Insert, Delete và Update bị ảnh hưởng như thế nào khi đánh Index?
Trong các bài viết trước về chỉ mục, chúng ta chỉ bàn về phần hiệu suất, tối ưu truy vấn, nhưng SQL không chỉ là về truy vấn. Nó cũng hỗ trợ thao tác dữ liệu. Các lệnh tương ứng là INSERT, DELETE, và UPDATE, cái gọi là “data manipulation language - ngôn ngữ thao tác dữ liệu” (DML) - một ...
Trong các bài viết trước về chỉ mục, chúng ta chỉ bàn về phần hiệu suất, tối ưu truy vấn, nhưng SQL không chỉ là về truy vấn. Nó cũng hỗ trợ thao tác dữ liệu. Các lệnh tương ứng là INSERT, DELETE, và UPDATE, cái gọi là “data manipulation language - ngôn ngữ thao tác dữ liệu” (DML) - một phần của chuẩn SQL. Hiệu suất của các lệnh trên đa phần bị ảnh hưởng tiêu cực bởi việc đánh chỉ mục.
Một chỉ mục đơn thuần nó là dư thừa. Nó chỉ chứa dữ liệu mà cũng được cất trữ trong các bảng. Trong các hoạt động thay đổi dữ liệu, cơ sở dữ liệu phải giữ các dư thừa đó luôn nhất quán (giống nhau trong index và trong bảng). Cụ thể, nó có nghĩa là INSERT, DELETE, hay UPDATE không chỉ ảnh hưởng đến bản chính mà các chỉ mục cũng bị ảnh hưởng.
Bài viết sẽ tập trung vào các câu lệnh trên để thấy được sự ảnh hưởng của việc sử dụng chỉ mục đến với hiệu năng hoạt động của chúng.
Số lượng chỉ mục trên một bảng là hệ số chi phối nhiều nhất tới hiệu suất của INSERT. Chỉ mục của một bảng càng nhiều, việc thực thi càng chậm. Câu lệnh INSERT là hoạt động duy nhất mà không thể trực tiếp hưởng lợi từ việc đánh chỉ mục vì nó không có mệnh đề WHERE.
Thêm một hàng mới vào một bảng bao gồm một vài bước.
Trước tiên, database phải tìm nơi để cất trữ hàng. Đối với các bảng heap thông thường - không có thứ tự hàng cụ thể nào - cơ sở dữ liệu có thể lấy bất kì block nào có đủ không gian trống cho bảng này. Đây là một quá trình rất đơn giản và nhanh chóng, hầu hết được hoàn thành trong main memory. Tất cả những việc database làm sau đó là thêm dữ liệu mới vào khối dữ liệu tương ứng.
Nếu có nhiều index trên một bảng, CSDL phải đảm bảo các hàng mới thêm vào cũng được tìm thấy thông qua các chỉ mục. Vì lý do này mà nó phải thêm phần tử chỉ mục cho hàng mới trên mọi index. Do đó mà số chỉ mục càng nhiều sẽ khuếch đại chi phí cho mỗi thao tác INSERT.
Hơn nữa, thêm một phần tử mới vào một chỉ mục đắt hơn nhiều do với việc thêm vào một cấu trúc heap bởi vì CSDL phải giữ thứ tự các chỉ mục và cây cân bằng. Điều đó nghĩa là phần tử mới không thể được ghi cho bất kì block nào, mà nó sẽ thuộc về một nút lá (block) cụ thể. Mặc dù CSDL sử dụng cây chỉ mục để tìm đúng nút lá, nó vẫn phải đọc một vài các nút lá khác cho việc duyệt cây.
Chỉ khi nút lá đúng được xác định, database sẽ xác nhận rằng có đủ không gian trống trong nút này. Nếu không, cơ sở dữ liệu sẽ chia tách nút lá và phân phối lại các phần tử giữa nút cũ và nút mới. Quá trình này cũng ảnh hưởng tới cả nút mới và nút cũ, tức ảnh hưởng bị nhân đôi. Xa hơn, nút nhánh có thể cũng bị đầy vì vậy nó có thể bị phân tách. Trong trường hợp xấu nhất, cơ sở dữ liệu sẽ tách tất cả các nút. Đây là trường hợp duy nhất mà cây được thêm tầng và lớn hơn về độ sâu.
