Elixir và Unicode, Phần 2: Làm việc với Unicode Strings
Đây là bài dịch tiếp theo trong series về Elixir và Unicode của tác giả Nathan Long , Các bạn có thể đọc phần 1 tại đây Bài gốc: Part 1 | Part 2 Trong bài viết trước, tôi đã đưa ra những khái niệm cơ bản về việc hỗ trợ Unicode trong Elixir: mỗi string trong Elixir là một chuỗi các codepoint, ...
Đây là bài dịch tiếp theo trong series về Elixir và Unicode của tác giả Nathan Long, Các bạn có thể đọc phần 1 tại đây
Bài gốc: Part 1 | Part 2
Trong bài viết trước, tôi đã đưa ra những khái niệm cơ bản về việc hỗ trợ Unicode trong Elixir: mỗi string trong Elixir là một chuỗi các codepoint, được mã hoá UTF-8. Tôi đã giải thích Unicode là gì và chúng ta đi qua các bước của quá trình encode và thấy được chính xác từng bit được tạo thành như thế nào.
Ở bài viết này, điều quan trọng chúng ta cần biết đó là: UTF-8 biểu diễn codepoint bằng 3 loại byte. Nhữnh codepoint lớn hơn sẽ gồm 1 leading byte và theo sau đó là 1, 2, 3 continuation byte, và leading byte sẽ cho chúng ta biết còn bao nhiêu continuation byte đằng sau nữa. Những codepoint nhỏ hơn thì chỉ cần 1 solo byte thôi là đủ.
Mỗi kiểu byte sẽ có pattern khác nhau và bằng cách sử dụng pattern đó, Elixir có thể làm chính xác rất nhiều thứ mà các ngôn ngữ khác làm sai, ví dụ như việc đảo chuỗi. Chúng ta cùng xem thử nhé.
Giả sử là chúng ta cần đảo chuỗi a™. Elixir sẽ biểu diễn chuỗi này ở dạng binary gồm có 4 bytes: a được biểu diễn bằng 1 solo byte, ™ được biểu diễn bằng 3 bytes (1 leading byte và 2 continuation bytes)
Để cho đơn giản, ta có thể biểu diễn bằng ảnh sau:

Bạn sẽ không muốn đảo ngược các byte như dưới đây, làm sai thứ tự của các byte trong ™:

Thay vào đó, bạn cần đổi như sau, giữ đúng thứ tự các byte:

Elixir làm đúng việc này, nhờ vào việc sử dụng UTF-8, Elixir có thể biết các byte nào nên đi cùng với nhau. Điều này cũng giúp Elixir có thể tính toán đúng chiều dài của chuỗi, lấy chuỗi con dựa vào index vì ta biết được là các byte nào sẽ đi với nhau, và biết được, ví dụ, 3 byte đầu tiên là biểu diễu của 1 kí tự hay là 3 kí tự.
OK, đây mới chỉ là 1 phần của vấn đề. Vẫn còn 1 lớp nữa mà chúng ta cần xem xét.
Chúng ta không chỉ có nhiều byte trong cùng 1 codepoint mà chúng ta có thể có nhiều codepoint trong cùng một grapheme. Một grapheme là thứ mà mọi người 1 kí tự mà ta nhìn thấy, ví dụ như "một ký tự với dấu trọng âm hay là chữ á này chẳng hạn. Nhưng kí tự đó, ở bên dưới có thể là kết hợp của 1 chữ a thông thường (plain letter) ghép chồng với dấu sắc (combining diacritical mark). Nghĩa là: hãy đặt chồng dấu này lên kí tự đằng trước. Mỗi chuỗi các codepoint biểu diễn duy nhất một grapheme khi đó được gọi là một grapheme cluster.
noel = "noeu0308l" # => "noël" String.codepoints(noel) # => ["n", "o", "e", "̈", "l"] String.graphemes(noel) # => ["n", "o", "ë", "l"]
Chú ý là Elixir cho phép chúng ta truy vấn cả codepoint lẫn grapheme trong chuỗi đó.
Lúc này bạn có thể muốn hỏi: Nếu tôi có thêm 1 dấu thì liệu tôi có thể thêm 2 được không ? Tôi có thể thêm bao nhiêu dấu tất cả ???

