Tìm hiểu về Filtering trong hệ thống Linux
Cùng với sự phát triển của công nghệ thông tin, lượng dữ liệu cần truy cập và xử lý cũng ngày càng nhiều. Khi hiển thị dữ liệu cho người dùng, các công cụ ngày nay đã cố gắng để hiển thị một cách trực quan nhất có thể, phần nào giúp cho người dùng dễ dàng hơn trong việc tiếp cận. Tuy nhiên, ...

Cùng với sự phát triển của công nghệ thông tin, lượng dữ liệu cần truy cập và xử lý cũng ngày càng nhiều. Khi hiển thị dữ liệu cho người dùng, các công cụ ngày nay đã cố gắng để hiển thị một cách trực quan nhất có thể, phần nào giúp cho người dùng dễ dàng hơn trong việc tiếp cận. Tuy nhiên, do một vài yếu tố khách quan, như giới hạn của màn hình, cũng như lượng thông tin dữ liệu đó cung cấp khá lớn, nên đôi khi người dùng vẫn gặp một chút khó khăn để hiểu được toàn bộ thông tin (hay dữ liệu) mà họ đang truy cập. Ngày nay, thay vì một văn bản thuần tuý, dữ liệu có thể hiển thị theo nhiều cách khác nhau, chẳng hạn hình ảnh, âm thanh, video .... Điều này phần nào giúp người dùng có thể dễ dàng tiếp cận với dữ liệu hơn. Tất nhiên, nó chỉ xảy ra trên các thiết bị có cài đặt một hệ điều hành người dùng đồ họa. Còn với một hệ thống mà chỉ thường xuyên thao tác trên cửa sổ dòng lệnh Terminal thì việc hiển thị dữ liệu lại chỉ bao gồm văn bản thuần tuý. Và khi các dữ liệu này được hiển thị, thì nó chỉ hiển thị những giá trị quan trọng nhất mà nhà phát triển nghĩ có thể đa số người sử dụng sẽ dùng đến. Để có thể lấy chính xác được các dữ liệu có giá trị, người dùng cần thêm một bước là lọc dữ liệu (thuật ngữ gọi là Filtering). Đây là cách mà người dùng có thể lấy được chính xác dữ liệu mình cần.
Linux hay UNIX đều mặc định sử dụng môi trường dòng lệnh làm môi trường làm việc chính. Vì vậy, các kỹ thuật filtering là rất cần thiết cho những người thường xuyên làm việc trên các dòng hệ điều hành này. Có thể có người sẽ nghĩ, ngày nay các hệ thống Linux hay UNIX đều hầu hết có giao diện đồ họa hết rồi, vậy cần gì mất công học kỹ thuật này nữa. Tuy nhiên, với một số tác vụ mà ta chỉ có thể truy cập từ xa (remote qua ssh, vnc ...), hoặc với những thiết bị không có một hệ thống phần cứng đủ để khởi động giao diện đồ họa, hoặc chỉ đơn giản là người dùng thích sử dụng dòng lệnh, thì các kỹ thuật kiểu thế này thực sự rất cần thiết. Nhắc đến giao diện dòng lệnh thì người ta thường sẽ nghĩ đến ngay các câu lệnh với các tham số đầu vào phức tạp và có quy luật. Phức tạp vì một câu lệnh thường có rất rất nhiều tùy chọn dành cho người dùng, ta không thể nhớ hết được các tùy chọn đó trừ phi đọc tài liệu man page, còn có quy luật là vì một số câu lệnh có thể có các tham số với tác dụng tương đương, học một câu lệnh thì có thể nhanh chóng học một câu lệnh khác tương tự (VD head và tail).
2.1 Áp dụng kỹ thuật piping trong khi filtering
Do các câu lệnh trong Linux thường chỉ đảm nhiệm một công việc nhất định, nên có một số trường hợp ta cần kết hợp nhiều câu lệnh mới hoàn thành được công việc. Chính vì vậy, khi filtering ta có thể sử dụng kỹ thuật piping để các câu lệnh có thể liên kết với nhau dễ dàng hơn. Nếu chưa biết đến piping, bạn có thể xem trước bài viết sau trong cùng series Linux for dummy của mình: https://viblo.asia/p/piping-va-chuyen-huong-cau-lenh-trong-linux-bJzKmk4Ol9N
2.2 Các câu lệnh dùng để filtering
Trước hết, mình sẽ liệt kê một số câu lệnh thường được sử dụng nhiều nhất cho kỹ thuật Filtering trong Linux.
