Chihuahua hay Muffin và lựa chọn computer Vision API nào tốt nhất mà các developer nên dùng?
Bạn hẳn đã từng thấy quá hình ảnh ở trên với trò chơi phân biệt đâu là chú chó Chihuahua và đâu là chiếc bánh muffin. Với chúng ta thì nó khá dễ dàng đúng không? Nhưng tôi tự hỏi rằng liệu AI có khả năng phân biệt được giữa Chihuahua và Muffin không? Vì mục đích cao cả là giải trí ...

Bạn hẳn đã từng thấy quá hình ảnh ở trên với trò chơi phân biệt đâu là chú chó Chihuahua và đâu là chiếc bánh muffin. Với chúng ta thì nó khá dễ dàng đúng không?
Nhưng tôi tự hỏi rằng liệu AI có khả năng phân biệt được giữa Chihuahua và Muffin không? Vì mục đích cao cả là giải trí cho bạn, hôm nay tôi sẽ tìm hiểu về vấn đề này.
Binary classification đã khả thi ngay từ lúc thuật toán perceptron ra đời vào 1957. Nếu bạn nghĩ rằng AI chỉ có mới đây thôi thì hãng tin tức New York Time, trong năm 1958, cho rằng đây chính là sự bắt đầu cho các máy tính có khả năng nói, đọc viết và thậm chỉ là sinh sản nữa. Tuy vậy, chúng lại chỉ có khả năng nhận biết một vài pattern dễ thấy từ hình ảnh chứ không thật sự có khả năng phân tích ở level phức tạp hơn.
Không có gì là lạ khi cả thế giới thất vọng và trở nên lạnh nhạt với AI. Tuy vậy, kể từ đó, multi-layer perception và convolutional neural network đã vượt xa single-layer perceptions trong nhận diện hình ảnh. Cùng với sự cải thiện trong labeled data set và GPU, các neural network architecture phức tạp như AlexNet, VGG, Inception và ResNet đã đạt được những thành quả đáng ngưỡng mộ.
Nếu bạn là một machine learning engineer, thì rất dễ để bắt đầu thử nghiệm với những model trên nhờ vào pre-trained model trong Keras / Tensorflow hoặc PyTorch. Còn nếu bạn cảm thấy việc tweak neural network quá phiền phức thì có thể dùng tới computer vision APIs, cực kì dễ sử dụng:
- Amazon Rekognition
- Microsoft Computer Vision
- Google Cloud Vision
- IBM Watson Visual Recognition
- Cloudsight
- Clarifai
Cái nào là tốt nhất? Nó hoàn toàn tùy vào mục đích của bạn, product use cases, test data sets cũng như những mục tiêu mà bạn đặt ra.
Dựa trên hình ảnh chihuahua vs. muffin, tôi sẽ phân tích thế mạnh và điểm yếu của chúng.
Thực hiện bài Test
Để làm test, tôi chia hình trên thành 16 phần test image khác nhau và dùng open source code được viết bởi Gaurav Oberoi để đưa ra được kết quả từ các API khác nhau. Từng ảnh được đẩy qua 6 APIs nhắc tới ở trên để đưa ra những phán đoán về chúng. Trường hợp ngoại lệ duy nhất là Microsoft vốn return cả labels, caption và Cloudsight vốn sử dụng công nghệ hybird giữa người-AI để return một caption duy nhất. Đó là nguyên nhân vì sau Cloudsight có thể return các caption cực kì chính xác từ những hình ảnh vô cùng phức tạp nhưng mất tới 10-20 lần khoảng thời gian để xử lí.
Bên dưới là kết quả. Bạn có thể xem list các output của tất cả 16 hình chihuahua vs. muffin bằng cách clicking vào đây.
