11/08/2018, 15:53
SQL trở lại quyết đấu NoSQL và tương lai của dữ liệu
SQL đã trở lại sau nhiều năm bị bỏ mặc. Thế quái nào? Và ảnh hưởng của việc này đến cộng đồng data? Từ những ngày đầu của kỷ nguyên máy tính, chúng ta đã từng thu thập một lượng dữ liệu ngày càng lớn, liên tục đòi hỏi nhiều hơn về năng lực của công nghệ xử lý, phân tích và lưu ...

SQL đã trở lại sau nhiều năm bị bỏ mặc. Thế quái nào? Và ảnh hưởng của việc này đến cộng đồng data?
Từ những ngày đầu của kỷ nguyên máy tính, chúng ta đã từng thu thập một lượng dữ liệu ngày càng lớn, liên tục đòi hỏi nhiều hơn về năng lực của công nghệ xử lý, phân tích và lưu trữ dữ liệu.
Trong thập kỷ qua, nguyên nhân này khiến cho các developer bỏ qua SQL để hướng tới một thứ có các đặc tính có thể mở rộng được là NoSQL: MapReduce và Bigtable, Cassandra, MongoDB…
Tuy nhiên, SQL đang dần trở lại. Tất cả các nhà cung cấp dịch vụ cloud lớn hiện nay đều offer database dạng này như Amazon RDS, Google Cloud SQL, Azure Database for PostgreSQL (Azure chỉ vừa mới launch trong năm nay). Theo cách riêng của Amazon, Aurora database (compatible với MySQL-PostgreSQL) trở thành dịch vụ có tốc độ tăng trưởng nhanh nhất lịch sử AWS.
SQL interface bên trên lớp Hadoop/Spark tiếp tục phát triển. Và chỉ mới tháng trước, Kafka đã hỗ trợ SQL.
Trong bài viết này, chúng tôi sẽ kiểm tra tại sao tình thế lại xoay chuyển trở lại với SQL, và ý nghĩa của việc này đối với giới data engineering và analysis
Phần 1: Một niềm hy vọng mới
Để hiểu tại sao SQL trở lại, hãy bắt đầu ở khởi điểm với lý do tại sao nó được thiết kế
 Khởi điềm của SQL thập niên 70
Khởi điềm của SQL thập niên 70
Câu chuyện bắt đầu tại IBM Research trong thời kỳ đầu của thập niên 70, nơi mà cơ sở dữ liệu quan hệ ra đời. Vào thời điểm đó, ngôn ngữ truy vấn dựa vào logic toán học và ký hiệu. Hai tiến sĩ Donald Chamberlin và Raymond Boyce đã bị ấn tượng bởi mô hình dữ liệu quan hệ, nhưng cũng thấy rằng ngôn ngữ truy vấn sẽ là một nút thắt cản trở việc áp dụng nó.
Họ đã thiết kế một ngôn ngữ truy vấn mới (theo cách của họ): “dễ tiếp cận hơn cho người dùng mà không cần được đào tạo chính quy về toán học hoặc lập trình máy tính.”
 Ngôn ngữ truy vấn trước đây của SQL (a, b) và SQL ©
Ngôn ngữ truy vấn trước đây của SQL (a, b) và SQL ©
Trước thời kỳ của Internet và máy tính cá nhân, khi mà ngôn ngữ lập trình C được giới thiệu với thế giới, hai nhà khoa học máy tính trẻ nhận ra rằng, “phần lớn sự thành công của ngành công nghiệp máy tính phụ thuộc vào việc phát triển một nhóm người dùng phổ thông khác, ngoài việc đào tạo các chuyên gia máy tính”.
Họ muốn một ngôn ngữ truy vấn dễ hiểu như tiếng Anh, và cũng bao gồm hệ quản trị cơ sở dữ liệu và thao tác.
Kết quả là SQL, lần đầu tiên được giới thiệu với thế giới vào năm 1974. Trong vài thập kỷ sau đó, SQL đã chứng minh được sự phổ biến rộng rãi. Khi các cơ sở dữ liệu quan hệ như System R, Ingres, DB2, Oracle, SQL Server, PostgreSQL, MySQL (và nhiều hơn nữa) đã tiếp quản ngành công nghiệp phần mềm, SQL đã trở thành ngôn ngữ ưu việt để tương tác đến cơ sở dữ liệu với cộng đồng đông đảo và hệ sinh thái cạnh tranh.
