Query Optimization in MySQL (continue)
Trong bài này chúng ta sẽ tìm hiểu về Query Execution Plan và Measuring Performance trong MySql Query Execution Plan Tập hợp các hoạt động mà bộ tối ưu hóa lựa chọn để thực hiện các truy vấn hiệu quả nhất được gọi là "kế hoạch thực hiện truy vấn". Tùy thuộc vào các chi tiết của các bảng, cột, ...
Trong bài này chúng ta sẽ tìm hiểu về Query Execution Plan và Measuring Performance trong MySql
Query Execution Plan
Tập hợp các hoạt động mà bộ tối ưu hóa lựa chọn để thực hiện các truy vấn hiệu quả nhất được gọi là "kế hoạch thực hiện truy vấn". Tùy thuộc vào các chi tiết của các bảng, cột, index của bạn, và các điều kiện trong mệnh đề WHERE của bạn, các bộ tối ưu hóa MySQL xem xét nhiều kỹ thuật để thực hiện hiệu quả các tra cứu liên quan đến một truy vấn SQL. Gồm có:
- Một truy vấn trên một bảng lớn có thể được thực hiện mà không đọc tất cả các hàng;
- Một phép join gồm một số bảng có thể được thực hiện mà không cần so sánh mọi sự kết hợp của các hàng.
Chúng ta có một công cụ hữu ích cho công việc tối ưu hóa truy vấn, đó là lệnh EXPLAIN. EXPLAIN SELECT select_options.
MySQL hiển thị thông tin từ các bộ tối ưu hóa về cách bảng được kết nối như thế nào và theo thứ tự nào, để đưa ra một gợi ý để bộ tối ưu hóa sử dụng một thứ tự join tương ứng với thứ tự mà các bảng được đặt tên trong câu lệnh SELECT, bắt đầu câu lệnh với SELECT STRAIGHT_JOIN thay vì chỉ SELECT. Bạn có thể nhìn thấy nơi mà bạn nên thêm các index vào các bảng để câu lệnh thực hiện nhanh hơn.
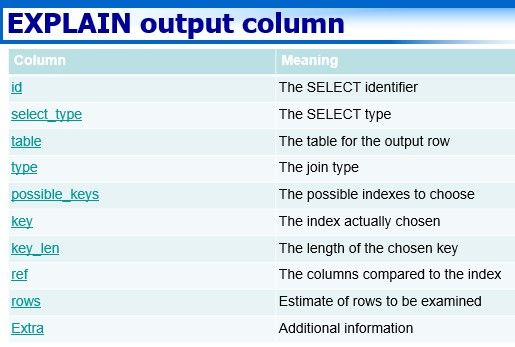
Định dạng đầu ra câu lệnh EXPLAIN
EXPLAIN trả về một hàng gồm thông tin cho mỗi bảng được sử dụng trong câu lệnh SELECT. Trong output, các bảng được liệt kê theo thứ tự mà MySQL sẽ đọc chúng trong khi xử lý truy vấn. MySQL giải quyết tất cả phép join sử dụng phương thức nested-loop join. Điều này có nghĩa rằng MySQL đọc một hàng từ bảng đầu tiên, và sau đó tìm thấy một dòng tương ứng trong bảng thứ hai, bảng thứ ba, và tiếp tục như vậy. Khi tất cả các bảng đã được xử lý, MySQL đưa ra các cột được chọn và quay lại qua danh sách bảng cho đến khi một bảng được tìm thấy ở đó có nhiều hàng phù hợp hơn. Các hàng tiếp theo được đọc từ bảng này và tiến trình tiếp tục với bảng bên cạnh.
select_type:
- SIMPLE: SELECT đơn giản (không sử dụng UNION hoặc truy vấn con)
- PRIMARY: SELECT ngoài cùng nhất
- UNION: SELECT thứ hai hoặc sau đó trong một UNION
- DEPENDENT UNION: SELECT thứ hai hoặc sau đó trong một UNION, phụ thuộc vào truy vấn bên ngoài
- UNION RESULT: Kết quả của một UNION.
- SUBQUERY: SELECT đầu tiên trong subquery.
- DEPENDENT SUBQUERY: SELECT đầu tiên trong subquery, phụ thuộc vào truy vấn bên ngoài.
- DERIVED: bảng nguồn SELECT (subquery trong mệnh đề FROM).
- UNCACHEABLE SUBQUERY: Một truy vấn con mà kết quả không thể được lưu trữ và phải được đánh giá lại cho mỗi hàng của các truy vấn bên ngoài.
