Cải thiện Performance với các Background jobs tốt hơn
Nó không phải là một điều bất thường khi chúng ta suy nghĩ về mở rộng như một điều dễ dàng có thể đạt được. Ví dụ như dịch vụ Heroku có thể cung cấp thêm resources cho ứng dụng của chúng ta như RAM, CPU một cách dễ dàng chỉ thông qua vài bước click. Tuy nhiên, trong khi nâng cấp infrastructure là ...
Nó không phải là một điều bất thường khi chúng ta suy nghĩ về mở rộng như một điều dễ dàng có thể đạt được. Ví dụ như dịch vụ Heroku có thể cung cấp thêm resources cho ứng dụng của chúng ta như RAM, CPU một cách dễ dàng chỉ thông qua vài bước click. Tuy nhiên, trong khi nâng cấp infrastructure là một lựa chọn hợp lệ, thì tôi tin rằng hầu hết các ứng dụng có thể mở rộng chỉ với việc làm cho mã code của mình tốt hơn. Dưới đây là một vài típ để sử dụng nguồn tài nguyên một cách hiệu quả hơn, và có thể nó sẽ tiết kiệm cho dự án của bạn một số tiền.
Hãy luôn để ý tới background jobs của bạn
Có thể bây giờ bạn đang dùng một số tool để xử lý các tiến trình ở background và nó thật sự là tốt. Điều này có nghĩa là ứng dụng của bạn có thể cung cấp response times tốt hơn bằng cách ủy quyền các nhiệm vụ tính toán cho background job.
Response times thấp có nghĩa là bạn sẽ có được thông lượng (throughput) cao, do đó đối với mỗi server của bạn có thể xử lý được nhiều yêu cầu mỗi phút hơn. Vì vậy máy chủ của bạn đã được mở rộng. Nhưng các worker của bạn làm việc như thế nào? Làm sao để chúng có thể đáp ứng tất cả các yêu cầu?
Nếu không có sự tiếp cận đúng, thì câu trả lời đơn giản là: Không phải cho vào background là tốt (nếu không biết quản lý nó). Với ý nghĩ đó, tôi sẽ show cho mọi người thấy cách mà team tôi quản lý refactor từ một kiến trúc non-scalable background job, kiến trúc này cho thấy sự tin cậy và giữ cho việc sử dụng các nguồn tại nguyên ở mức tối thiểu.
Trước tiên, để tối ưu hóa ứng dụng của bạn, bạn sẽ cần phải đo lường một cách kĩ lưỡng. Số liệu chính là vũ khí quan trọng và hữu ích trong khi vũ khí của bạn khi tối ưu hóa, và hãy nhớ điều này. Tôi thường lựa chọn New Relic cho các số liệu thống kê, tuy nhiên chúng ta cũng có rất nhiều lựa chọn khác nhau.
Điều gì đang xảy ra trong production?
Yêu cầu về tính năng khấ là đơn giản, gửi email tới danh sách tất cả các user đã subcribed với nội dung mà họ đã quan tâm. Trông nó thật dễ dàng đúng không! Việc của chúng ta là query tất cả những subcribed users, thu thập nội dung cho từng email và gửi chúng đến địa chỉ cần nhận. Nhiệm vụ này là đơn giản và họ có thể viết đoạn mã dễ dàng, nó được gửi đi mỗi ngày 1 lần.
class ContentSuggestionWorker include Sidekiq::Worker def perform users = User.where(subscribed: true) users.each { |user| ContentMailer.suggest_to(user).deliver_now } end end
Chúng tôi đã thử nghiệm nó trên môi trường development và performed có vẻ tốt. Sau đó chúng tôi triển khai chúng trên môi trường production, chỉ để khám phá ra một cái gì đó sai lầm ngay khi worker bắt đầu chạy. Heroku khóc thét với lỗi R14 (vượt quá hạn ngạch bộ nhớ), từ thời điểm đó một loạt các lỗi đều được hiện thị. Điều gì đó có thể đã sai chăng?