(Đáng buồn, Raymond Boyce chưa bao giờ có cơ hội chứng kiến sự thành công của SQL và chết vì chứng phình mạch não 1 tháng sau khi đưa ra một trong những bài thuyết trình SQL sớm nhất, chỉ 26 tuổi, để lại vợ và con gái).
Trong một giai đoạn, dường như SQL đã hoàn thành thành công sứ mệnh của nó. Nhưng sau đó Internet ra đời.
Phần 2: NoSQL phản kháng
Trong khi Chamberlin và Boyce đang tập trung phát triển SQL, họ không nhận ra là nhóm kỹ sư thứ hai ở California khi ấy đang làm việc cho một dự án khác mà sau đó nó lan rộng và đe doạ sự tồn tại của SQL. Dự án đó là ARPANET, và vào ngày 29 tháng 10 năm 1969, nó đã ra đời.
 Những người đã tạo ra ARPANET
Những người đã tạo ra ARPANET
Nhưng SQL đã thực sự tốt cho đến khi một kỹ sư khác xuất hiện và phát minh ra World Wide Web, vào năm 1989.
 Người phát minh ra Web
Người phát minh ra Web
Giống như một loại cỏ dại, Internet và Web đã phát triển mạnh mẽ, phá vỡ thế giới của chúng ta bằng nhiều cách, nhưng đối với cộng đồng dữ liệu, nó gây ra một vấn đề nhức đầu: nhiều nguồn tạo ra dữ liệu mới với khối lượng và vận tốc cao hơn trước.
Khi Internet tiếp tục phát triển và phát triển, cộng đồng phần mềm đã phát hiện ra rằng cơ sở dữ liệu quan hệ lúc đó không thể xử lý nổi. Có một sự hỗn loạn, kiểu như hàng triệu database đột nhiên kêu khóc và bị quá tải.
Sau đó, hai gã khổng lồ mới của Internet đã đột phá và phát triển các hệ thống non-relational phân tán của riêng họ để giúp giải quyết vấn đề này: MapReduce (xuất bản năm 2004) và Bigtable (xuất bản 2006) của Google và Dynamo (xuất bản năm 2007) của Amazon.
Các tài liệu này đã dẫn tới nhiều cơ sở dữ liệu non-relational khác, bao gồm Hadoop (dựa trên MapReduce paper, 2006), Cassandra (lấy cảm hứng từ cả hai bài báo Bigtable và Dynamo, 2008) và MongoDB (2009). Bởi vì đây là những hệ thống mới được viết từ đầu, họ cũng tránh SQL, dẫn đến sự gia tăng của phong trào NoSQL.
Thật dễ hiểu tại sao: NoSQL mới và sáng bóng; hứa hẹn về scale và power; nó dường như là con đường nhanh chóng để thành công về kỹ thuật. Nhưng rồi những vấn đề bắt đầu xuất hiện.
 Nhà phát triển phần mềm cổ điển bị cám dỗ bởi NoSQL. Đừng trở thành anh chàng này.
Nhà phát triển phần mềm cổ điển bị cám dỗ bởi NoSQL. Đừng trở thành anh chàng này.
Các nhà phát triển sớm nhận ra rằng không có SQL thực sự là khá hạn chế. Mỗi cơ sở dữ liệu NoSQL cung cấp ngôn ngữ truy vấn duy nhất của riêng mình, có nghĩa là nhiều ngôn ngữ hơn để học (và dạy cho đồng nghiệp của bạn); gia tăng sự khó khăn trong việc kết nối các cơ sở dữ liệu này với các ứng dụng, dẫn đến dính theo hàng tấn code; thiếu hệ sinh thái của bên thứ ba, đòi hỏi các công ty phải phát triển các công cụ vận hành và biểu diễn dữ liệu riêng.
Những ngôn ngữ NoSQL mới cũng không được phát triển đầy đủ. Ví dụ, để thêm tính năng JOIN của SQL vào NoSQL rất phức tạp ở tầng application. Sự thiếu JOINs cũng dẫn đến sự không bình thường, dẫn đến sự sụp đổ và vẹn toàn của dữ liệu.
Một số cơ sở dữ liệu NoSQL đã thêm các ngôn ngữ truy vấn “giống SQL”, như CQL của Cassandra. Nhưng điều này thường gây ra vấn đề tồi tệ hơn. Sử dụng một giao diện gần giống với một cái gì đó phổ biến hơn, thực sự ám ảnh về mặt tinh thần: các kỹ sư không biết những gì đã được hỗ trợ và những gì không được.