Sau tất cả, việc duy trì index là phần đắt nhất của hoạt động INSERT. Điều này cũng có thể thấy ở trong bảng 8.1 “Hiệu xuất của INSERT theo số chỉ mục”. Việc thêm một chỉ mục đơn là đủ để tăng thời gian thực hiện. Mỗi index được thêm lại làm chậm các việc thực thi hơn nữa.
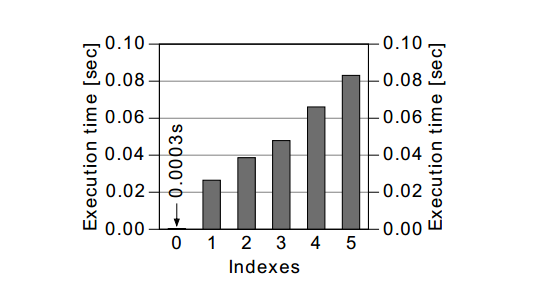
Hình 8.1: Hiệu xuất của INSERT theo số chỉ mục
- Chú ý: Các chỉ mục đầu tiên tạo ra sự khác biệt lớn nhất.
- Để tối ưu hóa hiệu suất insert thì rất rất quan trọng việc giữ số index nhỏ.
- Mẹo: Sử dụng index cần xem xét kĩ lưỡng và cần tiết kiệm số index, và tránh các index rườm rà bất cứ khi nào có thể. Điều này cũng có lợi với các câu lệnh DELETE hay UPDATE.
Xem xét riêng câu lệnh INSERT, tốt nhất nên tránh hoàn toàn các chỉ mục - điều này sẽ có hiệu quả tốt nhất cho hiệu suất INSERT. Tuy nhiên các bảng không có chỉ mục là không thực tế trong các ứng dụng. Bạn luôn cần truy vấn dữ liệu vì vậy bạn cần đánh chỉ mục để cải thiên tốc độ truy vấn.
Câu hỏi đặt ra là: Bảng ở hình 8.1 sẽ thay đổi thế nào khi sử dụng index organized table hay clustered index? Và có hay không một cách nào đó mà đánh index để làm cho câu lệnh INSERT nhanh hơn?
Không giống như câu lệnh INSERT, câu lệnh DELETE có mệnh đề WHERE mà có thể sử dụng tất cả các phương pháp mô tả ở các bài viết trước để hưởng lợi trực tiếp từ việc đánh chỉ mục. Trên thực tế, lệnh DELETE làm việc giống như một việc lựa chọn các hàng xác định để xóa.
Việc xóa một hàng thực tế là một quá trình tương tự với việc INSERT một hàng - đặc biệt là về việc loại bỏ các tham chiếu/con trỏ của index và các hoạt động để giữ cho cậy index cân bằng. Do đó mà biểu đồ hiệu suất hiển thị trong hình 8.2 là gần giống với một biểu đồ hiệu suất cho hành động INSERT.
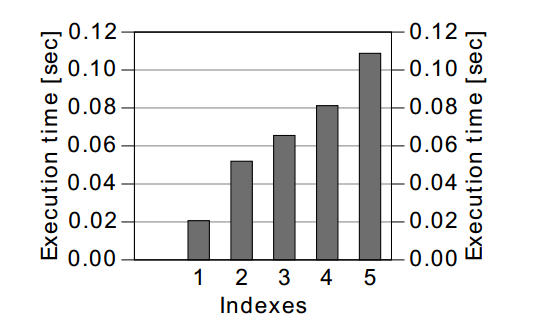
Hình 8.2: Hiệu xuất lệnh delete theo số chỉ mục
Về lý thuyết, chúng ta mong đợi hiệu suất của lệnh DELETE là tốt nhất trong trường hợp không có index - như với lệnh INSERT. Tuy nhiên, nếu không có index, cơ sở dữ liệu phải đọc toàn bộ bảng để tìm ra hàng cần xóa. Điều này có nghĩa rằng việc xóa thì nhanh hơn nhưng việc tìm ra hàng để xóa thì lại rất chậm. Trường hợp này do đó không được thể hiện trong hình 8.2.