Chúng ta hãy nhìn vào số liệu thống kê trên Heroku, vấn đề lớn nhất của chúng ta có vẻ như là về việc tiêu thụ bộ nhớ. Lỗi R14 là một tin xấu bởi vì ứng dụng sẽ bắt đầu sử dụng bộ nhớ trao đổi có nghĩa là chúng ta sẽ không còn bộ nhớ RAM. Swapping trên Heroku là chậm và có khả năng sẽ dẫn đến thất bại.
Ok, giờ chúng ta sẽ làm sạch mớ hỗn độn này
Để giải quyết đúng đắn vấn đề này, chúng tôi đã cố gắng thiết lập môi trường development giống production nhất có thể. Một cách đơn giản: Chạy server của bạn bằng cách sử dụng flag là production, thiết lập các biến môi trường như nhau nếu có thể và đừng quên import database dump.
Hầu hết, trong khi chạy thử nghiệm trên môi trường development, bạn có thể nhận được những thông tin hữu ích bằng cách sử dụng unix top command, nó sẽ hiện thị rất nhiều số liệu cho process đang chạy, nhưng bạn hãy tập chung vào memory.
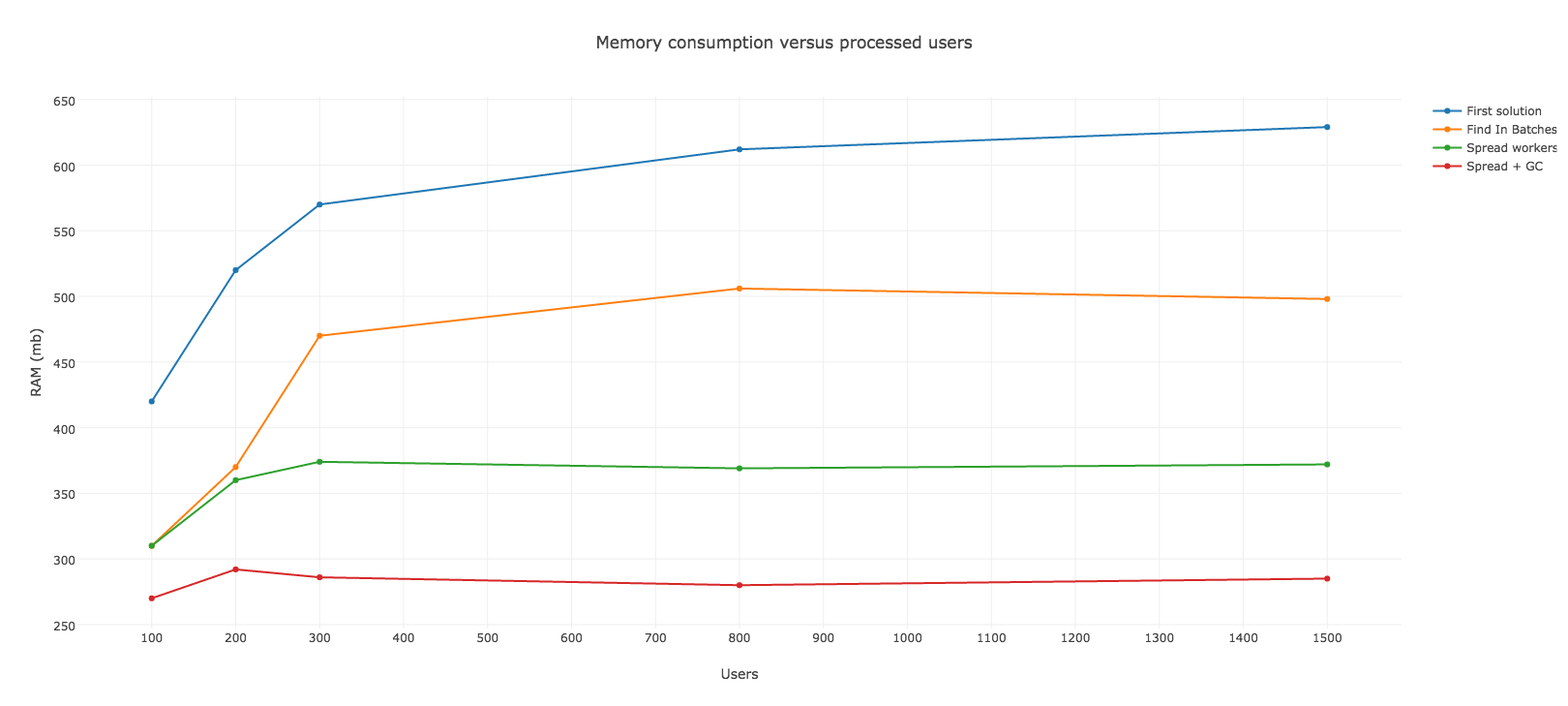
Vì vậy chúng tôi bắt đầu chạy ứng dụng và theo dõi nó. Thời điểm bắt đầu memory tăng lên một cách nhanh chóng, tiêu tốn khoảng 520mb của RAM chỉ với 200 users đang xử lý. Nó vẫn tiếp tục đi lên sau một nghìn xử lý mặc dù tốc độ tăng chậm.
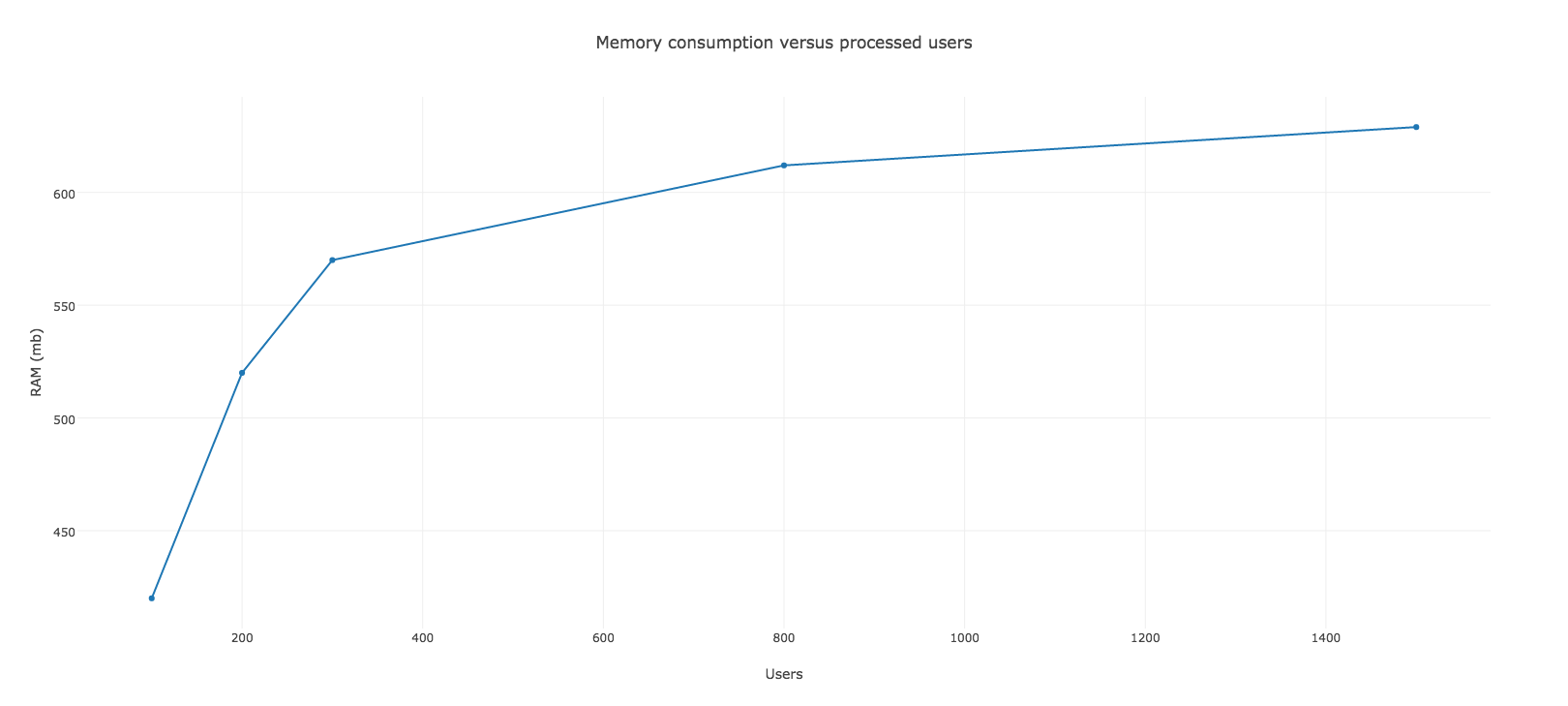
Vì vậy không có nghi ngờ lý do tại sao chúng ta lại gặp rắc rối trên Heroku như vậy. Nếu có khoảng 200 người thì bộ nhớ RAM là đủ để xử lý và bắt đầu swapping. Trước khi worker khởi động tôi đã đặt cược nó chạy được hơn 800 users nhưng sự thật không phải như vậy.
Cùng xem xét đến các đối tượng khởi tạo