Câu trả lời là bạn có thể thêm cả đống cũng không sao hết.

Có thể bạn đã nhìn thấy zalgo text, ở một số trang web thiết kế chưa tốt, khi mà text box bị overflowed bằng các đoạn text này, chủ nhân của các trang này đã nghĩ là họ đã bị hack =)). Bạn có thể thấy trên StackOverflow câu hỏi làm sao để ngăn chặn việc này và kèm theo là zalgo comment.
Thật không may là không có một cách đơn giản để ngăn cản mọi người thêm cái này vào trang của bạn. Zalgo text không phải là bug, đơn giản nó là một tính năng bị dùng sai mục đích.
Hãy nhớ là Unicode đang cố để bao phủ hết tất cả ngôn ngữ của loài người. Nó hỗ trợ viết từ trái qua phải, hoặc từ phải qua trái, hỗ trợ chấm câu đặc biệt của ngôn ngữ Java để dùng viết thư cho người nhiều tuổi hơn hoặc có vai vế cao hơn.
Thực tế thì đúng là có những ngôn ngữ yêu cầu nhiều dấu kết hợp trên cùng một kí tự, ví dụ như ngôn ngữ Ticuna của Peru dùng dấu để thể hiện các âm (tones).

Ý tôi là, bạn có thể loại bỏ tất cả dấu kết hợp và làm vỡ rất nhiều đoạn text Unicode. Hoặc loại bỏ tất cả các kí tự có nhiều hơn 1 dấu kết hợp, như vậy thì người Peru chắc chắn sẽ không vui. Hoặc bạn có thể giới hạn con số 5 và những người dùng từ Tibet, những người dùng 8 hoặc nhiều hơn số dấu kết hợp, sẽ nói bye bye với trang web của bạn.
Một giải pháp đơn giản hơn đó là tuyên bố rằng: "đoạn text này không được phép overflow container chứa nó".
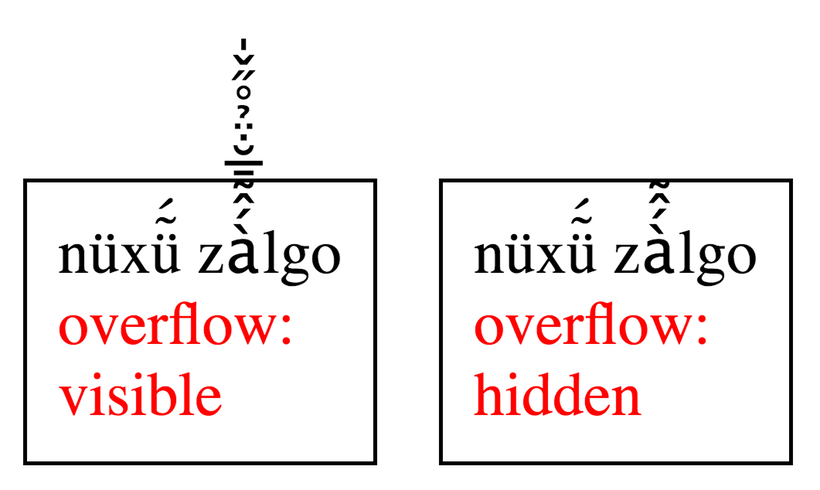
Anyway, sự thật là nhiều codepoint có thể biểu diễn một graphene như trên làm cho việc đảo chuỗi của chúng ta ở đầu bài sẽ không còn đúng nữa. Để có thể đảo chuỗi chính xác, ta cần nhóm các byte thành codepoint, rồi nhóm codepoint thành các grapheme rồi sau đó đảo chuỗi.
"noël" |> String.codepoints |> Enum.reverse # => "l̈eon" "noël" |> String.graphemes |> Enum.reverse # => "lëon"
Dòng thứ 2, về cơ bản chính là những gì mà String.reverse trong Elixir làm, còn dòng thứ 1 là những gì mà các ngôn ngữ khác thường làm.
Tiện đây thì emoji cũng có thể được tạo ra bằng các sử dụng nhiều codepoint. Một ví dụ là đổi màu da:
