Spatial Skyline Query Algorithms
Overview Skyline queries are responsible for finding a set of interesting points from a large set of data points with an arbitrary number of dimensions, these points are called skyline points. Specifically, skyline points are points that are not dominated by any other point on all dimensions. ...

Overview
Skyline queries are responsible for finding a set of interesting points from a large set of data points with an arbitrary number of dimensions, these points are called skyline points. Specifically, skyline points are points that are not dominated by any other point on all dimensions. Skyline computation has a strong impact in the development of database community. Many skyline query algorithms (skyline query operators) have been proposed and developed, and each of them has strong points as well as shortcomings, for example, the NN (nearest neighbor) algorithm which applies the divide-and-conquer paradigm on a dataset indexed by a space-partitioning data structure (e.g. RTree, KDTree, etc.) is currently one of the most efficient algorithm because it returns initial skyline points with a very high speed, it also can be used with arbitrary data distributions and dimensions; however, this algorithm also has some shortcomings such as duplicating elimination, multiple accesses the same node, and large space overhead.
Skyline queries are so-called user-preference queries because they determine the output according to some specific preferences (or dimensions – technically speaking). At the beginning, we mentioned about the “dominated” term, so what exactly does this term mean? A point p dominates another point q if and only if the value of p on any dimensions is not “better” than the corresponding value of q. “Better” means that we calculate the skyline points according to some pre-defined conditions, for instance minimum, maximum, joining, group-by, etc.; when the condition is “minimum” the above statement would become: “Point p dominates point q if and only if the coordinate of p on any axis is not larger than the corresponding coordinate of q”.
Skyline queries are strongly related to several problems, including nearest neighbor search, convex hulls, and top-K queries. Specifically, in this paper, we present the NN algorithm which uses the result of nearest neighbor search operation on an RTree to find the skyline points.
The rest of this article is dedicated for presenting the theoretical backgrounds as well as the details of three well-known skyline query algorithms: BNL (Block Nested Loop), NN (Nearest neighbor), and BBS (Branch and Bound Skyline). Note that, the two later algorithms are spatial ones because their datasets are indexed by RTree; the first algorithm – BNL is a straightforward way to compute the skyline, but its performance is good in many cases.
Block Nested Loop (BNL) Algorithm
Theoritical Background
BNL algorithm is the most straightforward way to evaluate the skyline ofa given data space. This algorithm compares each point p with every other point; if p is not dominated then it is a skyline point. The idea behind the algorithm is that it keeps a list of candidate skyline points in the memory; the first data point is inserted into the list. For subsequent points in data space, the algorithm performs one of the following steps:
- If p is dominated by any point in the list, it is not a part of the skyline, and then it is discarded.
- If p dominates any point in the list, it is inserted into the list, and all points dominated by p are removed from the list.
- If p is neither dominated, nor dominates any point in the list, it is inserted into the list (candidate skyline point).
One disadvantage of BNL is memory limitation. BNL is designed with in-memory approach, in case the list becomes larger than the main memory, we can use temporary files to prevent algorithm from crashing. However, the algorithm must be executed again and again to make sure that we find all possible skyline points. Despite of that disadvantage, BNL is still widely used for many applications because its implementation can be applied for any dimensionality without indexing or sorting the data. BNL is not a good choice for online processing problems because it has to load the entire data space before returning the skyline.
Implementation
The BNL algorithm starts with a list L of all data points, and an empty list of skyline points. The algorithm first checks if L is empty or not; if it is the case, the algorithm terminates immediately. Otherwise, we insert the first data point of L into S (candidate skyline point). The algorithm then loops through all the remain data points in L and performs some operations to update the content of the list S. Specifically, if a point p of L dominates some points in S, it is added to S, and all points dominated by p is dropped from S. In the next case, point p is not dominated or does not dominates some points in S, it is consider to be a candidate skyline point, and it is added to S. This is a naive approach of BNL algorithm to calculate skyline points, and it is efficient for some small and low-dimensional data space.
