Optical Character Recognition (OCR) – Nhận diện ký tự từ ảnh
Bài viết được sự cho phép của tác giả Nguyen Duy Hien Trong ví dụ này mình sẽ có input là một tấm ảnh chụp từ màn hình mobile, kết quả output mong muốn sẽ là nội dung chữ trên bức ảnh đó và kiểm tra lại để đảm bảo trên ảnh có chứa những nội dung chữ mình mong muốn. Trải nghiệm công nghệ ...
Bài viết được sự cho phép của tác giả Nguyen Duy Hien
Trong ví dụ này mình sẽ có input là một tấm ảnh chụp từ màn hình mobile, kết quả output mong muốn sẽ là nội dung chữ trên bức ảnh đó và kiểm tra lại để đảm bảo trên ảnh có chứa những nội dung chữ mình mong muốn.
Optical character recognition (also optical character reader, OCR) is the mechanical or electronic conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene-photo (for example the text on signs and billboards in a landscape photo) or from subtitle text superimposed on an image.

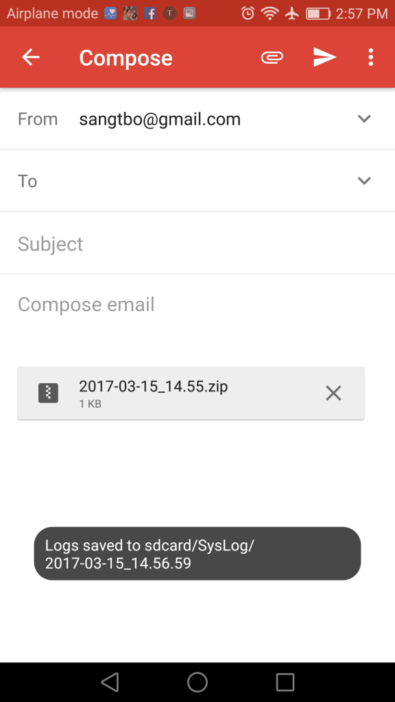

OCR Input (PNG file): Screenshot_2017-03-15-14-57-02.png
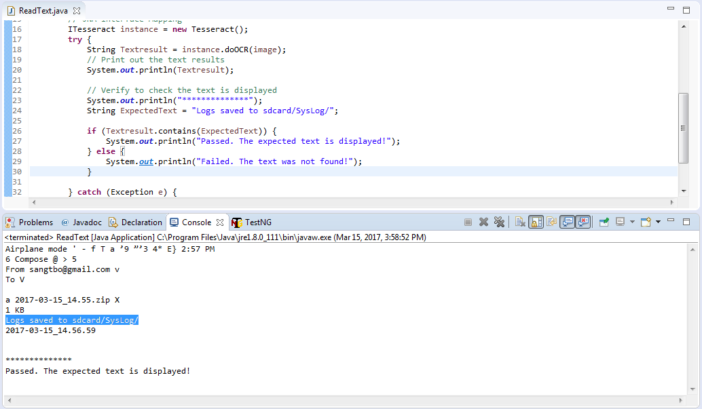
OCR Output (text): The text “Logs saved to sdcard/SysLog/2017-03-15_14.56.59”
Các bước thực hiện:
1. Bạn có thể tạo một project mới hoặc tải project mẫu mình đã upload tại đây.
2. Import thư viện Tess4J và các thư viên liên quan (có thể import hết thư viện trong thư mục “tesslibs” mình để trong project).
3. Đặt thư mục “tessdata” (data dùng để nhận diện ký tự) và hình ảnh cần test ra thư mục root, sau này bạn có thể thay đổi đường dẫn đến hình ảnh cũng được.
Sau khi có đủ thư viện, đặt thư mục tessdata và hình ảnh input đúng vị trí, chúng ta tạo một class mới để bắt đầu. Đây là một đoạn code ngắn để thực hiện những yêu cầu ban đầu:
1. Đọc chữ từ screenshot.
2. In tất cả các chữ có trên ảnh ra.
3. Kiểm tra những chữ đã xuất ra được có chứa các nội dung mình cần hay không.
package Tess4J;
import java.io.File;import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;public class ReadText {
public static void main(String[] args) {
// Set the image source path
String imagePath = “Screenshot_2017-03-15-14-57-02.png”;File image = new File(imagePath);
// JNA Interface Mapping
ITesseract instance = new Tesseract();
try {
String Textresult = instance.doOCR(image);
// Print out the text results
System.out.println(Textresult);// Verify to check the text is displayed
System.out.println(“**************”);
String ExpectedText = “Logs saved to sdcard/SysLog/”;if (Textresult.contains(ExpectedText)) {
System.out.println(“Passed. The expected text is displayed!”);
} else {
System.out.println(“Failed. The text was not found!”);
}} catch (Exception e) {
System.out.println(“Failed. Could not read the text from image file!”);
}
}
}
Nội dung chúng ta có được:
Cách này khá hữu ích khi làm automation, đôi lúc có những thành phần không thể getText do không lấy được locators, dùng cách này thì chúng ta sẽ không cần locators, ngoài ra còn ứng dụng trong các trường hợp khác như đọc nội dung PDF, tài liệu scanned. Các bạn thử nhé!
Bài viết gốc được đăng tải tại vntesters.com
Có thể bạn quan tâm:
- Viết hệ thống nhận diện gương mặt bằng face-api-js
- Công nghệ trong ngành Bảo hiểm InsurTech: Góc nhìn từ Phó Tổng Giám Đốc Công Nghệ Thông Tin AIA Việt Nam
- Debug và khắc phục lỗi hiển thị ký tự Unicode của ứng dụng Web
Xem thêm Việc làm Developer hấp dẫn trên TopDev