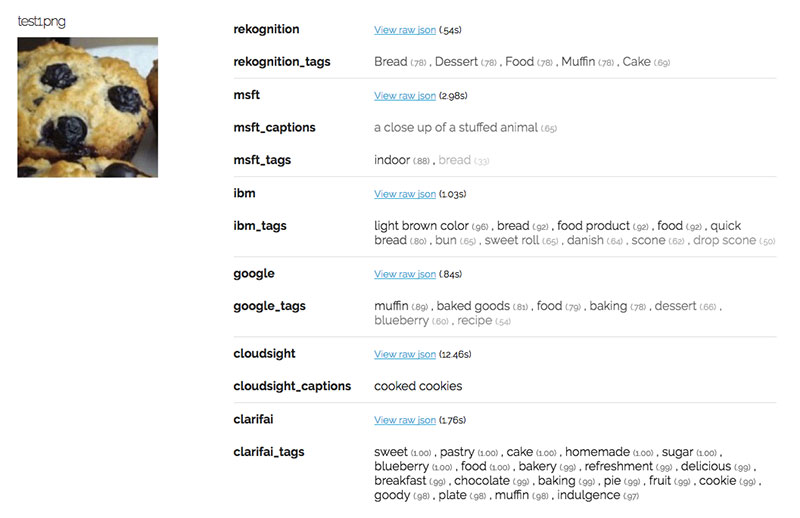
Vậy APIs làm tốt đến mức nào? Chỉ có Microsoft là bị nhầm lẫn chiếc muffin với thú nhồi bông, các API còn lại đều nhận ra bức hình là đồ ăn nhưng không rõ liệu nó là bánh, cookie hay muffin. Duy nhất Google là nhận diện được nó có khả năng cao nhất là muffin.
Giờ hãy xem qua hình của chihuahua: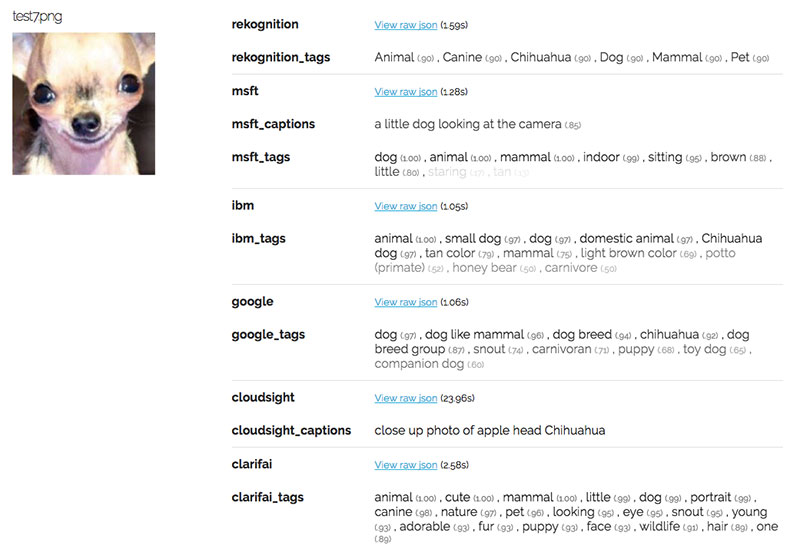
Một lần nữa, các API đều thực hiện rất tốt khi đều nhận biết nó là chó nhưng vẫn có vài nhầm lẫn về giống.
Microsoft thì thật sự fail khi hết cả 3 lần đều nhầm lẫn bánh muffin với thú ngồi bông hoặc gấu Teddy.
Google thì lại là thánh nhận biết muffin khi nhận biết thành công 6 hình trong 7. Các API khác thì có đoán là muffin nhưng không đặt nó ở thứ hạng cao mà thay vào là các label như “bread”, “cookie”, hoặc “cupcake”.
Tuy vậy, Google cũng có fail với một hình muffin nhưng lại cho rằng nó là chó với “dog breed group” và “snout”.
Ngay cả những machine learning platforms tiên tiến nhất cũng gặp khó khăn với thử thách chihuahua vs. muffin! Không có gì ngạc nhiên khi việc một đứa bé cũng có thể đánh bại chúng trong việc nhận biết đồ vật.