 Các ngôn ngữ truy vấn SQL tương tự như Star Wars Holiday Special.
Các ngôn ngữ truy vấn SQL tương tự như Star Wars Holiday Special.
Một số trong cộng đồng đã nhận thấy những vấn đề với NoSQL từ sớm (ví dụ, DeWitt và Stonebraker trong năm 2008). Theo thời gian, ngày càng có nhiều nhà phát triển phần mềm nhận ra điều này.
Phần 3: Sự trở lại của SQL
Ban đầu bị quyến rũ bởi “lực lượng bóng tối”, cộng đồng phần mềm bắt đầu nhìn thấy ánh sáng và trở lại với SQL.
Đầu tiên là các giao diện SQL bên trên Hadoop/Spark, hướng NoSQL thành “Not only SQL”
Sự phát triển của NewSQL: cơ sở dữ liệu mới, có thể mở rộng và hỗ trợ SQL. H-Store (xuất bản năm 2008) của MIT và các nhà nghiên cứu ở Brown lần đầu tiên thực hiện mở rộng các cơ sở dữ liệu OLTP . Google tiếp tục dẫn đầu việc nhân rộng cơ sở dữ liệu có giao diện SQL với bản báo cáo đầu tiên của họ (xuất bản năm 2012) (những tác giả bao gồm các tác giả gốc MapReduce), tiếp theo là những người tiên phong khác như CockroachDB (2014).
Đồng thời, cộng đồng PostgreSQL bắt đầu hồi sinh, bổ sung các cải tiến quan trọng như kiểu dữ liệu JSON (2012) và một loạt các tính năng mới trong PostgreSQL 10: hỗ trợ tốt hơn cho phân vùng và replication, hỗ trợ tìm kiếm văn bản toàn diện cho JSON và hơn thế nữa (dự kiến phát hành cuối năm nay). Các công ty khác như CitusDB (2016) và Yours Truly (TimescaleDB, phát hành trong năm nay) đã tìm ra những cách mới để mở rộng PostgreSQL cho các data workload chuyên biệt.

Trên thực tế, hành trình phát triển TimescaleDB của chúng tôi phản ánh chặt chẽ con đường mà ngành công nghiệp đã trải qua. Các phiên bản nội bộ đầu tiên của TimescaleDB bao gồm ngôn ngữ truy vấn SQL-like, gọi là “ioQL.” Vâng, chúng tôi cũng bị cám dỗ bởi mặt tối: việc xây dựng ngôn ngữ truy vấn riêng của chúng tôi có cảm tưởng là sẽ mạnh mẽ. Tưởng như dễ dàng, chúng tôi lại sớm nhận ra rằng chúng ta phải làm nhiều việc hơn: ví dụ, quyết định cú pháp, xây dựng các kết nối khác nhau, giáo dục người dùng … Chúng tôi cũng tìm thấy chính mình liên tục tìm kiếm cú pháp phù hợp với truy vấn mà chúng tôi đã có thể thể hiện bằng SQL, cho một ngôn ngữ truy vấn mà chúng tôi đã chính tay viết ra!
Một ngày chúng tôi nhận ra rằng xây dựng ngôn ngữ truy vấn riêng của chúng tôi không có ý nghĩa. Đó chính là chìa khóa dẫn đến chấp nhận SQL. Và đó là một trong những quyết định thiết kế tốt nhất mà chúng tôi đã thực hiện. Ngay lập tức một thế giới hoàn toàn mới mở ra. Ngày nay, mặc dù TimescaleDB chỉ là một cơ sở dữ liệu 5 tháng tuổi, người dùng có thể sử dụng trong production và nhận được tất cả các điều tuyệt vời: công cụ trực quan (Tableau), kết nối với các ORM phổ biến, một loạt các tools và các tùy chọn sao lưu, hướng dẫn phong phú và giải đáp syntax trực tuyến, v.v.
Nhưng đừng tin chúng tôi. Hãy thử tìm hiểu về Google
Google rõ ràng là người tiên phong trong lĩnh vực cơ sở dữ liệu và cơ sở hạ tầng trong hơn một thập kỷ nay. Nó khiến chúng tôi chú ý đến những gì họ đang làm.
Xem paper của Google(Spanner), phát hành cách đây chỉ bốn tháng (Spanner: Becoming a SQL System, May 2017), và bạn sẽ thấy rằng nó củng cố các phát hiện của chúng tôi.
Ví dụ: Google đã bắt đầu xây dựng trên Bigtable, nhưng sau đó phát hiện ra rằng việc thiếu các vấn đề tạo SQL (nhấn mạnh trong tất cả các trích dẫn dưới đây của chúng tôi):
“Mặc dù các hệ thống này cung cấp một số lợi ích của một hệ thống cơ sở dữ liệu, nhưng họ thiếu nhiều tính năng cơ sở dữ liệu truyền thống mà các nhà phát triển ứng dụng thường dựa vào. Một ví dụ quan trọng là một ngôn ngữ truy vấn mạnh mẽ, có nghĩa là các nhà phát triển phải viết mã phức tạp để xử lý và tổng hợp dữ liệu trong các ứng dụng của họ. Do đó, chúng tôi đã quyết định biến Spanner thành một hệ thống SQL đầy đủ tính năng, với việc thực hiện truy vấn được tích hợp chặt chẽ với các tính năng kiến trúc khác của Spanner (như tính nhất quán mạnh mẽ và nhân rộng toàn cầu). “
Sau đó trong bài báo họ tiếp tục feature các lý do chuyển đổi từ NoSQL sang SQL:
API gốc của Spanner đã cung cấp các NoSQL methods để tra cứu và quét dãy các bảng riêng lẻ và xen kẽ nhau. Trong khi NoSQL methods cung cấp một path đơn giản để khởi chạy Spanner, và tiếp tục hữu ích trong các kịch bản thu hồi kết quả đơn giản, SQL đã cung cấp giá trị bổ sung đáng kể trong việc thể hiện các mẫu truy cập dữ liệu phức tạp hơn và đẩy tính toán vào dữ liệu.
Bài báo cũng mô tả cách họ không ngừng nghỉ áp dụng SQL vào Spanner, mở rộng ra toàn bộ phần còn lại của Google, nơi mà nhiều hệ thống hiện nay có chung một phương ngữ SQL:
SQL engine của Spanner chia sẻ một phương ngữ SQL phổ biến, được gọi là “Standard SQL”, với một số hệ thống khác của Google bao gồm các hệ thống nội bộ như F1 và Dremel (các hệ khác) và các hệ thống bên ngoài như BigQuery …
Đối với người dùng Google, điều này làm giảm rào cản làm việc giữa các hệ thống. Nhà phát triển hoặc nhà phân tích dữ liệu có thể viết SQL trong cơ sở dữ liệu Spanner để transfer sự hiểu biết của họ về ngôn ngữ này sang Dremel mà không quan tâm đến sự khác biệt nhỏ về syntax, xử lý NULL, v.v …
Sự thành công của cách tiếp cận này nói lên bản thân nó. Spanner đã là “suối nguồn chân lý” cho các hệ thống lớn của Google, bao gồm cả AdWords và Google Play, trong khi khách hàng tiềm năng của đám mây quan tâm đến việc sử dụng SQL.
Xét rằng Google đã giúp khởi xướng phong trào NoSQL, thì điều đáng chú ý là ngày nay, họ đang nắm bắt SQL .
Điều này có ý nghĩa gì đối với tương lai của data?
Trong computer networking, có một khái niệm gọi là “narrow waist”.
Ý tưởng này xuất hiện để giải quyết một vấn đề then chốt: Trên bất kỳ thiết bị nối mạng nào, hãy tưởng tượng một ngăn xếp, với các lớp phần cứng ở dưới cùng và các lớp phần mềm trên đầu. Có thể tồn tại một loạt các phần cứng mạng; tương tự có thể tồn tại một loạt các phần mềm và ứng dụng. Cần một cách để đảm bảo rằng bất kể vấn đề về phần cứng, phần mềm vẫn có thể kết nối với mạng; và bất kề vấn đề về phần mềm, phần cứng mạng vẫn biết cách xử lý các yêu cầu mạng.