Tuy nhiên có thể có khả năng là câu lệnh DELETE thực thi tốt hơn khi không có index như là việc có thể lệnh INSERT thực thi khi không có index tốt hơn nếu truy vấn tác động đến phần lớn của bảng.
Một lệnh DELETE không có mệnh đề WHERE là một ví dụ rõ ràng mà database không sử dụng index, mặc dù đây là trường hợp đặc biệt mà có lệnh SQL riêng: truncate table.
Một lệnh UPDATE phải di rời các phần tử chỉ mục thay đổi để duy trì thứ tự index. Để làm điều này thì cơ sở dữ liệu phải xóa phần tử chỉ mục cũ ban đầu và thêm vào phần tử chỉ mục mới tại vị trí mới. Thời gian phản hổi cơ bản là giống như là riêng từng lệnh DELETE và INSERT cùng thực hiện vậy.
Như lệnh INSERT hay DELETE thì hiệu suất của lệnh UPDATE cũng phụ thuộc vào số index trên bảng. Sự khác biệt duy nhất là câu lệnh UPDATE không nhất thiết phải ảnh hưởng tới tất cả các cột vì chúng chỉ sửa đổi một số cột được chọn. Hệ quả là lệnh UPDATE không nhất thiết ảnh hưởng đến tất cả các index trên bảng nhưng vẫn ảnh hưởng tới các index có chứa trong các cột được cập nhật.
Hình 8.3 chỉ ra thời gian phản hổi cho hai lệnh UPDATE: một lệnh thì update tất cả các cột và ảnh hưởng tới tất cả các index, một lệnh chỉ update một cột và chỉ ảnh hưởng tới một index.
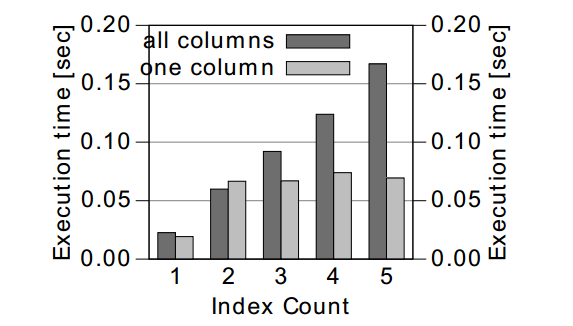
Hình 8.3: Hiệu suất lệnh UPDATE theo các chỉ mục và số lượng cột.
Lệnh UPDATE trên tất cả các cột cho thấy cùng một pattern ta đã quan sát được trong các phần trước: thời gian phản ứng tăng lên với mỗi một index được thêm, thời gian phản hổi với UPDATE trên một cột không tăng nhiều bởi hầu hết các chỉ mục không phải cập nhật.
Để tối ưu hóa hiệu suất của lệnh UPDATE, bạn chỉ cần phải lưu tâm tới những cột bị cập nhật. Điều này là hiển nhiên nếu chạy các câu lệnh cập nhật thủ công. Tuy nhiên nếu sử dụng công cụ ORM thì câu lệnh UPDATE có thể được tạo ra luôn luôn cập nhật tất cả các cột.
Câu hỏi đặt ra là: Bạn có thể nghĩ ra trường hợp nào mà câu lệnh INSERT hoặc DELETE không ảnh hưởng tới tất cả các index của một bảng.
- Ở bài viết này, ta có thể thấy rằng việc cập nhật dữ liệu sẽ bị ảnh hưởng hiệu suất khá nhiều khi chúng ta sử dụng index. Chính vì điều này, việc cân nhắc khi bạn cần sử dụng index cho một bảng nào đó là không hề thừa bởi nó sẽ làm giảm hiệu năng chương trình của bạn nếu nó là dư thừa, không cần thiết.
- Bạn đọc có thể tìm hiểu thêm trong cuốn SQL Performance Explained - MARKUS WINAND