Vâng, tôi đang nhìn vào ActiveRecord. Truy vấn tất cả người dùng subcribed rõ ràng không phải là một ý tưởng tốt. Nhưng chúng ta có một cách dễ dàng hơn của ActiveRecord cung cấp đó là find_in_batches method. Hơn nữa, bạn có thể set batch size cho nó và thử nghiệm các kích thước khác nhau. Mặc định ActiveRecord để là 1000.
Tóm tắt sơ qua, xử lý hàng loạt cho phép bạn làm việc với các records theo đợt (batches), do đó sẽ khởi tạo đối tượng ít hơn và làm giảm mức tiêu thụ bộ nhớ đáng kể. Với phương thức tiện dụng đó, chúng ta có thể viết lại background job và đã nhận được kết quả tốt hơn. Sử dụng batch size là 100 cho phép chúng ta sử dụng RAM dưới 512mb và nó không bị quá bộ nhớ đối với Heroku của chúng ta.
Code mới và biểu đồ mới sẽ như sau:
class ContentSuggestionWorker include Sidekiq::Worker def perform User.where(subscribed: true).find_in_batches(batch_size: 100) do |group| group.each { |user| ContentMailer.suggest_to(user).deliver_now } end end end
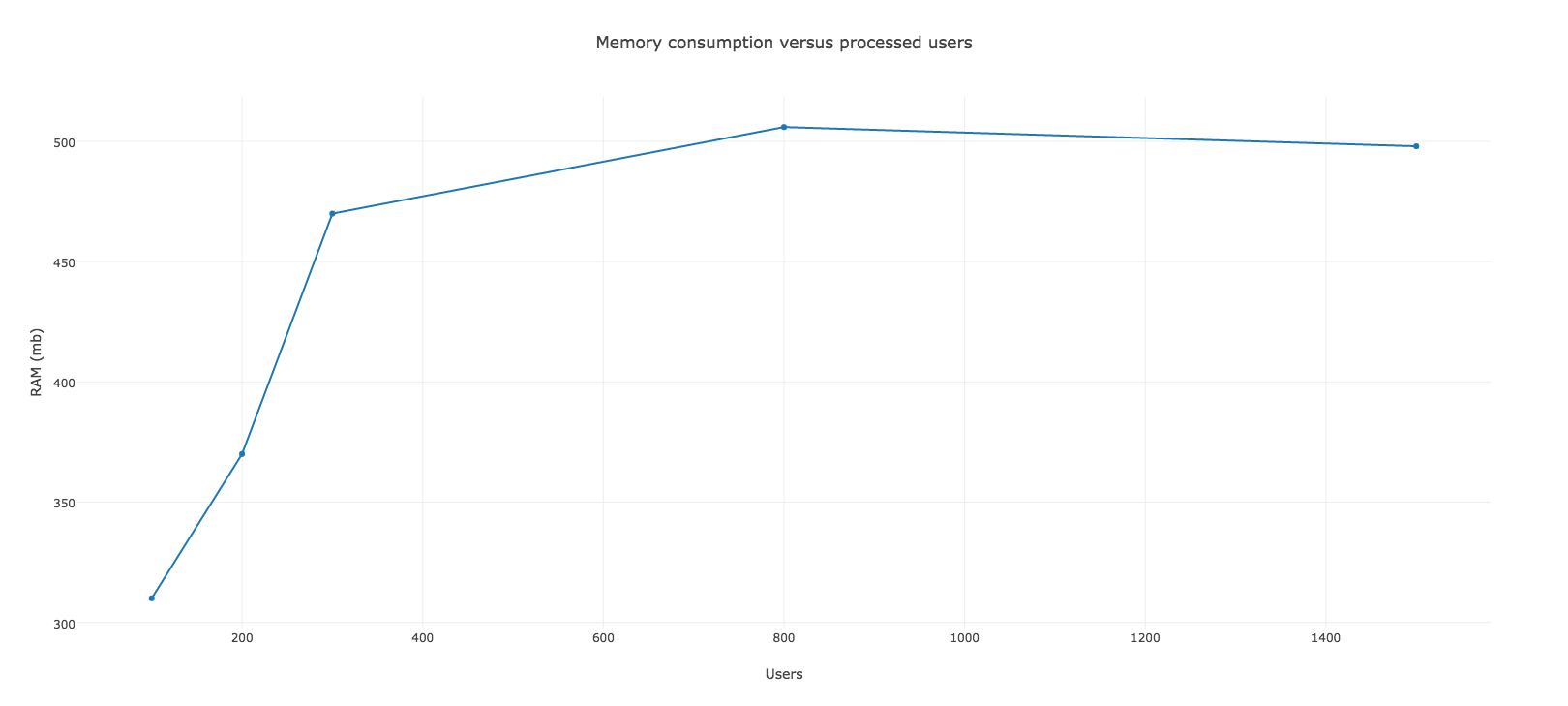
Như bạn đã thấy chúng ta đã có một sự cải thiện rõ rệt và có lẽ nó sẽ chạy tốt trên môi trường production. Bộ nhớ tiêu thụ ổn định và dường như nó không tốn nhiều hơn 512mb. Nhưng chúng tôi biết chúng tôi có thể làm tốt hơn, mặc dù nó đang ở ngưỡng giới hạn như vậy là không đủ tốt và an toàn.
Liệu thiết kế background job như vậy là ổn?
Bạn có thể thấy background job của chúng ta làm việc khá nhiều. Nó lấy tất cả người dùng subcribed và gửi mail đến tất cả những người đó. Với ý nghĩ đó, chúng tôi đã tiến tới một kiến trúc mới: Thay vì một worker lớn làm tất cả những việc đó, chúng tôi chọn có hàng trăm cái nhỏ làm chỉ một điều duy nhất.