BNL pseudo code:
BNL algorithm
Input: L – the list of all data points
Skyline S = ∅
// If the list L is empty, terminate the algorithm
IF L is empty
Terminates the algorithm, returns S with no element
Insert the first point in L into S
FOR each point p in L
IF dominatesInSet(p, S)
Add p to S
Remove all points in S that are dominated by p
ELSE IF !(dominatesInSet(p, S) || dominatedInSet(p, S))
Add p to S
END FOR
// Return the skyline points
RETURN S
End BNL algorithm
Branch and Bound Skyline (BBS) Algorithm
Theoritical Background
In fact, we can use any kinds of index structure to partition our data space, but in our implementation for BBS we will use R-Tree because of its simplicity and efficiency. BBS algorithm is based on the branch-and-bound paradigm. The algorithm starts from root of the R-Tree and inserts all of root’s entries into a heap data structure (in our implementation, we use a priority queue) sorted according to their mindist values (the sum of all dimensions of an entry). Next, the algorithm extracts the heap entry with the minimum mindist value and expands it (we can just get the head of the priority queue (poll()) in our implementation); the expanding process removes that heap entry and inserts all of its children into the heap. The algorithm continues with the next heap entry with the minimum mindist value. Each time we get an entry p from heap, we will check for domination with all entries in the skyline list. Ifp is not dominated by any entries in the skyline list as well as p is an intermediate entry, we are going to get all of its children, and check for domination with entries in skyline list again. In case, a child of p is not dominated by any entries in skyline list, it is added to the heap. If the entry extracted from heap is a data point, it is added to skyline list. The algorithm terminates when the heap is empty.
Implementation
The algorithm starts by adding all entries of the root of the R-Tree into a heap (a priority queue in our actual implementation). By doing this, we initialize the heap with some candidate entries. In the next step, the algorithm loop through all elements in the heap to calculate skyline points as well as to update the content of the heap. Specifically, in each cycle, we remove the first element head in the heap and check for domination condition with all point in skyline list. If head is dominated by some points in skyline list, we discard it immediately without any further considerations. Otherwise, if head is an intermediate entry, we expand it and check for the domination condition on its children. For each child q of head, if q is not dominated by some point in skyline, q is inserted into the heap. In case head is not an intermediate entry (means that we traversed the tree to leafs), it is added to skyline list.
Because entries in the heap are sorted according to their mindist, the algorithm visits entries in the tree in ascending order by mindist. Furthermore, every data point will be examined, unless one of its ancestor nodes has been pruned. In fact, the algorithm returns skyline points instantly without having to visit a large part of the tree.
BBS pseudo code:
BBS algorithm
Input: Dataset D (indexed with R-Tree R)
Skyline S = ∅
Heap H = ∅
// If there is no data points, terminate the algorithm
IF D is empty
Terminates the algorithm, returns S with no element
ELSE
Add all entries of the root node of R-Tree in the heap H
// Repeat the whole process while the heap is not empty
WHILE (H ≠ ∅)
Get the first element of the heap (head) – e
IF e is dominated by some point in S
Discard e
ELSE
IF e is an intermediate entry
FOR each child q of e
IF q is not dominated by some point in S
Insert q into H
ELSE
Insert e into S
// Return the skyline points
RETURN S
End NN algorithm
Nearest Neighbor (NN) Algorithm
Theoritical Background
NN algorithm is based on nearestNeighborSearch operation in R-Tree. The algorithm divides the data space recursively after discovering one nearest neighbor, and applies the search operation on the sub-spaces. Specifically, NN performs the nearestNeighborSearch operation to find the point with the minimum distance from the beginning of the axes (origin), and this point is definitely a skyline point. After the discovering the first skyline point, the data space is divided into three regions (2D space).
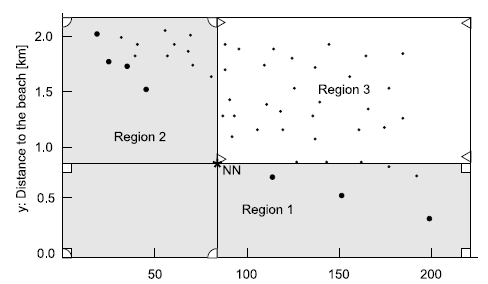
Space division after discovering the first nearest neighbor
All the points in region 3 can be eliminated in further process, because these points are dominated by the first nearest neighbor (NN in the figure). The region 1 and region 2 will be inserted into a to-do list because they may contain other skyline points. NN evaluates the to-do list until it is empty, in this case the algorithm terminates. While the to-do list is not empty, NN removes one partition form the list and recursively repeats the same process.
