Dành 2 năm khắc phục sự cố Google Photos nhận nhầm người da màu là… khỉ đột nhưng AI của Google vẫn gây thất vọng
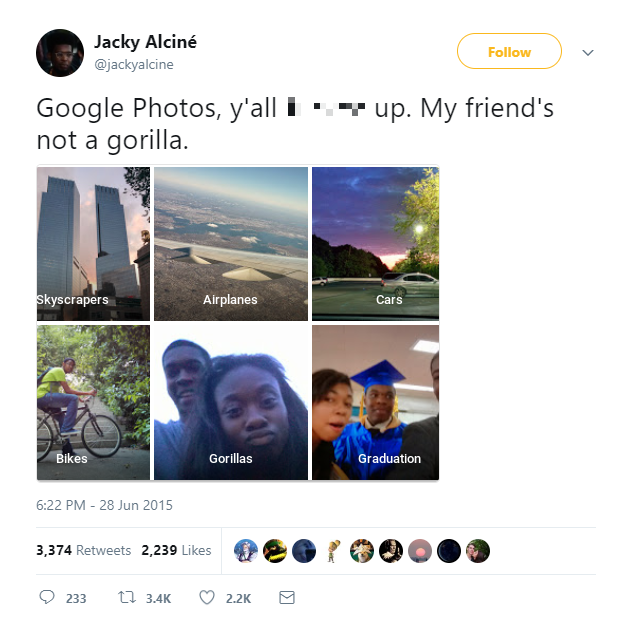
Năm 2015, một nhà phát triển phần mềm của Google đã đăngtrên Twitter rằng dịch vụ nhận dạng ảnh của Google đã nhận định nhầm anh và người bạn (cũng da màu) là “hai con khỉ đột”. Google đã có lời xin lỗi sâu sắc đến cá nhân người bị xúc phạm, và hứa sẽ lên kế hoạch khắc ...

Năm 2015, một nhà phát triển phần mềm của Google đã đăngtrên Twitter rằng dịch vụ nhận dạng ảnh của Google đã nhận định nhầm anh và người bạn (cũng da màu) là “hai con khỉ đột”.
Google đã có lời xin lỗi sâu sắc đến cá nhân người bị xúc phạm, và hứa sẽ lên kế hoạch khắc phục sự cố này, nhãn “khỉ đột” sẽ không được sử dụng để gắn vào một nhóm người nữa, và Google “đã đang tiến hành sửa chữa lỗi đó trong tương lai gần”.
Đến thời điểm đầu năm 2018 này, chúng ta kỳ vọng sẽ nhìn thấy Google sữa chữa lỗi lầm cách đây 2 năm. Nhưng cách sửa chữa mà Google áp dụng là: họ xóa luôn nhãn khỉ đột (cũng một số loài linh trưởng khác) khỏi cơ sở dữ liệu nhận dạng hình ảnh.
Điều này thật sự khiến những người yêu mến Google ( trong đó có tôi) cảm thấy thất vọng. Họ đang cho thất sự bất lực trong việc áp dụng công nghệ nhận dạng khuôn mặt nhận dạng tiên tiến lên đủ các thứ công nghệ như xe tự lái, trợ lý ảo, …
Phóng viên tạp chí WIRED thử nghiệm Google Photo với một bộ sưu tập ảnh bao gồm 40.000 tấm ảnh động vật.
Họ có một kết quả ấn tượng: Google Photo có thể có thể trả lại kết quả của vô vàn con vật, nhưng dịch vụ này đều báo “không kết quả” với những từ khóa “gorilla – khỉ đột”, “chimpanzee – vượn”, “chimp – viết tắt của chimpanzee” và “monkey – khỉ”.
Google Photo hiện có trên cả ứng dụng di động và nền tảng web, cung cấp cho 500 triệu người dùng nơi để lưu trữ ảnh cá nhân của mình.
Nó dùng công nghệ machine learning để tự động “nhóm” những ảnh có nội dung tương tự với nhau lại, ví dụ như “động vật”, “ao hồ”, “quần áo” v.v… Đây cũng là công nghệ cho phép người sử dụng tự tìm thấy bộ sưu tập ảnh cá nhân của mình.
Trong bài thử của phóng viên WIRED, Google Photo cũng đưa ra một số hình ảnh loài linh trưởng. Đơn cử như “baboon – khỉ đầu chó”, “gibbon – (một loài) vượn”, “marmoset – khỉ đuôi sóc”. Chỉ cần tìm tránh từ monkey – khỉ ra là mọi thứ lại đâu vào đấy.
Trong một bài thử khác nữa, phóng viên WIRED đã tải lên 20 tấm ảnh về vượn và khỉ đột từ một nguồn mở khác. Một số hình ảnh vẫn có thể tìm lại được với những từ khóa như “forest – rừng”, “jungle – rừng rậm”, “zoo – sở thú”, nhưng lũ khỉ còn lại vẫn bặt vô âm tín.