Những điều chúng ta có bây giờ sẽ là đối với mỗi user chúng ta sẽ có một worker riêng để gửi mail. Phương pháp mới này có một số lợi ích cho khả năng mở rộng. VÍ dụ, ứng dụng của bạn có rất nhiều loại công việc background khác nhau, chạy random mỗi khi user tương tác với ứng dụng của bạn. Nếu chỉ có 1 worker khổng lồ đang làm việc trong một thời gian dài tùy thuộc và resource của bạn mà có thể bạn sẽ không còn chỗ trống cho công việc đó dẫn tới nó phải xếp vào hàng đợi có thể gây ra lỗi cho ứng dụng của bạn.
Vâng, chúng ta có thể cải thiện việc này bằng cách sử dụng một phương pháp khác của ActiveRecord là pluck. Nó cho phép chúng ta lấy ra một mảng các id của users thay vì lấy ra các object users, và pass chúng và một worker khác có tên ContentSuggestionWorker. Vì vậy chúng ta cần viết một worker khác.
class ContentSuggestionEnqueuer def self.enqueue User.where(subscribed: true).pluck(:id).each do |user_id| ContentSuggestionWorker.perform_async(user_id) end end end
class ContentSuggestionWorker include Sidekiq::Worker sidekiq_options retry: false def perform(user_id) user = User.find(user_id) ContentMailer.suggest_to(user).deliver_now end end