- UNCACHEABLE UNION: SELECT thứ hai hoặc sau đó trong một UNION thuộc về một uncacheable.
Type: Danh sách sau đây mô tả các loại join, sắp xếp từ loại tốt nhất đến xấu nhất:
- ALL: Một bảng quét đầy đủ được thực hiện cho mỗi sự kết hợp của các hàng từ các bảng trước đó.
- SYSTEM: Bảng này có chỉ có một hàng (= bảng hệ thống). Đây là một trường hợp đặc biệt của const join.
- CONST: Bảng này có nhiều nhất một hàng phù hợp, được đọc vào lúc bắt đầu của truy vấn -> values truy vấn từ các cột ở hàng này có thể được coi là hằng số của các phần còn lại của bộ tối ưu hóa. Các bảng const rất nhanh bởi vì chúng được đọc một lần. Const được sử dụng khi bạn so sánh tất cả các phần của một PRIMARY KEY hoặc index UNIQUE đến giá trị không đổi.
- Eq_ref: Một dòng được đọc từ bảng này cho mỗi sự kết hợp của các hàng từ bảng trước đó. Đây là loại join tốt nhất có thể. Nó được sử dụng khi tất cả các phần của một index được sử dụng bởi join và các chỉ số là một PRIMARY KEY hoặc chỉ mục UNIQUE NOT NULL. Ví dụ:
SELECT * FROM ref_table, other_table WHERE ref_table.key_column = other_table.column; SELECT * FROM ref_table, other_table WHERE ref_table.key_column_part1 = other_table.column AND ref_table.key_column_part2 = 1;
- Ref: Tất cả các hàng với giá trị index phù hợp được đọc từ bảng này cho mỗi sự kết hợp của các hàng từ bảng trước đó. Ref được sử dụng nếu phép join chỉ sử dụng một tiền tố tận cùng bên trái của khóa hoặc nếu khóa không phải là một PRIMARY KEY hoặc UNIQUE (index không thể chọn một hàng duy nhất dựa trên các giá trị quan trọng). Ví dụ:
SELECT * FROM ref_table WHERE key_column = expr; SELECT * FROM ref_table, other_table WHERE ref_table.key_column = other_table.column; SELECT * FROM ref_table, other_table WHERE ref_table.key_column_part1 = other_table.column AND ref_table.key_column_part2 = 1;
- Range: Chỉ có các hàng ở trong một phạm vi nhất định được lấy ra, sử dụng một index để chọn các hàng. Cột quan trọng ở hàng output cho biết chỉ số đó đã được sử dụng. Giá trị key_len chứa các phần key dài nhất được sử dụng. Cột ref là NULL ở loại này. Ví dụ:
SELECT * FROM tbl_name WHERE key_column = 10; SELECT * FROM tbl_name WHERE key_column BETWEEN 10 AND 20; SELECT * FROM tbl_name WHERE key_part1 = 10 AND key_part2 IN (10,20,30);
- ... (Xem chi tiết tại http://dev.mysql.com/doc/refman/5.5/en/explainoutput.html)
Optimizing join example
EXPLAIN SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate,
tt.ActualShipDate, tt.ClientID,
tt.ServiceCodes, tt.RepetitiveID,
tt.CurrentProcess, tt.CurrentDPPerson,
tt.RecordVolume, tt.DPPrinted,
et.COUNTRY, et_1.COUNTRY, do.CUSTNAME
FROM tt, et, et AS et_1, do
WHERE tt.SubmitTime IS NULL
AND tt.ActualPC = et.EMPLOYID
AND tt.AssignedPC = et_1.EMPLOYID
AND tt.ClientID = do.CUSTNMBR;
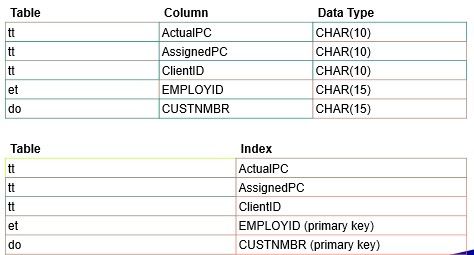
Ban đầu, trước khi bất kỳ việc tối ưu nào được thực hiện, câu lệnh EXPLAIN sinh ra các thông tin sau:

Kết quả này chỉ ra rằng MySQL tạo ra một Tích đề các tất cả các bảng. Điều này tốn một thời gian khá lâu, bởi vì số hàng phải xem xét bằng tích số hàng trong mỗi bảng. Đối với trường hợp này, kết quả là 74 × 2135 × 74 × 3872 = 45268558720 hàng. Nếu bảng lớn hơn -> tốn nhiều thời gian hơn.
