Những dấu chân của nhân loại trên con đường đến với lập trình hướng đối tượng (phần 1)
Nguồn : http://qiita.com/hirokidaichi/items/591ad96ab12938878fe1 Người dịch : Phan Hoàng Minh Đôi điều muốn nói trước Bài viết này được tổng hợp từ những tài liệu nghiên cứu dành cho người mới lập trình. Mục đích của nó là nhằm chỉ ra phong cách lập trình mà các bạn đang sử dụng ngày ...
Nguồn : http://qiita.com/hirokidaichi/items/591ad96ab12938878fe1
Người dịch : Phan Hoàng Minh

Đôi điều muốn nói trước
Bài viết này được tổng hợp từ những tài liệu nghiên cứu dành cho người mới lập trình. Mục đích của nó là nhằm chỉ ra phong cách lập trình mà các bạn đang sử dụng ngày nay được sinh ra từ đâu, với mục tiêu nâng cao chất lượng code của các bạn chứ không nhằm mục đích giới thiệu lịch sử của ngành IT. Nếu các bạn muốn biết về lịch sử ngành IT xin hãy xem những cuốn sách có chủ đề tương tự.
Độc giả mà tôi muốn hướng đến là những người đã biết hoặc đã được học về lập trình hướng đối tượng nói chung hoặc những người đã và đang làm việc với lập trình hướng đối tượng nhưng chưa cảm thấy tự tin về hiểu biết của mình.
“Lập trình hướng đối tượng nói chung” ở trên có thể hiểu là khái niệm ở mức độ “trong các loại quả thì có táo, trong các loại động vật thì có chó mèo”.
Hành trình con người đến với khái niệm "hướng đối tượng"
Lập trình hướng đối tượng hay ngôn ngữ lập trình hướng đối tượng mà các bạn đang biết đến ngày nay là được sinh ra bởi sự thống nhất, chỉnh sửa của rất nhiều ý tưởng, cùng với đó là rất nhiều sự thử nghiệm với những chế hạn của đời thực.
Điều tôi nói sau đây có thể đương nhiên nhưng rất quan trọng đó là : lập trình hướng đối tượng hay bất cứ mẫu hình lập trình nào khác đều sinh ra từ việc con người tìm kiếm phương pháp hệ thống hóa cách giải quyết những vấn đề phát sinh trong việc dùng chương trình máy tính để tái hiện thế giới thật.
Tôi cũng vậy mà nhiều người khác cũng vậy, viết một chương trình theo kiểu lập trình hướng đối tượng đã trở thành việc đương nhiên. Cứ như vậy, chúng ta sẽ quên đi nguồn gốc của nó nên tôi muốn ôn lại thông qua một số mốc lịch sử cơ bản.
Software crisis
Những năm cuối của thập niên 1960 (lúc ấy tôi chưa sinh ra nên có thể cũng không hiểu rõ), cùng với sự phát triển của máy tính, người ta bắt đầu đòi hỏi việc lập trình phải trở nên phức tạp hơn nhưng những công cụ, những ý tưởng phục vụ cho việc quản lí, điều khiển sự phức tạp đó thì lại chưa nhiều.
(Không phải là không có nhưng thời nào cũng vậy, cái mà người ta hay dùng cho project là cái có sức ảnh hưởng lớn hơn chứ không phải là cái tiến bộ hơn).
https://en.wikipedia.org/wiki/Software_crisis
Nếu project trở nên phức tạp hơn trong khi phương pháp quản lí không thay đổi thì dạng dữ liệu sẽ chỉ toàn chữ số cơ bản, biến số sẽ đồng nghĩa với việc phân vùng bộ nhớ.
Mặt khác, hồi đó thứ tự chạy của chương trình hay được quy định bằng những thứ dùng số đếm để điều khiển và có tính trừu tượng thấp như lệnh goto và jump. Nếu diễn giải chương trình ra dưới dạng flow chart sau đó chuyển thể nó thành ngôn ngữ máy tính thì cách làm như vậy có thể là đúng.
Dù thế nào đi nữa, dưới con mắt của người thời đó thì lập trình đang đi dần vào ngõ cụt còn người thời nay nhìn lại thì thấy đó là giai đoạn khái niệm lập trình cấu trúc đang dần được hình thành.
Lập trình cấu trúc
Dijkstra là một trong những, nếu không muốn nói là lập trình viên nổi tiếng nhất trên thế giới - người thậm chí không cần có riêng một cái máy tính mà có thói quen dùng bút và giấy để suy nghĩ. Việc ông đề xướng kĩ thuật lập trình cấu trúc cũng là một động thái rất nổi tiếng.
Đôi khi người ta vẫn hay nhầm lẫn nhưng lập trình cấu trúc không phải là “lập trình thủ tục” cũng không phải là “lập trình không sử dụng lệnh goto”.
Lập trình cấu trúc nghĩa là gì?
“Trong lập trình cấu trúc, ta không đơn thuần sử dụng trực tiếp những câu lệnh của ngôn ngữ lập trình để viết nên một chương trình. Thay vào đó, ta xem như chương trình đã được trừu tượng hóa thành những câu lệnh và tưởng tượng ra có một cái máy mang những câu lệnh đó, và ta sẽ lập trình trên chính cái máy đó. Thông thường, trừu tượng hóa thường có nhiều tầng chứ không phải một tầng. Những gì ta làm ở tầng này sẽ cách li với tầng khác, những gì ta thay đổi sẽ chỉ ảnh hưởng trong chỉ phạm vi tầng mà ta đang làm (abstract data structures). Các tầng sẽ được lắp vào móng của ứng dụng theo các phương hướng cũng có tính chất trừu tượng, một cách có thứ tự. Thứ tự này không nhất thiết phải giống hệt với thứ tự ta bắt đầu thiết kế tầng nào trước, tầng nào sau.”
https://en.wikipedia.org/wiki/Structured_programming
Chiếu theo cách nói bây giờ, có thể hiểu nó có nghĩa là “layering architecture” – trên một cái móng đặt thêm một cái móng trừu tượng, trên cái móng đó lại đặt thêm một cái móng nữa... Cứ thế chúng ta “xây” nên một chương trình.
Đây là cách suy nghĩ đương nhiên đối với ngành lập trình đương đại.
Cũng vì lẽ đó, chúng ta thường tránh việc đặt chung những lớp trừu tượng khác nhau trong cùng một architecture (hay nói cách khác, một hàm số).
Mặt khác, thời điểm đó thuyết phê phán lệnh goto, cùng với thuyết cấu trúc (bất cứ flow chart nào cũng có thể biểu diễn bằng lệnh if và lệnh for) được rất nhiều người chú ý, chính là những yếu tố thúc đẩy Lập trình thủ tục trở thành Lập trình đương đại.
Dijkstra đã không định nghĩa được triệt để điều ông muốn nói và ông cũng không đăng kí bản quyền cho những khái niệm đó, nên việc sau này những công ty khác sử dụng rộng rãi những gì ông phát biểu khiến ông rất hối hận. Ông thậm chí còn tránh nhắc đến cụm từ “Lập trình cấu trúc”.
Lí do bởi vì ông sợ người ta sẽ sử dụng rộng rãi cụm từ đó mà không thật sự hiểu về nó, việc đó cho đến ngày nay cũng vẫn thường xảy ra.
Cái tên “lập trình hướng đối tượng” cũng như vậy, chính người đặt ra cái tên đó về sau đã nói rằng đó là một thất bại. Điều này rất thú vị và tôi xin được nói ở phần sau.
Modular programming
Dưới những bối cảnh như đã nói ở trên, ngành lập trình trở nên phức tạp hơn một cách liên tục.
Tôi sẽ phân tích quá trình đó bằng một lối tư duy gần với tự nhiên nhất.
Cohesion và coupling
Ngày đó, chưa có một phương châm tổng quát nào cho việc chia các module. Kể cả ngày nay, nếu thực sự muốn, chúng ta vẫn có thể đưa các chức năng hoàn toàn không liên quan đến nhau vào cùng một module.
Tùy vào trình độ của lập trình viên mà chất lượng module tạo ra sẽ khác nhau.
Thước đo của chất lượng đó chính là cohesion và coupling - những khái niệm được hậu thế sinh ra. So với lập trình hướng đối tượng thì chúng được phát minh ra sau, đồng thời chúng không phải là những khái niệm của riêng lập trình hướng đối tượng nên tôi xin được giới thiệu chúng luôn dưới đây.
Cohesion : thế nào là một tập hợp chức năng tốt và không tốt? https://en.wikipedia.org/wiki/Cohesion_(computer_science)
Coupling : thế nào là sự liên quan tốt và không tốt giữa các module? https://en.wikipedia.org/wiki/Coupling_(computer_programming)
2 đường dẫn ở trên cũng chỉ rõ làm thế nào để thực hiện việc “phân chia mối quan tâm”. https://en.wikipedia.org/wiki/Separation_of_concerns
“Mối quan tâm” có thể diễn đạt bằng từ ngữ khác như “trách nhiệm” hay “chức vụ” của một module.
Sự tương đồng giữa một module và trách nhiệm của module đó sẽ khiến cho cohesion tăng, coupling giảm.
Chúng ta sẽ cùng xem những ví dụ cụ thể để hiểu rõ hơn việc phân chia “trách nhiệm” và “chức vụ” là như thế nào.
Good coupling, bad coupling
Bad coupling biểu hiện ở việc cứ thế sử dụng data bên trong một module vốn đang được phụ thuộc bởi một module khác (content coupling), hoặc việc cùng tham chiếu một biến số global (common coupling).
Bad coupling sẽ dẫn đến việc một module không còn tính độc lập nữa. Sửa một bên, bên còn lại sẽ phải sửa theo, hoặc một xử lí không mong muốn sẽ miễn cưỡng sinh ra.
Ngược lại, good coupling lại giống như việc ta gửi và nhận những dữ liệu đã định dạng sẵn (data coupling), hoặc gửi message (message coupling) – không phụ thuộc vào thành phần bên trong, việc trao đổi thông tin được xác định rõ ràng.
Khái niệm này không khác nào encapsulation và message parsing! - nếu bạn nghĩ vậy thì bạn đã đúng.
Bởi vì sao? Vì lập trình hướng đối tượng được sinh ra với mục đích phục vụ cho việc hình thành good coupling.
Good cohesion, bad cohesion
Độ cohesion thấp, hay bad cohesion có nghĩa là như thế nào?
Một module tập hợp toàn những xử lí random là một module không tốt. Một tập hợp của những gì không có căn cứ rõ ràng (coincidence cohesion) là một tập hợp không tốt. Có thể nói dễ hiểu là như vậy.
Tuy nhiên, nếu chỉ hoàn toàn dựa vào việc có liên quan đến nhau về mặt logic để tập hợp mọi thứ lại cũng là việc không tốt.
Diễn giải cụ thể hơn cho điều trên là như thế nào? Chẳng hạn, chúng ta xem ví dụ dưới đây:
function open(type,name){
switch(type){
case "json": ... break;
case "yaml": ... break;
case "csv" : ... break;
case "txt" : ... break;
:
}
return result;
}
Cho dù đây là xử lí về đầu ra đầu vào đi nữa, các bạn hãy thử tưởng tượng xem nếu đối với từng hàm open ta đều đưa một lượng lớn câu lệnh if và switch vào như trên thì sẽ ra sao?
(Bản thân việc muốn đưa những gì liên quan về mặt logic vào trong cùng một chỗ là cách suy nghĩ không tồi. Tuy nhiên, làm như vậy sẽ khiến cho những dữ liệu quan trọng khác bị ảnh hưởng nghiêm trọng. Thứ giải quyết nghịch lí đó chính là polymorphism (cấu trúc đa hình) – phân chia tác dụng của các method cùng tên tùy theo đối tượng là gì).
Chúng ta có thể dễ dàng hình dung việc maintenance sẽ trở nên vất vả như thế nào với cách làm trên.
Nhưng lại có ý kiến cho rằng : làm như vậy sẽ giúp tất cả xử lí có thể chạy cùng một lúc. Biết là vậy, nhưng cũng không nên đánh đổi điều đó với công sức chia module – một việc vốn sẽ trở nên rất khó khăn nếu ta làm theo kiểu cohesion tạm bợ (temporal cohesion) như trên. Bạn hãy thử tưởng tượng xem nếu ta khởi tạo tất cả dữ liệu trong hàm init thì có tốt không? Trường hợp này cũng hao hao giống vậy.
Vậy, good cohesion là gì?
- Communication cohesion : tập hợp những xử lí truy cập vào cùng một dữ liệu, hoặc
- Information cohesion : tập hợp những dữ liệu, thuật toán và khái niệm tương đồng với nhau và hơn hết đó là
- Functional cohesion : tập hợp những gì cần thiết để giải quyết một nhiệm vụ được định nghĩa rõ ràng.
Đó chính là những good cohesion.
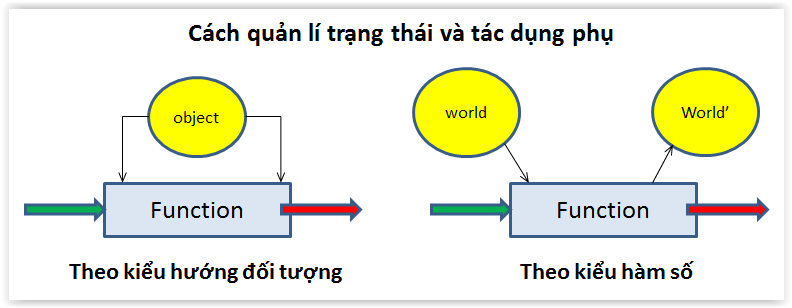
Quản lí trạng thái và tác dụng phụ
Sau khi xem xét cohesion và coupling, chúng ta có thể lờ mờ hiểu ra thế nào là “cách chia module” tốt. Đó là sự tường minh trong việc quản lí những xử lí, đi kèm với những dữ liệu liên quan đến chúng.
Nếu có thể, việc ẩn đi sự tồn tại của toàn bộ dữ liệu là lí tưởng nhất. Tuy nhiên, thực tế thì nhiều trường hợp chúng ta khó mà làm được như vậy. Cái khó đó sinh ra bởi 2 yếu tố : trạng thái (status) và tác dụng phụ (side effect). Một ví dụ :
function add(a,b){
return a+b;
}
Một hàm số không có tác dụng phụ như trên có thể test rất dễ dàng, đồng thời không có kẽ hở nào cho bug phát sinh. Tuy nhiên, khi chúng ta ứng dụng hàm trên vào việc thanh toán hóa đơn chẳng hạn :
var r = 0;
function add(a,b){
r = a+ (isUndefined(b)||r)
return r
}
thì bạn có thể thấy những gì chúng ta cần phải xem xét đã tăng lên.
Ta có thể chia hàm số thành các loại khác nhau, dựa trên đặc tính trạng thái và tác dụng phụ của chúng như dưới đây.

Cho tới ngày đạt đến mốc lập trình hướng đối tượng, ngành lập trình đã đối phó với trạng thái và tác dụng phụ bằng cách tích cực thực hiện việc naming, visualization, loose coupling - tìm kiếm sự “phân chia mối quan tâm”.
Ngày nay trong những project làm bằng ngôn ngữ C, những hàm số với các tham số truyền vào là các object composition được chia thành các module, và trở thành một phần của những công trình to lớn.
Object composition & Function set
typedef struct {
:
} Person;
void person_init(person*p,...){
:
}
char * person_get_name(person *p){
:
}
void person_set_name(person *p,char *name){
:
}
Sẽ rất thú vị nếu chúng ta lí giải theo hướng lập trình chia ra làm 2 kiểu :
- _Functional programming (lập trình kiểu hàm số) _– phát triển, mở rộng nhưng luôn cố gắng không đánh mất tính thuần khiết của hàm số.
- _Procedural programming (lập trình thủ tục) _– lấy trạng thái, tác dụng phụ làm trung tâm với vai trò là dữ liệu.
Kiểu dữ liệu trừu tượng
Ở trên chúng ta đã nói : một module tốt nghĩa là trạng thái và tác dụng phụ bị ẩn đi, đồng thời tập hợp được dữ liệu và thuật toán lại cùng một chỗ.
Một khái niệm đã được sinh ra nhằm hỗ trợ cho luận điểm trên về mặt từ ngữ, đó là khái niệm “kiểu dữ liệu trừu tượng”.
Kiểu dữ liệu trừu tượng ở thời đại của chúng ta chính là class. Hay nói cách khác đó là kiểu dữ liệu mà dữ liệu, cùng với những xử lí liên quan đến chúng được tập trung lại cùng một chỗ.
Nói đến đây, chúng ta đang đến rất gần với lập trình hướng đối tượng rồi.
Có một vấn đề chưa giải quyết được trong thuyết Lập trình cấu trúc của Djikstra : làm thế nào để trừu tượng hóa việc xử lí dữ liệu?
Mặt khác, kiểu dữ liệu và phân vùng bộ nhớ là 2 chuyện khác nhau, nên cho dù ta có khai báo biến số thêm một lần nữa thì dữ liệu cũng không được dùng chung. Việc chia một kiểu dữ liệu vào một vùng bộ nhớ có tồn tại được gọi là thể hiện hóa (instantiation).
Cụ thể hơn, chúng ta xem lại ví dụ vừa nãy :
people.h
typedef struct {
//Công khai nội dung bên trong
} people;
void people_init(people *p,...);
char * people_get_name(people *p);
void people_set_name(people *p,char *name);
Theo cách làm trên, nội dung bên trong được public nên sẽ có thể bị truy cập trực tiếp bằng cách dưới đây.
people user;
user.age = 10;
printf("%d years old",user.age);
Vì thế trong ngôn ngữ C, chúng ta có thể dùng thủ thuật sau
person.h Công khai phần này typedef struct sPerson person; void person_init(person *p,...); char * person_get_name(person *p); void person_set_name(person *p,char *name);
people_private.h Phần này sử dụng bên trong module
#include "person.h";
struct sPerson {
// Nội dung bên trong
};
//Hàm số không công khai
_person_private(person *p,....);
để tách rời header công khai và header không công khai. Bằng cách đó chúng ta đã ẩn dữ liệu đi, hay đồng nghĩa với việc ta đã tạo nên dữ liệu trừu trượng.
(Xem tiếp phần 2)