Một điều thú vị về worker đặc biệt này là chúng ta có thể sử dụng tùy chọn retry. Vì mỗi một worker xử lý riêng biệt một user nên khi có lỗi xảy ra nó cũng chỉ ảnh hưởng đến mỗi user đó thôi và có thể retry cho user đó nên không ảnh hưởng đến cả tiến trình.
Việc thiết lập Sidekiq không retry khi mà có lỗi xảy ra thực sự là sẽ không tốt, vì ta có rất nhiều user cùng chạy trong một tiến trình, đang chạy giữa chừng thì tiến trình fail như vậy sẽ có rất nhiều user không nhận được mail, mà nếu ta thực hiện retry cả tiến trình đó thì những user đã nhận được mail trước đó sẽ nhận được mail trùng lặp. Nên việc tách chúng ra là một phương pháp tốt
Và đây là kết quả thu được với sự thay đổi này
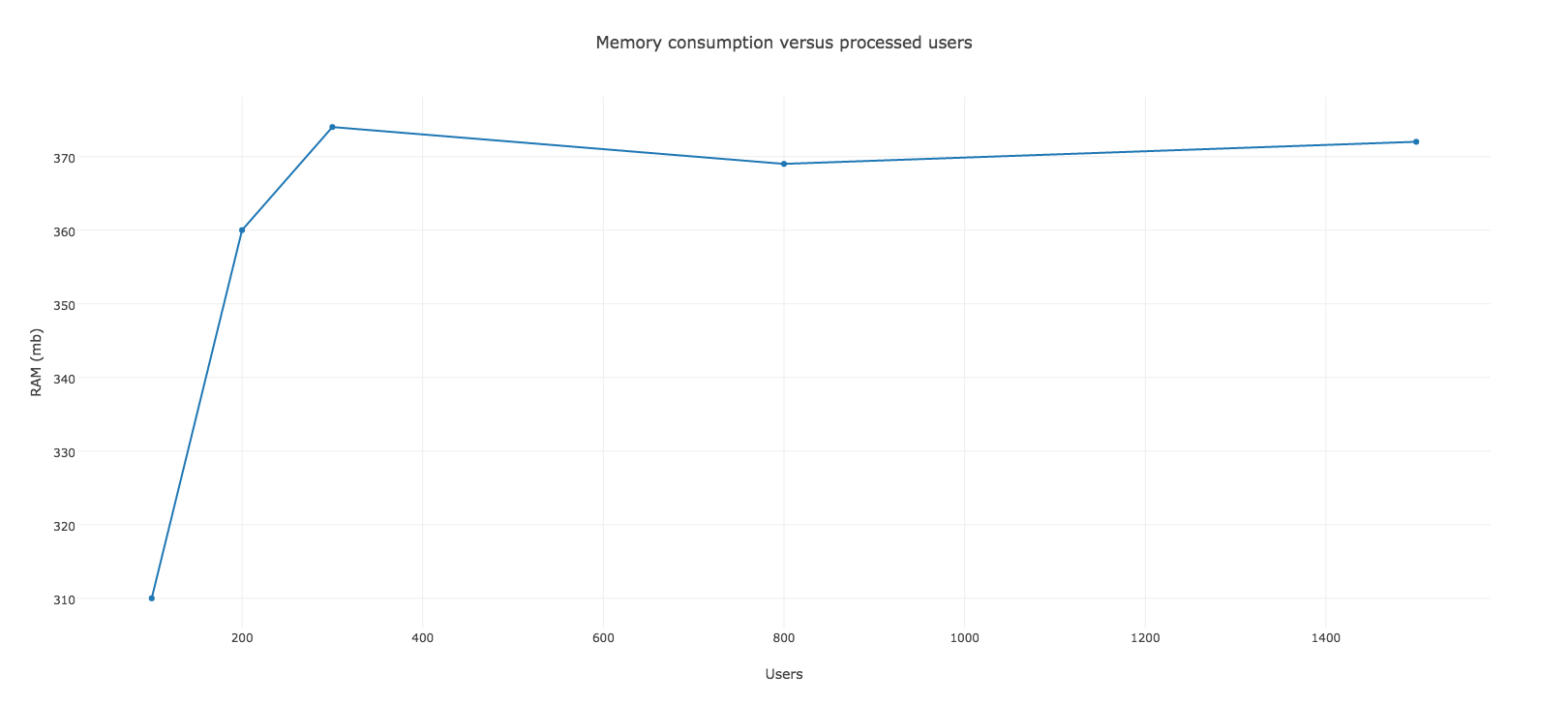
Bộ nhớ tối đa mà nó tiêu thụ rơi vào khoảng 372mb, đã tốt hơn nhiều so với trước đó. Chúng ta không còn nhận được gần mốc 512mb. Nhưng dường như chúng ta còn chưa xong việc, nhìn vào kết quả chúng ta có những manh mối cho việc tiếp theo mà chúng ta sẽ làm.
Thu thập những thứ không cần thiết
Việc tạo ra nhiều worker cho phép Garbage Collector (thu thập những thứ không cần thiết) để làm việc tốt hơn, giải phóng một số không gian bộ nhớ sử dụng trên heap. Lý do là những objects liên quan đến worker có thể được giải phóng ngay khi nó kết thúc công việc. Điều này sẽ làm giảm tiêu thụ bộ nhớ cho giải pháp cuối cùng của chúng ta.