Một vấn đề ở đây là MySQL có thể sử dụng các index trên các cột một cách hiệu quả hơn nếu chúng được khai báo là các loại và kích thước tương tự nhau. Trong bối cảnh này, VARCHAR và CHAR được coi là như nhau nếu chúng được khai báo cùng kích thước. tt.ActualPC được khai báo là CHAR(10) và et.EMPLOYID là CHAR(15), do đó không phù hợp về chiều dài. Giải pháp là đưa chúng về cùng CHAR(15). Thực thi các câu lệnh EXPLAIN một lần nữa sinh ra kết quả như sau:
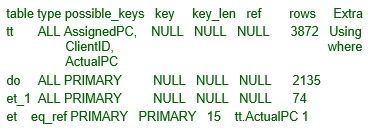
Đây không phải là phiên bản hoàn hảo, nhưng cũng đã tốt hơn: số dòng được sinh ra là ít hơn 74 lần. Phiên bản này thực hiện trong một vài giây. Một sự thay đổi thứ hai có thể được thực hiện để loại bỏ các sai lệch chiều dài cột cho sự so sánh tt.AssignedPC = et_1.EMPLOYID và tt.ClientID = do.CUSTNMBR:

Tại thời điểm này, truy vấn đã được tối ưu hóa gần như là tốt nhất có thể. Vấn đề còn lại là, theo mặc định, MySQL giả định rằng giá trị trong cột tt.ActualPC được phân bố đều, và đó không phải là trường hợp của bảng tt. Rất dễ để ra lệnh cho MySQL phân tích sự phân bố key bằng câu lệnh ANALYZE. Với các thông tin bổ sung về index, phép join là hoàn hảo:

Dự đoán hiệu suất Query
Bạn có thể ước tính hiệu suất truy vấn bằng cách đếm số lần tìm kiếm của ổ đĩa. Đối với các bảng nhỏ, bạn thường có thể tìm thấy một hàng trong một lần đĩa tìm kiếm (vì chỉ số có thể đã được lưu cache). Đối với các bảng lớn hơn, bạn có thể ước tính rằng, sử dụng các chỉ số B-tree, bạn cần seek nhiều lần nhằm tìm kiếm một row: log(ROW_COUNT) / log(index_block_length / 3 * 2 / (index_length + data_pointer_length)) + 1. Trong MySQL, một khối index thường là 1.024 byte và con trỏ dữ liệu thường là 4 byte. Đối với một bảng 500.000 hàng với độ dài giá trị key là 3 byte (kích thước của MEDIUMINT), công thức cho biết: log(500.000) / log(1024/3 * 2 / (3 + 4)) + 1 = 4 lần tìm kiếm. Index này sẽ yêu cầu không gian lưu trữ khoảng 500.000 * 7 * 3/2 = 5.2MB (giả định tỷ lệ lấp đầy bộ đệm index điển hình là 2/3), vì vậy bạn có thể có nhiều index trong bộ nhớ và vì vậy chỉ cần một hoặc hai lần gọi để đọc dữ liệu để tìm được row. Tuy nhiên để thực hiện việc ghi, bạn cần bốn lần yêu cầu tìm kiếm để tìm ra nơi để đặt một giá trị index mới và thường hai lần tìm kiếm để cập nhật các index và ghi row.
Measuring Performance
Hiệu suất phụ thuộc vào rất nhiều yếu tố khác nhau mà một sự khác biệt ở mức một vài phần trăm có thể không phải là một chiến thắng tuyệt đối. Các kết quả có thể thay đổi theo hướng ngược lại khi bạn thử nghiệm trong một môi trường khác nhau. Một số tính năng của MySQL giúp cải thiện hay không cải thiện hiệu suất lại phụ thuộc vào khối lượng công việc. Để hoàn chỉnh, luôn luôn kiểm tra hiệu suất với những tính năng trong cả trường hợp được bật và tắt.
Để đo tốc độ của một biểu thức MySQL cụ thể hoặc function, gọi hàm BENCHMARK() sử dụng chương trình mysql client như sau:
BENCHMARK(loop_count, expression).
Thí dụ: SELECT BENCHMARK(1000000,1 + 1);
Nếu chúng ta sử dụng một hệ thống Pentium II 400MHz, kết quả cho thấy rằng MySQL có thể thực hiện 1.000.000 biểu cộng đơn giản trong 0,32 giây trên hệ thống đó.
