Grouping results using aggregation in Elasticsearch
I. Introduction Elasticsearch là một công cụ tìm kiếm mạnh mẽ được xây dựng trên nền tảng của Lucene. Nó có API rất rõ ràng và đơn giản để lập chỉ mục dữ liệu và tìm kiếm/truy xuất dữ liệu. Nhưng đằng sau API này có rất nhiều tính năng có thể giúp bạn cải thiện và thao tác các kết quả tìm kiếm ...
I. Introduction
Elasticsearch là một công cụ tìm kiếm mạnh mẽ được xây dựng trên nền tảng của Lucene. Nó có API rất rõ ràng và đơn giản để lập chỉ mục dữ liệu và tìm kiếm/truy xuất dữ liệu. Nhưng đằng sau API này có rất nhiều tính năng có thể giúp bạn cải thiện và thao tác các kết quả tìm kiếm để đáp ứng bất cứ điều gì ứng dụng của bạn yêu cầu.
Trong bài này, tôi muốn nói về aggregations và cách tôi sử dụng chúng để mang lại kết quả tìm kiếm đã được sắp xếp theo thứ tự theo điểm số. Tiếp tục bằng cách giải thích ngữ cảnh trước tiên và những gì chúng ta muốn, sau đó triển khai và cuối cùng là một số thông tin chi tiết về từng phần.

II. Context: The problem
Chúng ta có một recruitment platform có một bảng không chuẩn hóa cho các job applications. Flatform này là một ứng dụng rails và chúng ta đang sử dụng elasticsearch-rails làm thư viện client để nói chuyện với elasticsearch. Điều duy nhất chung cho các job applications là địa chỉ email, mọi thứ khác có thể khác nhau. Hãy xem ví dụ:

Elasticsearch đã được định cấu hình để có tất cả các trường có thể tìm kiếm được, do đó truy vấn tìm kiếm của bạn sẽ được đối sánh với bất kỳ trường nào. Chúng ta hãy đặt vào một số (số ảo) để biểu thị elasticsearch sẽ sắp xếp kết quả.
- Truy vấn tìm kiếm trùng khớp với tên: 2 điểm
- Truy vấn tìm kiếm phù hợp trên email: 1 điểm
Dựa trên những con số đó, đối với truy vấn tìm kiếm “Doe”, chúng ta sẽ thấy các kết quả sau:

Jane Doe trên top vì "Doe" đã bị hit hai lần, tên và email. Nhưng nếu bạn thực sự đang tìm kiếm “Jon Doe”, bạn phải cuộn xuống kết quả thứ 4, mặc dù 3 kết quả đầu tiên là cùng một ứng cử viên. Và nếu Jane áp dụng 15 lần, chúng ta không muốn một ứng cử viên duy nhất xuất hiện dưới dạng tất cả các kết quả của trang đầu tiên. Vì vậy, chúng ta quyết định nhóm các kết quả bằng email và thu gọn chúng thành một hàng duy nhất có thể được mở rộng nếu muốn.
Đây là những kết quả chúng tôi muốn:
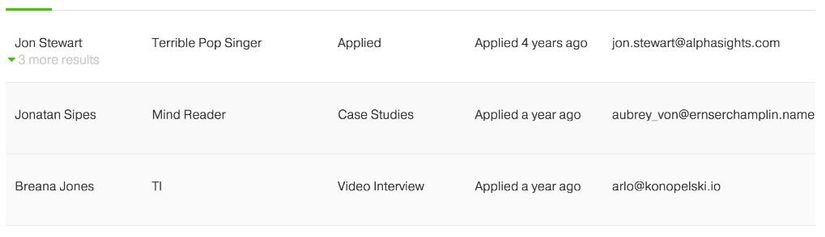
Bây giờ các kết quả chỉ được thu gọn thành 3 hàng, mỗi hàng một ứng cử viên. Điều này mang lại một tập hợp kết quả nhỏ hơn và kết quả tốt hơn cho việc sử dụng của chúng ta vì giờ đây họ có thể tìm kiếm với một phần tên và tìm thấy một loạt những người khác nhau. Nếu bạn muốn các trường hợp khác cho một ứng viên cụ thể, bạn chỉ cần mở rộng hàng và các kết quả khác sẽ hiển thị. Ví dụ, hãy tưởng tượng nhấp vào Click to expand cho kết quả đầu tiên Jon Stewart, đó sẽ hiển thị cho bạn những kết quả lồng nhau cho các ứng cử viên, cho phép bạn chọn các trường hợp cụ thể mà bạn đang tìm kiếm:
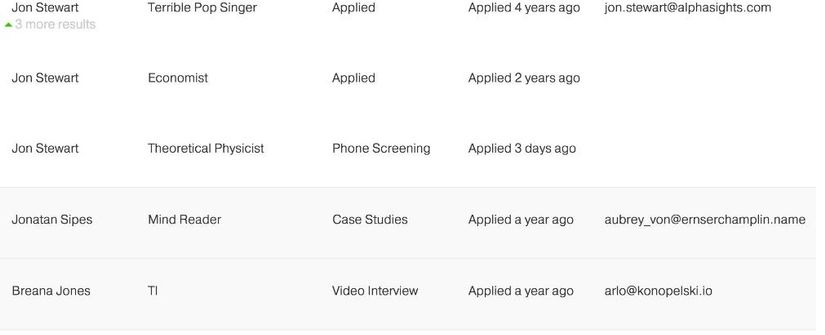
Trong elasticsearch terms aggregation, một tính năng cho phép elasticsearch nhóm các kết quả dựa trên một trường cụ thể của mô hình. Sử dụng terms aggregation kết hợp với một cặp sub-aggregations như top hits aggregation và max aggregation. Chúng ta có thể nhóm theo địa chỉ email và sắp xếp các nhóm dựa trên số điểm tối đa trên mỗi nhóm. Đây là truy vấn tìm kiếm cuối cùng (sử dụng API elasticsearch-rails):
class CandidateQuery
def self.query(keywords)
{
query: {
multi_match: {
query: keywords,
fields: ["name^2", "email", "phone"]
}
},
aggs: {
by_email: { # Top level aggregation: Group by email
terms: {
field: "email_raw",
size: 10,
# Order results by sub-aggregation named 'max_score'
order: { max_score: "desc" }
},
aggs: { # Sub-aggregations
# Include the top 15 hits on each bucket in the results
by_top_hit: { top_hits: { size: 15 } },
# Keep a running count of the max score by any member of this bucket
max_score: { max: { lang: "expression", script: "_score" } }
}
}
}
}
end
end
Truy vấn này sẽ mang lại kết quả JSON sau cho cơ sở dữ liệu đã cho của chúng ta và truy vấn tìm kiếm “Doe”
{
"aggregations": {
"by_email": {
"buckets": [
{
"key": "jane@doe.com",
"max_score": {
"value": 2.538935899734497
},
"by_top_hit": {
"hits": {
"max_score": 2.538936,
"hits": [
{
"_score": 2.538936,
"_source": { "name": "Jane Doe", "phone": "555-555-4444" }
},
{
"_score": 2.375705,
"_source": { "name": "Jane Doe", "phone": "555-555-4941" }
},
{
"_score": 2.340123,
"_source": { "name": "Jane Smith", "phone": "555-555-2333" }
}
]
}
}
},
{
"key": "jon@hot.com",
"max_score": {
"value": 0.11838431656360626
},
"by_top_hit": {
"hits": {
"max_score": 0.11838432,
"hits": [
{
"_score": 0.11838432,
"_source": { "name": "Jon Doe", "phone": "222-333-4444" }
},
{
"_score": 0.11838432,
"_source": { "name": "Jon Doe", "phone": "222-333-5555" }
},
]
}
}
}
]
}
}
}
Tôi đã bỏ qua các trường không liên quan từ kết quả cho ngắn gọn (trong kết quả thực tế là lớn hơn nhiều). Như bạn có thể thấy đó là những gì chúng ta muốn, kết quả được nhóm theo email ứng cử viên và được sắp xếp theo số điểm cao nhất của mỗi nhóm.
Bây giờ hãy phân tích truy vấn và lập bản đồ cho kết quả để hiểu điều gì đang diễn ra. Hãy bắt đầu với truy vấn.
III. Query
query: {
multi_match: {
query: keywords,
fields: ["name^2", "email", "phone"]
}
}
Đây là truy vấn thực tế chúng ta thực hiện trên search engine. Ở đây chúng ta chỉ định các từ khóa và những trường nào cần tìm kiếm. Chúng ta cũng có thể tăng cường một số trường vì vậy bất kỳ kết quả nào nhận được điểm số trên trường đó sẽ nhận được điểm cao hơn (trong ví dụ này, chúng ta tăng trường name lên 2, cho điểm số cao hơn email và điện thoại). Để biết thêm, hãy xem truy vấn multi_match.
IV. Top level aggregation: aggregate by email
aggs: {
by_email: { # Top level aggregation: Group by email
terms: {
field: "email_raw",
size: 10,
# Order results by sub-aggregation named 'max_score'
order: { max_score: "desc" }
}
Đây là tập hợp cấp cao nhất mà chúng ta đang sử dụng. Elasticsearch cho phép bạn gộp các kết quả dựa trên một trường (hoặc thuật ngữ) bằng cách sử dụng một aggregation mà chúng gọi là terms aggregation. Aggregation này đang sử dụng thuật ngữ email_raw để nhóm các kết quả lại với nhau. Trường email_raw là trường được lập chỉ mục lưu trữ email đơn giản (trái ngược với trường email bình thường lưu trữ phiên bản email được mã hóa ~ tức là [“jon”, “doe”, “com”, v.v., v.v.)]). Bất kỳ kết quả nào có cùng một email sẽ được đặt trong cùng một nhóm.
V. Sub-aggregations: top_hits and max
aggs: { # Sub-aggregations
# Include the top 15 hits on each bucket in the results
by_top_hit: { top_hits: { size: 15 } },
# Keep a running count of the max score by any member of this bucket
max_score: { max: { lang: "expression", script: "_score" } }
}
Cuối cùng, chúng ta nhìn vào top_hits và max. Lưu ý rằng hai tập hợp này được lồng vào bên trong terms aggregation, do đó chúng sẽ hoạt động ở cấp độ nhóm. Bằng cách này, nghĩa terms aggregation trước tiên sẽ nhóm tất cả kết quả qua email và tạo một nhóm trên mỗi email, sau đó top_hits và max sẽ hoạt động trong mỗi nhóm độc lập.
Hãy bắt đầu với max. Aggregation này sẽ xem xét số điểm của từng phần tử được thêm vào trong nhóm và sẽ lưu số điểm tối đa. Điều này được sử dụng bởi terms aggregation cấp cao nhất để sắp xếp thứ tự các nhóm. Về cơ bản, chúng ta order các nhóm theo số điểm cao nhất mà mỗi nhóm chứa. Nếu bạn xem kết quả được hiển thị ở trên, bạn sẽ thấy trường max_score trên mỗi nhóm, max aggregation là kết quả tạo trường đó.
Top_hits aggregation được sử dụng để lưu document trong mỗi nhóm. Nếu chúng ta không bao gồm top_hits thì mỗi nhóm sẽ chỉ có khóa (email), max score, số lượng document (số lượng document nằm trong nhóm) nhưng sẽ không bao gồm các document thực tế. Sử dụng top_hits kết hợp với terms, chúng ta nhận cả nhóm và tất cả documents trong mỗi nhóm (bạn có thể xem kết quả của top_hits bằng cách xem kết quả ở trên tại trường “by_top_hits”).
VI. Composition of the result
Dưới đây là hình ảnh cố gắng hiển thị thành phần của kết quả:

VII. References
https://m.alphasights.com/practical-guide-to-grouping-results-with-elasticsearch-a7e544343d53