Trong ý định này, chúng tôi quyết định dùng đến Garbage Collector, mỗi khi thực hiện xong chúng ta sẽ dùng GC quét, và hãy xem cách nó thực hiện như sau:
class ContentSuggestionWorker include Sidekiq::Worker sidekiq_options retry: false def perform(user_id) user = User.find(user_id) ContentMailer.suggest_to(user).deliver_now GC.start end end
Kết quả sẽ như sau:
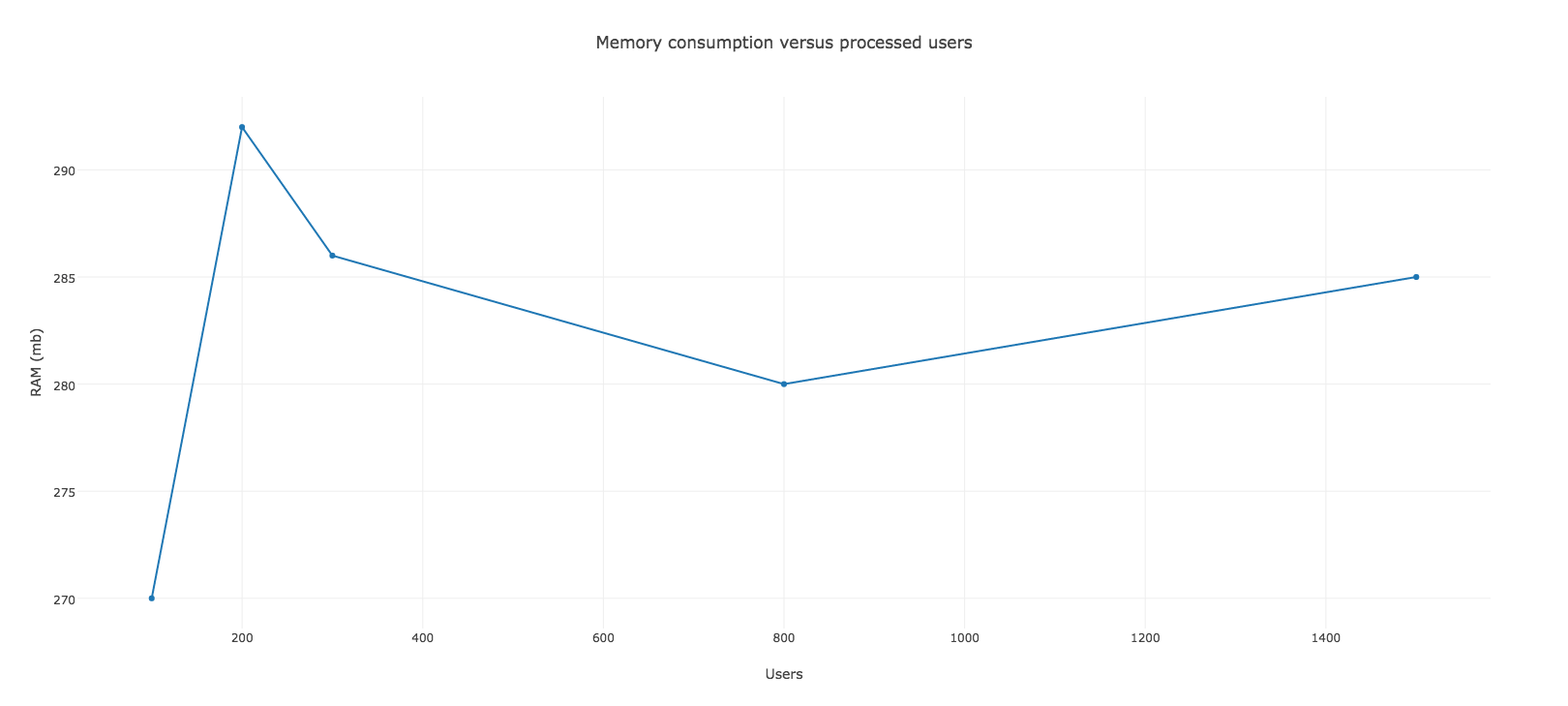
Đó là tất cả những gì chúng ta cải thiện được . Công việc của chúng ta hiện tại tiêu thụ bộ nhớ dưới 300mb, để lại chỗ cho những xử lý khác. Tôi nghĩ nhiều người sẽ nghĩ rằng quét GC mọi lúc như vậy không phải là ý tưởng tốt. Vâng tôi cũng đồng ý với quan niệm đó, đây chỉ là ví dụ cho thấy các giải pháp chúng ta có thể sử dụng. Bạn cũng có thể thử với cách khác với việc quét GC ít hơn và đừng quên đo lường nó.
Cuối cùng nó có thể là một ý tưởng tốt là pass user_id vào ContentMailer. Bằng cách này chúng ta tránh qua các arguments phức tạp, và nó là một trong những best practice trong sidekiq worker.
Tổng kết
Với những thay đổi đơn giản trong mã code, chúng ta có thể cải hiện cả performance và memory. Hãy xem biểu đồ để thấy được sự khác nhau của các giải pháp chúng ta đã nói ở trên