Phần 3: Deep Learning cho Chatbot - Thiết kế generative Chatbot
Mở đầu Ở bài trước chúng ta đã tạo ra một retrieval based Chatbot. Lúc đó mình còn phân vân liệu cái encoder-decoder, seq2seq translate này có phải là retrieval based model hay không. Vì mục đích của mình ban đầu là làm sao cho nó map đúng các câu hội thoại là được. Mình muốn nhắc lại cho các chưa ...
Mở đầu
Ở bài trước chúng ta đã tạo ra một retrieval based Chatbot. Lúc đó mình còn phân vân liệu cái encoder-decoder, seq2seq translate này có phải là retrieval based model hay không. Vì mục đích của mình ban đầu là làm sao cho nó map đúng các câu hội thoại là được. Mình muốn nhắc lại cho các chưa xem các bài viết trước. Retrieval based sẽ đánh giá các câu trả lời có tiềm năng và chọn ra câu tốt nhất để trả lời, không từ mới, không câu mới. Generative model tự sinh ra câu trả lời dựa trên câu yêu cầu. Và mình cũng tìm kiếm các cách tạo ra một generative model nhưng đa phần các bài viết đều nói về mô hình encoder-decoder như mình làm. Cũng có thể gọi là generative vì các câu trả lời được sinh ra đúng theo nghĩa đen tuy rằng nó tối nghĩa. Có nghĩa là chúng ta đang đi đúng hướng. Dẫu chatbot được tạo nó chẳng thông minh tẹo nào, nhưng cũng đươc coi là generative model. Và nó có tệ thế nào đi chăng nữa thì ít nhất chúng ta cũng đã thử. Sự lựa chọn tồi tạo nên những câu chuyện đẹp.Chatbots với Seq2Seq
Khi Telegram released bot API, cung cấp một cách dễ dàng cho các developers, để tạo ra bots bằng cách tương tác với Bot Father. Ngay lập tức mọi người bắt đầu tạo ra các abstractions (thư viện) cho nodejs, ruby và python, để tạo bot. Chúng ta (Cộng đồng phần mềm tự do) đã tạo ra một nhóm cho việc tương tác với các bot chúng ta đã tạo được. Tôi đã tạo bằng nodejs có thể trả lời bất kỳ truy vấn để trong dấu nháy (dấu nháy ở đây chắc để đánh dấu cho câu cần truy vấn). Chương trình sử dụng linux utility fortune, một pseudorandom message generator. Nó thật ngu ngốc. Nhưng rất vui khi nhìn thấy moi người sẵn sàng tương tác với một chương trình, cái mà đã được tạo ra. Một số người tạo ra Hodor bot. Bạn có thể hình dùng được cái mà nó sẽ làm. Sau khi tôi đã gặp các con bot khác nhau, Mitsuku cái mà khá thông minh. Nó được viết bằng AIML (Artificial Intelligence Markup Language), một ngôn ngữ dạng XML cho phép lập trình viên viết các luật cho bot. Về cơ bản, bạn viết một PATTERN và một TEMPLATE, giống như khi bot nhận được câu khớp với pattern từ người dùng, nó sẽ trả lời với một templates. Chúng ta gọi loại model này là Rule based model. Mô hình dựa theo luật.Rule based model là cách dễ dàng cho bất kỳ ai có thể tạo ra được bot. Nhưng nó là vô cùng khó khăn khi tạo ra một bot có câu trả lời phức tạp. Pattern sẽ khớp với các kiểu đơn giản và kể từ đó AIML sẽ khó khăn khi chúng gặp phải những câu chưa được định nghĩa. Và nó cũng mất nhiều thời gian và công sức để viết các luật bằng tay. Nếu chúng ta có thể tạo ra một bot có thể học từ các cuộc hội thoại giữa con người. Đây là nơi mà Machine Learning có đất dụng võ.
Chúng ta sẽ cho model tự học từ data, một model thông minh, Intelligent models có thể chia làm hai loại:
- Retrieval-based models
- Generative models
Đọc Deep Learning For Chatbots bởi Denny Britz, anh ta nói về length of conversations, open vs closed domain, các thử thách trong generative model như ngữ cảnh, tính cá nhân, hiểu được ý định của người dùng và làm thế nào để đánh giá được model. Chính là các bài viết trước mình đã dịch các bạn có thể tìm đọc lại.
Seq2Seq
Sequence To Sequence model giới thiệu trong Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation sau đó trở thành model cho Dialogue System (Chatbot) và Machine Translation. Nó bao gồm hai RNNs (Recurrent Neural Network): Một Encoder và một Decoder. Encoder lấy một chuỗi (câu) làm input và xử lý các ký tự (các từ) trong mỗi lần. Nhiệm vụ của nó là chuyển một từ thành các vector có cùng kích cỡ, chỉ bao gồm các thông tin cần thiết và bỏ đi các thông tin cần thiết (có vẻ việc này được thực hiện tự động trong quá trình train). Bạn có thể xem flow.
Hình ảnh được mượn từ farizrahman4u/seq2seq
Mỗi hidden state (Một LSTM - một hình vuông trên ảnh đầu vào sẽ là một từ và một hidden state, đầu ra là hidden state và truyền qua LSTM cell tiếp theo) ảnh hưởng tới hidden state tiếp theo và hidden state cuối cùng có thể được nhìn thấy như là tổng kết của chuỗi. State này được gọi là context hoặc thought vector. Từ context (nghĩa là hidden state cuối cùng), the decoder sẽ tạo ra sequence (là câu trả lời được tạo ra), mỗi một từ một lần. Ở mỗi bước decoder sẽ bị ảnh hưởng bởi từ được tạo ra ở bước trước.

Hình ảnh được mượn từ Deep Learning for Chatbots : Part 1
Có một vài thử thách khi sử dụng model này. Cái mà phiền nhất là model không thể tự xử lý được chiều dài của câu văn. Nó là một điều phiền phức bởi hầu hết cho các ứng dụng seq2seq. Decoder dùng softmax cho toàn bộ từ vựng, lặp lại với mỗi từ của output. Điều này sẽ làm chậm quá trình train, mặc dù nếu phần cứng của bạn có khả năng xử lý được nó. Việc biểu diễn các từ là rất quan trọng. Bạn biểu diễn từ như thế nào? Sử dụng one-hot vector nghĩa là phải xử lý với vector lớn và one-hot vector không có ý nghĩa cho từ. Chúng ta sẽ phải đối mặt với các thử thách trên, từng cái một.
Padding
Trước train, chúng ta sẽ nhìn vào tập dữ liệu để chuyển chiều dài của các câu cho nó giống nhau bằng cách padding. Chúng ta sẽ sử dụng một vài ký tự đặc biệt để thêm vào câu.- EOS: End of sentence
- PAD: Filler
- GO: Start decoding
- UNK: Từ không có trong từ điển
Q : How are you? A : I am fine.
Bucketing