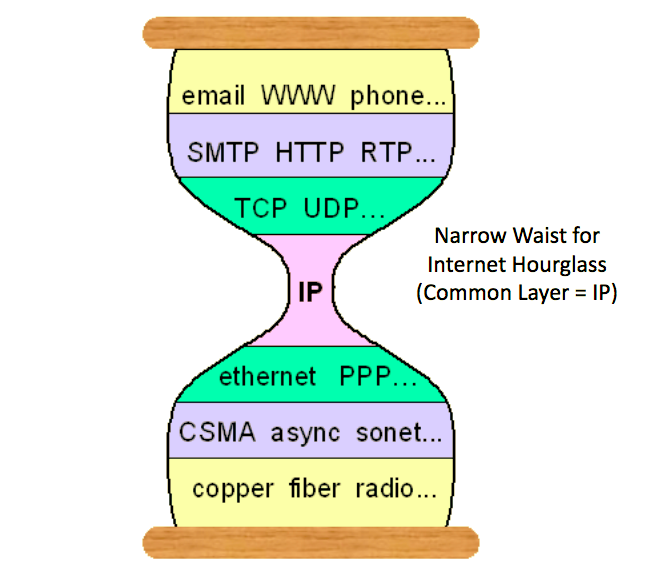 The Networking Narrow Waist
The Networking Narrow Waist
Trong thế giới mạng, vai trò của narrow waist được thực hiện bởi Internet Protocol (IP), đóng vai trò như một giao diện chung giữa các giao thức mạng cấp thấp được thiết kế cho mạng cục bộ và các giao thức ứng dụng và giao thức cấp cao hơn. Giao diện chung này đã trở thành ngôn ngữ giữa các máy tính, cho phép các mạng kết nối, thiết bị truyền thông và “mạng lưới các mạng” này phát triển thành Internet phong phú và đa dạng ngày nay.
Chúng tôi tin rằng SQL đã trở thành narrow waist để phân tích dữ liệu.
Chúng ta đang sống trong thời đại mà dữ liệu đang trở thành “nguồn tài nguyên quý giá nhất thế giới” (The Economist, tháng 5 năm 2017). Kết quả là, chúng ta đã chứng kiến sự bùng nổ của các cơ sở dữ liệu chuyên dụng Cambri (OLAP, time-series, document, graph, etc.), các công cụ xử lý dữ liệu (Hadoop, Spark, Flink), data buses (Kafka, RabbitMQ). Ngày càng nhiều ứng dụng cần dựa vào hạ tầng cơ sở dữ liệu này, kể cả là các công cụ trực quan hoá dữ liệu của bên thứ ba (Tableau, Grafana, PowerBI, Superset), các web frameworks (Rails, Django) hay các custom-built data-driven applications.
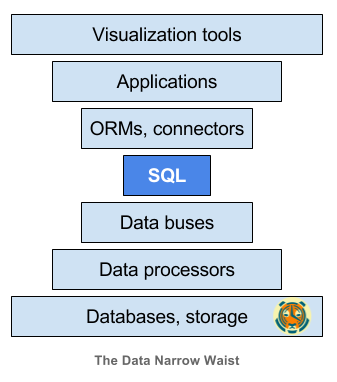
Giống như networking, stack phức tạp với cơ sở hạ tầng ở dưới cùng và các ứng dụng bên trên. Thông thường, chúng ta sẽ viết rất nhiều code để làm cho stack hoạt động và chúng cần phải được maintain.
Những gì chúng ta cần là một giao diện chung cho phép các phần của stack này liên lạc với nhau. Một điều gì đó đã được chuẩn hóa trong ngành. Cái gì đó sẽ cho phép chúng ta trao đổi trong / ngoài các lớp khác nhau với thất thoát tối thiểu.
Đó là sức mạnh của SQL. Giống như IP, SQL là một giao diện chung.
Nhưng SQL thực sự khác biệt hơn IP. Bởi vì dữ liệu cũng được phân tích bởi con người. Và đúng với mục đích mà người sáng tạo ra SQL gán cho nó thuở ban đầu: SQL có thể đọc được.
SQL hoàn hảo? Không, nhưng đó là ngôn ngữ mà hầu hết chúng ta biết. Và mặc dù đã có các kỹ sư đang làm việc trên giao diện ngôn ngữ tự nhiên hơn, những hệ thống này sau đó sẽ kết nối với những gì? Yes, SQL.
Vì vậy, có một lớp ở trên cùng của stack. Và lớp đó là chúng ta.
SQL đã trở lại
SQL đã trở lại. Bởi vì thế giới đang đầy ắp dữ liệu. Nó vây quanh và liên kết mọi người. Lúc đầu, chúng ta dựa vào các giác quan của con người và hệ thần kinh cảm giác để xử lý nó. Bây giờ phần mềm và các hệ thống phần cứng cũng đủ thông minh, sự phức tạp của các hệ thống lưu trữ, xử lý, phân tích…chúng thu thập dữ liệu ngày càng nhiều hơn để hiểu rõ hơn về thế giới của chúng ta.
 Master Data Scientist Yoda
Master Data Scientist Yoda
TechTalk via Tourist Đệ Quy
