Natural Language Processing - Maximum Entropy Modeling Algorithm and Sentiment Analysis Problem
Sentiment Analysis is the process of determining whether a piece of writing is positive, negative, or neutral. It’s also known as opinion mining, deriving the opinion or attitude of a speaker. A typical use case for the technology is to discover how people feel about particular topic. ...
Sentiment Analysis is the process of determining whether a piece of writing is positive, negative, or neutral. It’s also known as opinion mining, deriving the opinion or attitude of a speaker. A typical use case for the technology is to discover how people feel about particular topic.
The Meaning of Sentiment Analysis
Research on sentiment analysis begins by identifying the words expressed the opinion: great, wonderful, good, bad. There are many studies on the identification of trends of view (good / bad) of a word, namely, web search targeted towards reviews.
- That is the assessment of the product is positive or negative;
- Is this customer email satisfied or dissatisfied?;
- Based on a sample of tweets, how are people responding to this ad campaign/product release/news item?
- ...
Businesses always want to hear from users about their products, services, after they put on the market and customers like to know the opinion of the previous user before purchasing a product or using a service. In the political field, We can apply opinion mining to have bloggers' Attitudes about the president changed since the election?
In this post I will introduce Maximum Entropy Modeling to solve Sentiment Analysis problem.
Maximum Entropy Modeling
Maximum Entropy Modeling is a text classification algorithm base on the principle of maximum entropy has strength is the ability to learn and remember millions of features from sample data.
Basic Idea
We need to calculate the probability distribution: p(a, b)
Choose p with maximum entropy (or “uncertainty”) suject to the constraints (or “evidence”)
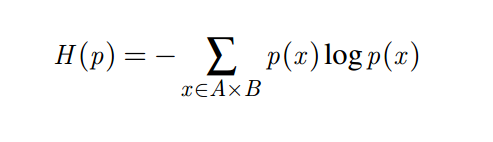
Example
Possible tagging for the word “nice” in {sent, ques, answ, spam, fact, ad}
Constraint : p(sent) + p(ques) + p(answ) + p(spam) + p(fact) + p(ad) = 1
Intuitive answers: p(sent) = p(ques) = p(answ) = p(spam) = p(fact) = p(ad) = 1/6
However if we constraint:p(sent)+p(ad) = 3/5
So Intuitive answers: p(sent) = 3/10, p(ad) = 3/10, p(answ) = 1/10, p(ques) = 1/10, p(fact) = 1/10, p(spam) = 1/10
Modeling the problem
Objective function:H(p)
Goal: Among all the distributions that satisfy the constraints, choose the one,p, that maximizes H(p).
The MaxEnt Principle
A mathematical measure of the uniformity of a conditional distribution p(y|x) is provided by the conditional entropy
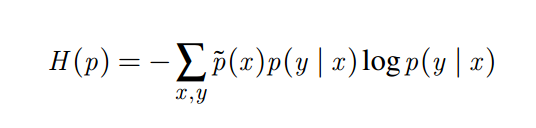
The entropy is bounded from below by zero, the entropy of a model with no uncertainty at all, and from above by log|Y|, the entropy of the uniform distribution over all possible |Y| values of y. With this definition in hand, we are ready to present the principle of maximum entropy.
MEM will calculate probability on each label of the record. The total value of this probability by 1. The new document will be on the tag which has the highest value. Label of new document is calculated by this formula:
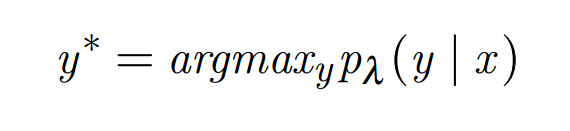
In which y* is the label corresponding to the highest probability p_{lambda} (y|x). argmax function is a maximum argument function; it returns the value of the argument (in this is y) at which the service reaches max. Obviously, the features in the new document are not in the model, that is not observed in the training data set, will get the wrong value, seen as not available, so they do not affect the probability of document on each label. The only available feature is significant decisions for the label of the document.
To solve Sentiment Analysis problem base on text classification we have two step
- Training Model
- Sentiment Classification
Training model
Suppose we have a lot of data, After performed preprocessing and built up a set of feature. I conducted training model. This step is time to apply the parameter estimation algorithm to find the set weights λlambdaλ (each feature fi will be assigned a weight λilambda_iλi ). A new document has a set of features, the set of weights will determine the degree of importance of features, and they directly affect the process of classifying the new document. Thus, system accurately predicted labels for documents.
The updated weighting step is performed according to the GIS algorithm.
-
Create weighting of feature λi(0)=0lambda_{i}(0) = 0λi(0)=0
-
Cake updates to the feature weighting formula
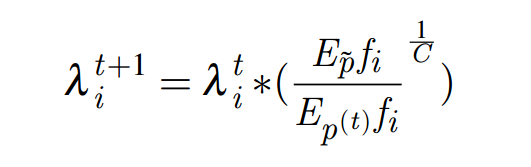
Where C is a constant. C = MAX(fi)
After each step, I calculate the total square error, a parameter expression the accuracy of the model. The total squared error will be improved gradually over the loop. Total squared error is calculated using the formula:
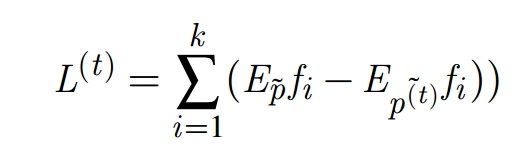
The training is repetitive process of updating the weights for the feature until I obtain an accurate model satisfies the requirements (total error reaching required)
Sentiment Classification
There are many open source software for text classification using MEM as FlexME, Maxent... I choose open source tools opennlp.maxent was originally built by Jason Baldridge, Tom Morton, and Gann Bierner. Link software: http://maxent.sourceforge.net/about.html. It is an MEM toolkit is written in Java.
Usage:
To be Continued..........
References
- Assoc. Prof. Dr. Le Anh Cuong - "Opinion Mining And Sentiment Analysis" - Summer School Machine Learning - 2015
- TienPx, ThangTQ, NhungHT - "Opinion Mining And Sentiment Analysis on Mobile Product" - Science Research Conference - 2016
- NhungHT - "Subjectivity and Polarity Classification in Sentiment Analysis" 2016