Testing với những hình ảnh trong thế giới thực
Với bài test tiếp theo, tôi muốn biết khả năng của API với những ảnh chụp trong cuộc sống hằng ngày luôn chứ không phải là các ảnh được chụp với sự giống nhau như ở trên. Thật trùng hợp là ImageNet có 1750 hình của chihuahua và 1335 hình từ nhiều loại muffin.
Một số ảnh khá là dễ nhận diện bởi những đặc trưng rõ rệt như mặt to, tai nhọn nên các API đều không có vấn đề gì: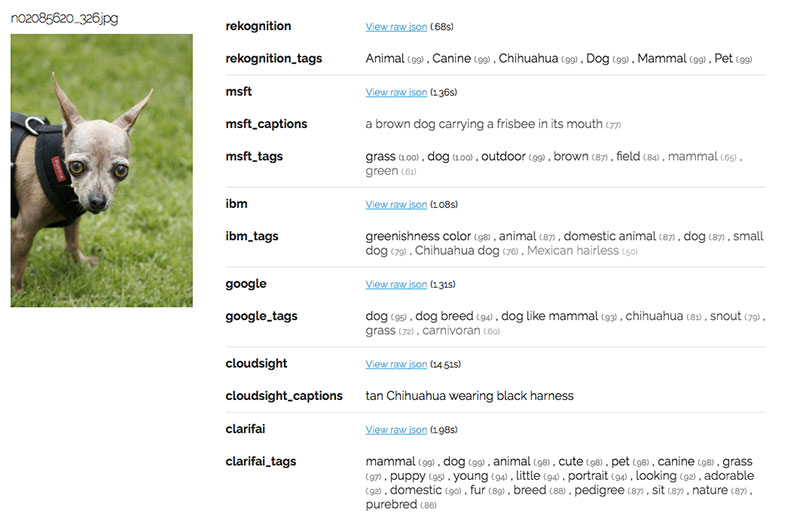
Trong khi số khác khá là khó bởi có nhiều vật trong hình khiến cho API bị nhầm lẫn: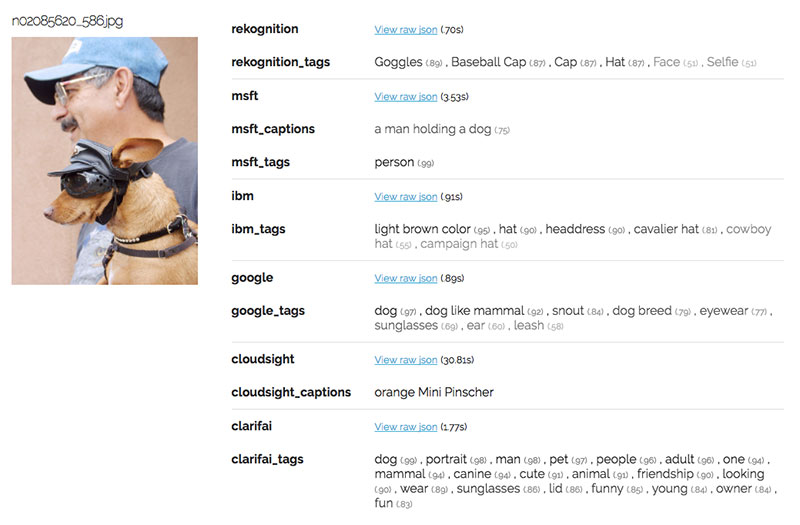
Do chú chó ở hình trên có mang thêm trang phục nên các API không thể biết được giống của nó. IBM Watson thì chỉ nhận diện được nón mũ, kính chứ không hề nêu ra chó hay người trong hình.
