình vẽ trên.
- Trục tung (Trục có kí hiệu "error") là trục thể hiện sai số của mô hình trên Training set và Dev set. Chẳng hạn như tỉ lệ đoán sai của mô hình là bao nhiêu ( = 100% - độ chính xác).
- Jtrain J_{train} Jtrain là sai số của mô hình khi dự đoán trên Training set.
- Jdev J_{dev} Jdev là sai số của mô hình khi dự đoán trên Dev set.
- Trục hoành (Trục không có kí hiệu) là trục thể hiện thay đổi của chúng ta đối với mô hình. Những thay đổi này thuộc về phạm vi của phần "Implement" nên tôi sẽ không nói rõ ở đây, chẳng hạn như chúng là việc ta thêm bớt các thành phần Regularization như weight decay, Drop-out hay việc mở rộng mô hình như tăng số lượng unit trong layer, tăng số lượng layer, hay thay đổi các hyperparameter nói chung.
- Phần nét đứt bên dưới có chữ "Overfitting" cho thấy Jtrain J_{train} Jtrain nhỏ nhưng Jdev J_{dev} Jdev lại lớn, tức là sai số trên Training set thấp nhưng trên Dev set lại cao, một dấu hiệu của "Overfitting".
- Phần nét đứt bên dưới có chữ "Underfitting" cho thấy Jtrain J_{train} Jtrain lớn và Jdev J_{dev} Jdev cũng lớn, tức là sai số trên Training set và Dev set đều cao, dấu hiệu rõ ràng của "Underfitting" Đôi khi vì Dev set nhỏ nên dẫn tới việc ta dễ dàng điều chỉnh mô hình để cho sai số trên Dev set nhỏ, trong trường hợp này có thể chỉ test trên Training set và Dev set cũng không xác định được. Tuy nhiên nếu như các bạn có Dev set đủ lớn thì chuyện này không thành vấn đề, nhưng để cho chắc chắn, tôi khuyên các bạn nên có thêm 1 tập dữ liệu nữa.
3. Test set:
Ta đã có Training set, đã có Dev set. Mặc dù chỉ Training set tham gia vào quá trình training, nhưng Dev set lại đóng vai trò quan trọng trong việc điều chỉnh mô hình, vì vậy nên ta vẫn nên có một tập dữ liệu biệt lập hoàn toàn với 2 tập trên để phục vụ mục đích kiểm tra performance thực sự của mô hình. Nếu Dev set của bạn đủ lớn, bạn có thể bỏ qua tập dữ liệu này, nhưng tôi khuyến khích các bạn nên có, vì liệu ta có biết thế nào là đủ "lớn"