Về cú pháp sử dụng câu lệnh, các bạn có thể dùng lệnh man [command] để xem chi tiết hoặc xem qua các ví dụ của mình ^^.
Câu lệnh cat và tac
Mặc dù không có tác dụng là lọc dữ liệu, nhưng đây là 2 câu lệnh cực kì hữu hiệu để lấy dữ liệu từ file, phục vụ cho việc lọc dữ liệu. Nội dung của file có thể được in ra màn hình mà không cần phải mở file lên bằng bất cứ một trình soạn thảo văn bản nào. Điểm khác biệt là cat sẽ in file từ dòng đầu tiên đến dòng cuối cùng, còn tac sẽ in theo thứ tự ngược lại với cat.
(Với cat khi dùng -n thì sẽ in kèm theo cả số dòng.)
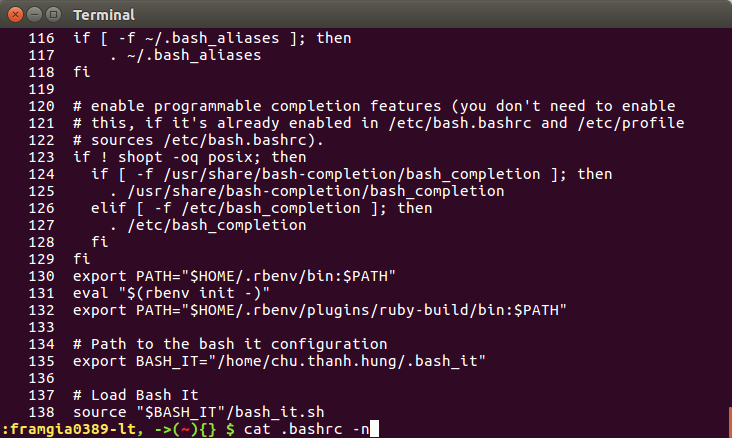
VD về tac (dữ liệu của file sẽ bị đảo ngược thứ tự dòng)
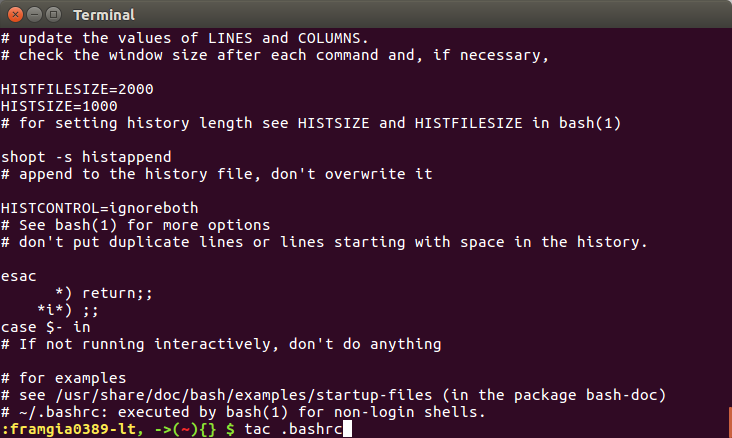
Hai lệnh cat và tac chỉ đơn giản là in cho ta nội dung của file
Câu lệnh head và tail
Hai câu lệnh này tương tự như nhau về cách sử dụng, chỉ có khác một điều là head lọc dữ liệu từ trên xuống còn tail thì lọc từ dưới lên. Mặc định 2 câu lệnh đều lấy 10 dòng dữ liệu, hoặc có thể chỉ định số dòng muốn lấy bằng tùy chọn -n.
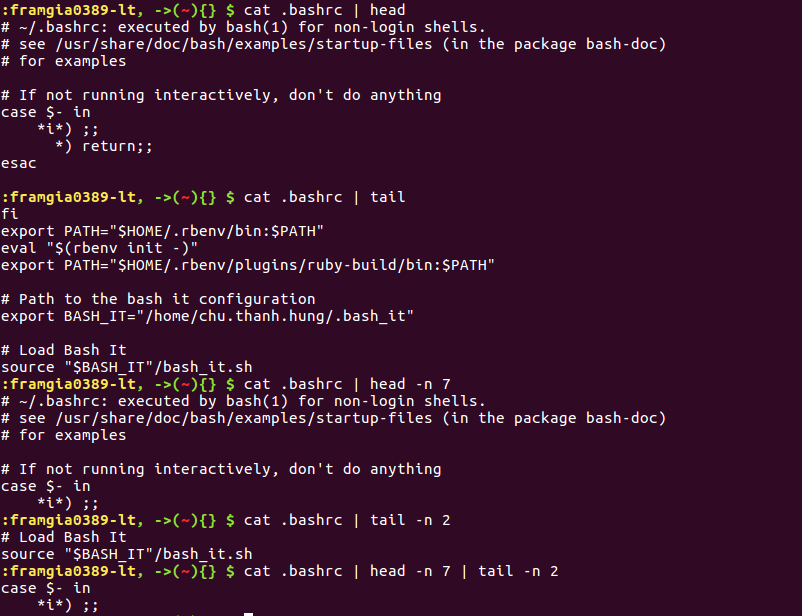
Với việc kết hợp head cùng với tail thông qua piping, dữ liệu được sử dụng cho câu lệnh sau sẽ được lấy thông qua câu lệnh trước. Như vậy nếu dùng câu lệnh cat .bashrc | head -n 7 | tail -n 2 thì kết quả cuối cùng sẽ là 2 dòng 6 và 7 của file .bashrc. Với việc dùng -c thay cho -n, đơn vị tính sẽ chuyển về số byte kí tự thay vì số dòng.
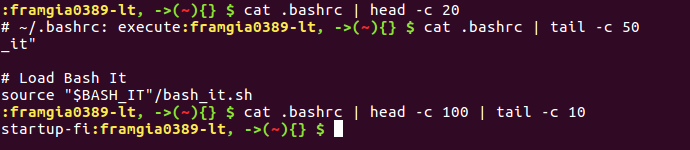
head và tail sẽ được dùng khi chúng ta có số lượng dữ liệu với rất nhiều dòng nhưng lại chỉ muốn lấy một số dòng cụ thể và liên tiếp nhau
Lệnh sort và uniq
Lệnh sort có tác dụng sắp xếp các dòng dữ liệu theo một thứ tự nhất định (mặc định sẽ sắp xếp theo thứ tự bảng chữ cái). Lệnh uniq thường dùng chung với sort, có tác dụng loại bỏ các kết quả trùng lặp sau khi sắp xếp.
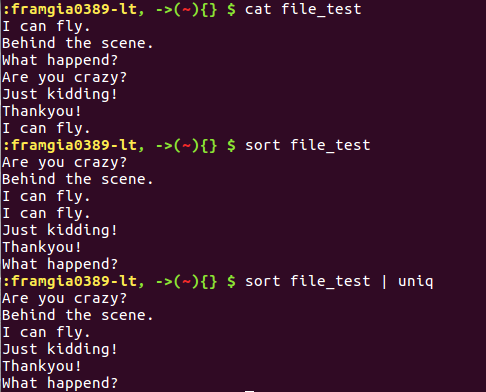
sort và uniq có tác dụng giúp cho việc kiểm kê các dạng dữ liệu tương tự nhau được dễ dàng hơn.
Lệnh cut
Thay vì lấy các dòng dữ liệu như head và tail, cut có tác dụng để lấy các cột dữ liệu (thường là dữ liệu dạng bảng)
- Tùy chọn -f để chỉ định thứ tự của cột sẽ lấy (mặc định sẽ lấy tất cả các cột)
- Tùy chọn -d để định nghĩa separator (mặc định sẽ dùng ký tự TAB)
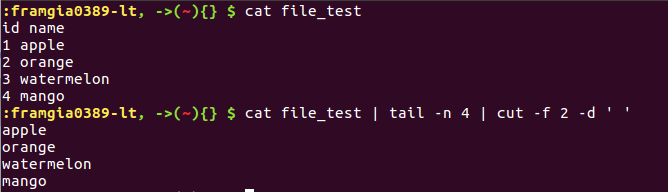
Có thể chỉ định lấy nhiều cột dữ liệu như sau
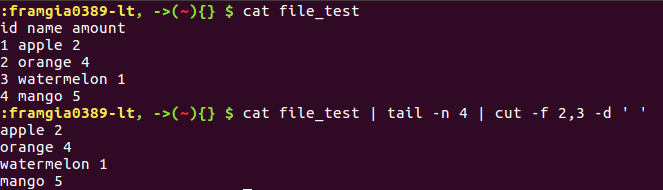
cut là lệnh cực kỳ hữu ích trong trường hợp thao tác với dữ liệu dạng bảng
Lệnh less và more
Trong trường hợp cần phải đọc toàn bộ dữ liệu từ một file nhưng lại không muốn mở file đó lên bằng một trình soạn thảo nào đó, ta có thể sử dụng lệnh less hoặc lệnh more để phân trang file cần đọc. Điểm khác biệt giữa less và more là less cho phép cuộn ngược lên các trang dữ liệu đã đọc, còn more thì chỉ có thể đọc từ đầu tới cuối. Có một cách khác khi đọc dữ liệu kiểu này là có thể dùng cat để in toàn bộ dữ liệu ra màn hình, tuy nhiên trên môi trường tty console vốn không hỗ trợ scroll bar thì không thể xem hết được nội dung file nếu file quá dài.
less và more thường sẽ được dùng để phân trang dữ liệu
Lệnh grep
Lệnh này có tác dụng tìm kiếm trong file stream các dòng dữ liệu có chứa một cụm từ cụ thể.
- Tùy chọn -v sẽ đảo ngược kết quả tìm kiếm, dữ liệu sẽ là các dòng không chứa cụm từ nhập vào.
- Tùy chọn -c sẽ đếm số dòng xuất hiện của của cụm từ truyền vào.
- Tùy chọn -i sẽ tìm kiếm mà không phân việt chữ hoa và chữ thường.
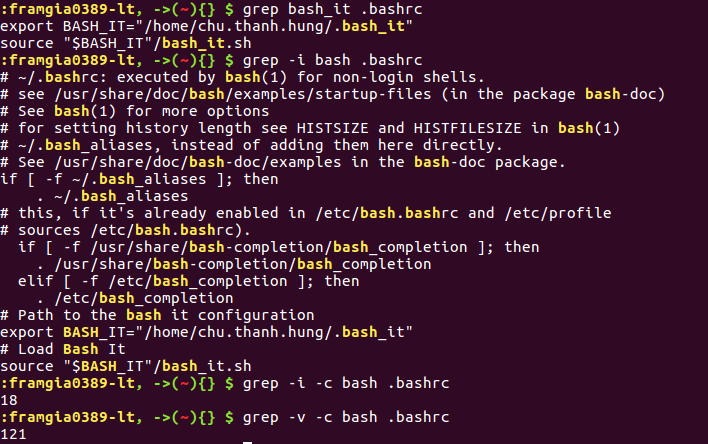
Lệnh grep thường được dùng cho công việc tìm kiếm dữ liệu từ file
Như vậy mình đã giới thiệu qua về kỹ thuật Filtering và một số câu lệnh cơ bản cho kỹ thuật này. Cảm ơn mọi người đã đọc bài viết. Hi vọng mọi người có thể comment các thiếu sót trong bài viết của mình hoặc gợi ý cho mình một vài câu lệnh phổ biến khác để mình có thể hoàn thiện bài viết hơn (thankyou).
- https://ryanstutorials.net/linuxtutorial/filters.php
- https://www.tecmint.com/linux-file-operations-commands
- https://www.ibm.com/developerworks/library/l-lpic1-103-2/index.html