Xử lí các “Noisy” Label
Với những data phi cấu trúc, bao gồm hình, người-tagged label thường thiếu chính xác và hay còn gọi là “Noisy”. Sau đây là một ví dụ về bánh muffin: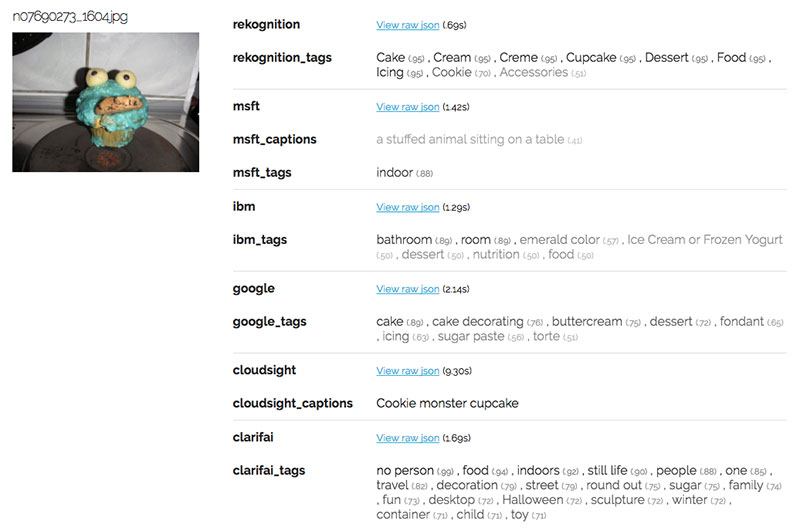
Người nhìn sẽ thấy nó giống với cupcake hơn là muffin. Thật may là các API cũng có đồng ý kiến như vậy với Cloudsight cho ra kết quả chinh xác nhất là “cookie monster cupcake”.
Sử dụng nhiều model và API khác nhau sẽ giúp giải quyết vấn đề về “Noisy” Label. Trong ví dụ này, muffin có rất nhiều loại và hình dáng màu sắc khác nhau nên việc nhầm lẫn là ra dễ.
Chạy nhiều hình ảnh qua các API và loại bỏ những ảnh có phán đoán khác biệt nhất sẽ giúp giảm vấn đề trên.
Một chút nghịch ngợm
Cho vui, tôi thử đánh lừa API với những tấm hình “khó”:
- Ảnh của chihuahua và muffin
- Ảnh của cupcake hình chó
Dưới đây là kết quả APIs cho ra với ảnh của chiahuahua và muffin: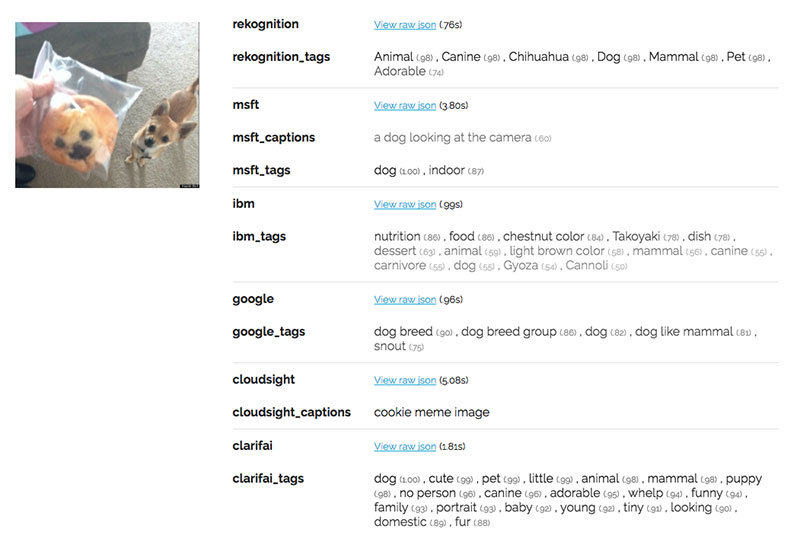
Chỉ có IBM và Cloudsight là có đoán có đồ ăn trong hình nhưng IBM thì có vẻ khá sáng tạo khi còn cho rằng nó là “takoyaki”, “gyoza”, và “cannoli”.
Ảnh của cupcake hình chó cũng gây nhầm lẫn không kém:
Microsoft, vẫn tiếp tục truyền thống, cho rằng chúng là… những con thú nhồi bông. Google thì đoán rằng hình là động vật có vú- chó, còn Clarifai lại quả quyết rằng hình trên vừa có bánh và cả động vật.
Trong những trường hợp phức tạp này, Cloudsight với khả năng phân tích hình dáng con người cho ra kết quả rất chính xác với “12 chiếc bánh cupcake hình chú chó”
Vậy API nào là tốt nhất?
Mặc dù bạn không thể xác định rõ ràng API nào là tốt nhất nhưng rõ ràng ta có thể thấy sự khác biệt giữa chúng.
Amazon Rekognition
Amazon Rekognition không chỉ giỏi xác định vật thể chính mà nó vẫn giữ phong độ rất tốt khi gặp hình với nhiều vật thể. Khả năng đánh giá của Amazon Rekognition cũng khá tốt với những nhận xét như dễ thương, cute. Có thể thấy API này khá là cân bằng khi vừa tốt trong nhận diện lẫn đưa ra đánh giá.
Google & IBM
Cả hai đều cực kì rõ ràng và chi tiết, có thể nói là thẳng như ruột ngựa khi miêu tả rất rõ ràng về vật trong hình. Cả hai đều thể hiện rất tốt nhưng IBM nhỉnh hơn khi đưa ra nhiều phán đoán hơn một chút.
Microsoft
Kết quả của Micrsoft thường rất chung như trong ví dụ trên, nó chỉ nhận diện là chó, bánh chứ không hề thêm chi tiết rõ ràng như giống gì cũng như là loại bánh.
Cloudsight
Là sự kết hợp giữa cả tag bởi người và machine labeling nên nó có tốc độ xử lí chậm hơn hẳn so với các API khác nhưng bù lại kết quả cho ra với những hình phức tạp thì cực kì chính xác.
Clarifai
API có lượng phán đoán và tag nhiều nhất. Từ chung chung như động vật, bánh cho đến cả chi tiết như Chihuahua hay muffin đều có trong Clarifai. Không chỉ thế nó còn đính kèm cả những tag miêu tả khá trừu tượng. Do đó nếu bạn muốn miêu tả hình ảnh một cách chi tiết thì API này khá là tuyệt.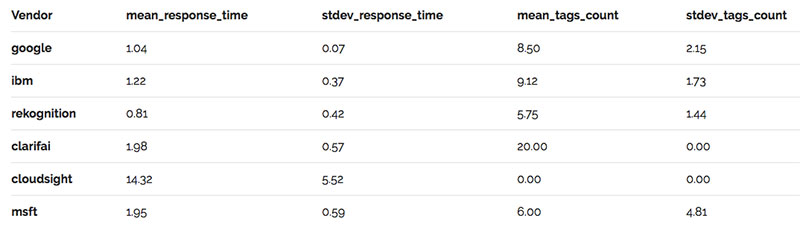
Sau đấy là bản giá của các API cho từng hình:
- Amazon – $0.001/ vài triệu ảnh
- Microsoft – $0.001/ vài triệu ảnh
- IBM Watson – $0.002 / vài triệu ảnh
- Google Cloud – $0.0015 / vài triệu ảnh
- Cloudsight – $0.02 / 30,000 ảnh
- Clarifai – $0.0015 / vài triệu ảnh
Không có gì ngạc nhiên khi Cloudsight mắc nhất với tận $0.02 / 30,000 ảnh. Tuy vậy, nếu các bạn chỉ dùng cho vài ngàn hình thì các API cũng sẽ mắc hơn, có khi lên tới $0.07.
Techtalk via Topbot
