Timescale postgresSQL Architecture & Concepts
Khái niệm: TimescaleDB là một extension của PostgreSQL, Timescale database chạy bên trong PostgreSQL instance, TimescaleDB nâng cấp các cấu trúc lưu trong PostgreSQL bằng các hook tới query planner, data model, and execution engine. TimescaleDB tối ưu cấu trúc lưu bằng cách chunk các table thành ...
Khái niệm:
TimescaleDB là một extension của PostgreSQL, Timescale database chạy bên trong PostgreSQL instance, TimescaleDB nâng cấp các cấu trúc lưu trong PostgreSQL bằng các hook tới query planner, data model, and execution engine. TimescaleDB tối ưu cấu trúc lưu bằng cách chunk các table thành singular tables gọi là hypertables

Hypertables:
Việc tương tác với dữ liệu sẽ thông qua hypertable, đây là một tập hợp các bảng được chia tách một cách liên tục theo space and time intervals, nhưng việc query chỉ cần thực hiện theo các câu SQL tiêu chuẩn.
Chunk:
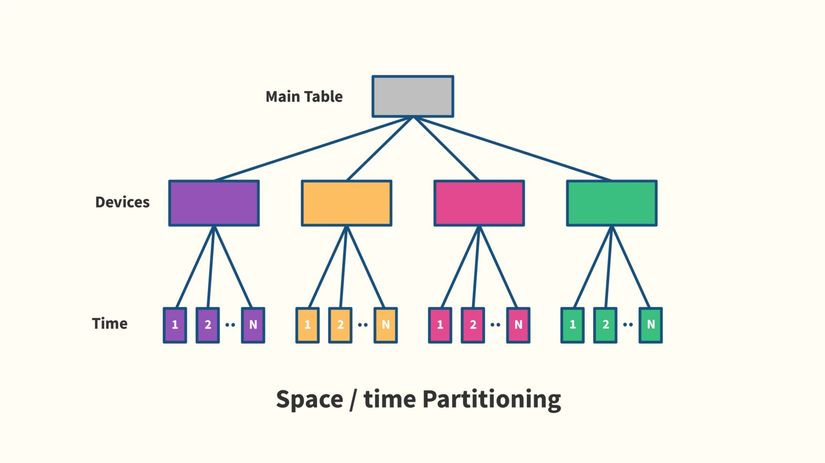
Bên trong, TimescaleDB tự động split mỗi hypertable thành các chunk nhỏ hơn, với mỗi chunk sẽ đối ứng với một time interval và một phân vùng key space xác định (hashing).
Những phần vùng này sẽ không thể trùng nhau, điều đó giúp query tối ưu tập hợp các chunk cho việc giải quyết câu truy vấn.
Mỗi chunk sẽ là một table tiêu chuẩn của sql, hay có thể gọi là "child table" của "parent" hypertable.
Tại sao dùng timescale:
TimescaleDB đề xuất 3 lợi ích chính hơn PostgreSQL thông thường:
- Tỉ lệ insert cao hơn, đặc biệt cho các database có kích thước size lớn.
- Query performance giữ vững khi database scale.
- Hướng tối ưu cho query theo time.
Much Higher Ingest Rates
Đối với PostgreSQL thông thường, performance bắt đầu giảm đáng kể ngay khi indexed tables trở nên quá lớn, ko thể fit được memory và buộc phải lưu xuống đĩa.
TimescaleDB giải quyết việc này bằng việc phần vùng dữ liệu theo time-space, ngay cả khi trên một machine. Tất cả việc write sẽ chỉ viết trên child table có space time gần nhất, một table vẫn tồn tại trong memory, kích thước size nhỏ hơn dẫn tới việc tạo index rất nhanh.
TimescaleDB sử dụng hash partitioning, làm cho việc partitioning dễ dàng phân phát qua một range value giữa các partitions.

Example:
- Đây là một số câu query example, mình không giải thích gì nhiều, vì hầu như nó giống các câu SQL tiêu chuẩn, điểm khác biệt các bạn có thể thấy chính là chúng ta phải luôn luôn chọn mộc range thời gian, lấy thời gian làm gốc.
- Thích hợp với việc group by theo thời gian, dành cho các biểu đồ có 1 trục theo thời gian.
- Lấy thời gian làm gốc, database sẽ chạy distributed query optimizations để xác định lượng chunk cần thiết cho query.
SELECT date_trunc('minute', time) AS minute, max(user_usage)
FROM cpu
WHERE hostname = 'host_1234'
AND time >= '2017-01-01 00:00' AND time < '2017-01-01 01:00'
GROUP BY minute ORDER BY minute;
SELECT date_trunc('hour', time) as hour,
hostname, avg(usage_user)
FROM cpu
WHERE time >= '2017-01-01' AND time < '2017-01-02'
GROUP BY hour, hostname
ORDER BY hour;
SELECT date_trunc('minute', time) AS minute, max(usage_user)
FROM cpu
WHERE time < '2017-01-01'
GROUP BY minute
ORDER BY minute DESC
LIMIT 5;