Giới thiệu padding đã giải quyết được vấn đề chiều dài của câu. nhưng trường hợp câu quá dài. Nếu câu dài nhất trong dữ liệu là 100, chúng ta encoder tất cả các câu của chúng ta với chiều dài 100, trường hợp này không mất bất kỳ từ nào. Bây giờ, chuyện gì sẽ xảy ra với từ "How are you?" ? Chúng ta có 97 PAD trong encoderd. Điều này sẽ làm mờ đi thông tin thật của cả câu("How are you").Bucketing giải quyết được vấn đề này, bằng cách đặt các câu trong các bucket khác kích cỡ. Cân nhắc danh sách sau: [(5, 10), (10, 15), (20, 25), (40, 50)]. Nếu chiều dài câu query là 4 và câu response là 4 chúng ta sẽ đặt vào bucket (5, 10). Query sẽ padded tới 5 ký từ và kết quả là 10. Trong khi run model (khi train và dự đoán), chúng ta sẽ sử dụng một model khác cho mỗi bucket, tương thích với chiều dài của query và response. Tất cả các model sẽ cùng parameter và ví thể function sẽ hoàn toàn giống nhau
Nếu chúng ta sử dụng bucket (5, 10). các câu của chúng ta sẽ được encoded như sau:
Q : [ PAD, “?”, “you”, “are”, “How” ] A : [ GO, “I”, “am”, “fine”, “.”, EOS, PAD, PAD, PAD, PAD ]
Word Embedding
Word Embedding là kĩ thuật cho việc biểu diễn các từ một không gian vector có số chiều thấp. Mỗi từ có thể được nhìn thấy như một điểm trong không gian này, biểu diễn bởi chiều dài cố định. Ngữ nghĩa liên quan giữa các từ cũng được lưu giữ bởi kĩ thuật này. Word vectors có những thuộc tính thú vị:paris – france + poland = warsaw
khoảng cách giữa paris - france = warsaw - poland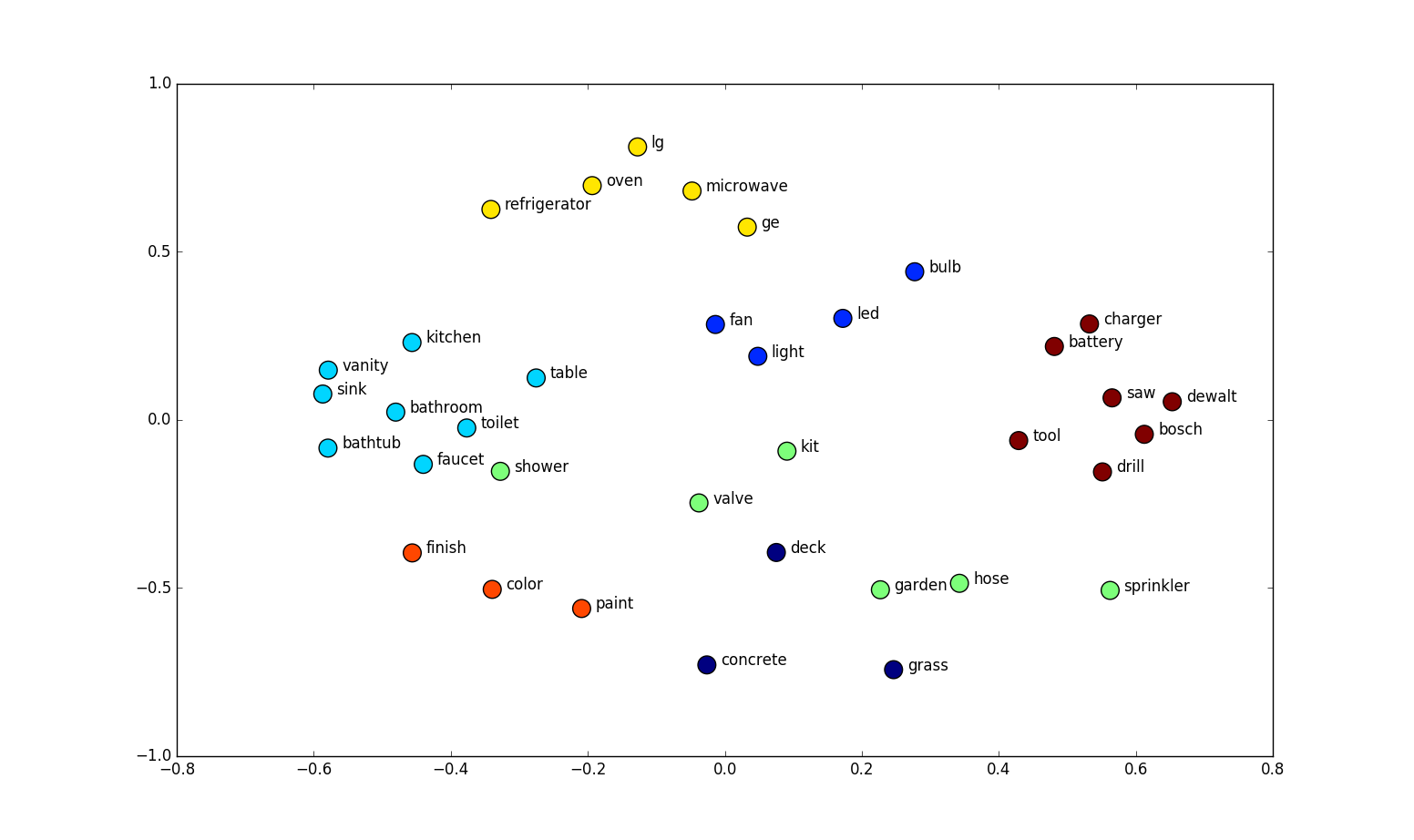
Hình ảnh được mượn từ Home Depot Product Search Relevance, Winners’ Interview
Word embedding là thường là lớp đầu tiên của mạng: Embedding layer map 1 từ trong từ điển tới một vector cho sẵn kích thước. Trong seq2seq model trọng số của embedding layer được train cùng với các tham số khác của model. Theo chân tutorial này bởi Sebastian Ruder để học về các model kahsc sử dụng word embedding và tầm quan trọng của nó trong NLP. (ok mình thì dùng một word embedding đã được trên từ trước và mình không thay đổi nó, mình không rõ như bên trên có cải thiện nhiều không, chẳng còn cách nào khác chỉ có thể thử thôi