Kết luận lại, ta thấy rằng với Google Photo thì khỉ đầu chó vẫn là khỉ đầu chó, nhưng khỉ thì không phải là khỉ, còn khỉ đột và vượn thì biến mất.
Trong bài thử thứ ba, phóng viên WIRED muốn xem Google Photo nhìn thấy gì khi nhận mặt con người. Họ đăng tải lên đó một bộ ảnh gồm 10.000 tấm hình vốn được dùng trong nghiên cứu nhận dạng khuôn mặt.
Cụm từ “African american – người Mỹ gốc Phi” cho ra kết quả một con linh dương trên đồng cỏ.
Với cụm từ “black man – anh da đen”, “black woman – cô da đen”, “black person – người da đen” thì Google Photo trả về ảnh đen trắng của người thật, hình ảnh đều được phân loại đúng giới tính nhưng không thỏa mãn yêu cầu “màu da”.
Chỉ khi tìm cụm từ “afro – chỉ bộ tóc xoăn xù của người da màu” và “African – người gốc Phi” thì Google Photo mới trả đúng hình ảnh người da màu. Tuy nhiên, kết quả vẫn lẫn lộn không chính xác.
Người phát ngôn của Google xác nhận rằng cụm từ “gorilla – khỉ đột” đã bị lọc đi khỏi hệ thống tìm kiếm sau sự cố năm 2015, những từ khác như “chimpanzee – vượn” hay “monkey – khỉ” cũng chịu chung số phận.
“Công nghệ dán nhãn hình ảnh dựa vào nội dung vẫn còn trong giai đoạn đầu phát triển và đáng buồn là còn lâu nó mới hoàn hảo được“, người phát ngôn phía Google nói thêm.
Việc Google rất cẩn thận trong khâu nhận dạng hình ảnh này cho thấy công nghệ machine learning hiện tại vẫn còn hạn chế lắm. Với đủ dữ liệu và với một sức mạnh tính toán vượt trội, phần mềm có thể phân loại hình ảnh chính xác hoặc nháu lại lời nói tới một mức độ cao.
Tuy nhiên, nó chưa đi được quá xa. Thuật toán khéo léo nhất thời điểm hiện tại cũng chưa thể có được một nhận định giống của con người.
Như một lẽ tất yếu, những nhà phát triển machine learning phải rất cẩn thận khi đưa sản phẩm của mình ra công chúng: vẫn còn những góc khuất mà các bài tập huấn luyện nhận dạng chưa dạy được cho thuật toán.
“Rất khó để tạo khuôn mẫu cho mọi thứ hệ thống sẽ gặp phải trong đời thực“, Vicente Ordóñez Román, giáo sư tại Đại học Virginia nhận định.
Lỗi không hoàn toàn nằm ở Google, khi mà bản thân những tấm ảnh được đưa lên Google Photo cũng không hoàn hảo. Người dùng đăng ảnh với mọi loại điều kiện ánh sáng, góc nhìn, … Xét tới lượng ảnh nằm trong cơ sở dữ liệu, thì việc “nhầm nhọt” khỉ với người gần như là SẼ xảy ra.
Nhiều công ty lớn khác, trong số đó có cả công ty mẹ của Google là Alphabet, đối mặt với trở ngại này ở một mức độ cao hơn nhiều. Có thể nói đến ví dụ dễ thấy nhất là xe tự lái.
Sau nhiều nghiên cứu, đã có những tiến bộ nhất định nhưng các nhà nghiên cứu, trong đó có cả giáo sư Román, thì vẫn chưa rõ cách thức vượt qua những giới hạn của hệ thống.
Vẫn có một vài hệ thống machine learning của Google có khả năng phát hiện ra khỉ đột ngoài đời thực. Ví dụ như dịch vụ có tên Cloud Vision API của họ vẫn nhận dạng được “khỉ đột” và “vượn” khi xem ảnh của chúng. Thậm chí độ chính xác cũng vẫn rất cao. Bạn có thể xem ở hình dưới.
Hệ thống thường thấy nhất của Google là Google Assistant – trợ lý ảo sinh ra để đáp trả lại Siri của Apple – cũng vẫn có thể xác định được khỉ đột: nó vẫn đủ tự tin để không nhầm hình ảnh loài linh trưởng này thành một người da màu.
Thế mà, hệ thống Google Lens được Google quảng bá là “tiến bộ vượt bậc trong công nghệ thị lực máy tính” thì lại nhìn tấm ảnh khỉ đột, gãi cằm một lúc rồi nói rằng “Hmm … chưa nhìn rõ được ảnh này là ảnh gì”.
Techtalk via Dailymail