The nearestNeighborSearch operation is cheap if the data is index with R-Tree, so the NN will return some first results instantaneously. However, as the number of dimensions of the data space increases, the performance of the NN decreases very fast because the nearestNeighborSearch becomes an expensive operation.
The NN algorithm is not applicable if the skyline query involves a dimension that is not indexed, or if the skyline query involves large joins, group-by operation.
Implementation
For implementation we restrict the number of dimensions of the data space to 2 (2D space). NN algorithm pseudo-code is shown as following:
NN algorithm
Input: Dataset D (indexed with R-Tree R)
To-do list T = {(∞, ∞)}
Skyline S = ∅
// If there is no data points, terminate the algorithm
IF D is empty
Terminates the algorithm, returns S with no element
ELSE
// Find the first nearest neighbor to the origin
P (x, y) = nearestNeighborSearch (R, origin, 1)
// Add the first nearest neighbor to the skyline list
Add P (x, y) to S
// Add two points after discover the first nearest neighbor to the
// to-do list. Points in the to-do list will be used to construct the
// space (rectangle in 2D space) later.
Add P-a (P(x), MAX_COORDINATE_VALUE) to T
Add P-b (MAX_COORDINATE_VALUE, P(y)) to T
// Repeat the whole process while the to-do list is not empty
WHILE (T ≠ ∅)
// Fetch the first element from the to-do list
HEAD (x, y) = get the first element from T
// Perform the bounded nearest neighbor search
SKYLINE (x, y) = boundedNNSearch (origin, Rec(origin, HEAD (x, y)), 1)
// Add the result of bounded nearest neighbor search and
// divided spaces to the to-do list (if they exist)
IF SKYLINE (x, y) exists
Add SKYLINE (x, y) to S
Add (SKYLINE(x), HEAD(y)) to T
Add (HEAD(y), SKYLINE(x)) to T
// Return the skyline points
RETURN S
End NN algorithm
The heart of the algorithm is the boundedNNSearch operation. This operation takes inputs as the origin of the axes, the rectangle construct from the origin and the HEAD (x, y) point (awidth of the rectangle is H(x), height of the rectangle is H(y)), and the number of points to find. In our case, this operation is responsible to get the first nearest neighbor to the origin with the condition that this point must be strictly inside the above defined rectangle.
NN algorithm is good for retrieving some first skyline points because the nearest neighbor search operation in R-Tree is fast. However, if we want to retrieve all skyline points in a large and high-dimensional data space, the performance of NN algorithm reduces considerably. The reason for that problem comes from redundant non-empty queries that NN has to perform. The NN algorithm terminates when the nearest neighbor query does not retrieve any point within the current data space (empty-query). However, in many cases, the NN algorithm retrieves skyline points that have been found in the previous queries, these redundant operations cause a node in the tree to be accessed many times, and it hurts the performance of the algorithm. Another problem of NN is the size of the to-do list which can exceed the size of the data space even if we do not consider the redundant queries.
Demonstration
A demo application for above algorithms is available on GitHub. This application is written in Java and has a built-in GUI for visualization.
Source code: https://github.com/vinhnguyen-fly/skyline-query
References
- An Optimal and Progressive Algorithm for Skyline Queries by Dimitris Papadias, Yufei Tao, Greg Fu, and Bernhard Seeger.
- Shooting Stars in the Sky: An Online Algorithm for Skyline Queries by Donald Kossmann, Frank Ramsak, and Steffen Rost.
- R-Trees A Dynamic Index Structure for Spatial Searching by Antonin Guttman.
- For RTree library, we use an open-source library developed by Dave Moten. This is an in-memory immutable 2D R-tree implementation in java using RxJava Observables for reactive processing of search results.
- Dave Moten: https://github.com/davidmoten
- RTree: https://github.com/davidmoten/rtree
