Làm việc với CloudStrorage và Bigquery với ruby
BigQuery API Quickstart Create an Authorized BigQuery Service Object In order to make authenticated requests to Google Cloud Apis using the Google APIs Client libraries, you must: Fetch the credential to use for requests. Create a service object that uses that credential. You can ...
BigQuery API Quickstart
Create an Authorized BigQuery Service Object
In order to make authenticated requests to Google Cloud Apis using the Google APIs Client libraries, you must:
Fetch the credential to use for requests.
- Create a service object that uses that credential.
- You can then make API calls by calling methods on the service object.
For this example, you'll fetch Application Default Credentials from the environment, and pass it as an argument to create the service object. For information about other types of credentials you can use, see Authenticating requests to the Google BigQuery API
require "gcloud" gcloud = Gcloud.new project_id bigquery = gcloud.bigquery
Running Queries
BigQuery provides two API methods for running queries. The synchronous query method involves a single API call, and will wait to provide a response until the query is complete (unless provided with an optional timeout value). The asynchronous query method will "insert" a query job, and immediately return an ID for that job. You then use this job ID to poll for the status of the query, and retrieve the query result if complete. This example uses the synchronous query method. For more information about different ways to query using BigQuery, see querying data.
Running the Query
To run a synchronous query, the application makes an API call that passes the query itself (as a string), along with the project number that the query will be run under for billing and quota purposes. The query in the example below finds the 10 of Shakespeare's works with the greatest number of distinct words. BigQuery uses a SQL-like syntax, which is described in our query reference guide.
sql = "SELECT TOP(corpus, 10) as title, COUNT(*) as unique_words " + "FROM [publicdata:samples.shakespeare]" results = bigquery.query sql
Displaying the query result
Once the query has completed, the API returns the result set as a JSON object, which the SDK exposes as a native object. In addition to the actual query results, the JSON response contains metadata about the query job, including a unique job ID and the schema of the result set. The application parses the query response and displays the resulting values.
results.each do |row| puts "#{row['title']}: #{row['unique_words']}" end
Next Steps
This tutorial covers only the most basic steps necessary to make calls to the BigQuery API from a command-line application. The BigQuery API also provides methods for running asynchronous queries, creating tables and datasets, listing projects, and more.
For a deeper look into authorizing access to the BigQuery API from various types of applications, see Authenticating requests to the Google BigQuery API. Post your general questions about developing applications using the BigQuery API on Stack Overflow. Google engineers monitor and answer questions tagged with google-bigquery.
Complete Source Code
Here is the complete source code for the examples in this quick start guide.
class Shakespeare def unique_words project_id require "gcloud" gcloud = Gcloud.new project_id bigquery = gcloud.bigquery sql = "SELECT TOP(corpus, 10) as title, COUNT(*) as unique_words " + "FROM [publicdata:samples.shakespeare]" results = bigquery.query sql results.each do |row| puts "#{row['title']}: #{row['unique_words']}" end end end if __FILE__ == $PROGRAM_NAME project_id = ARGV.shift Shakespeare.new.unique_words project_id end
CloudStorage: Using the Developers Console
Create a bucket
-
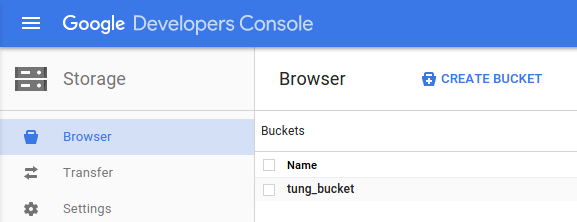
Open the Google Cloud Storage browser in the Google Cloud Platform Console.
https://console.developers.google.com
-
Click Create bucket.
-
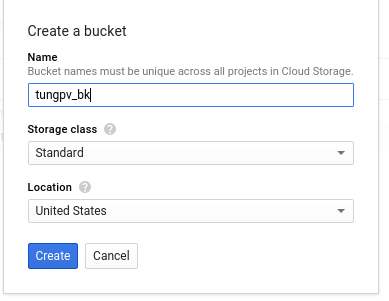
Enter a unique Name for your bucket.
Upload objects into the bucket
-
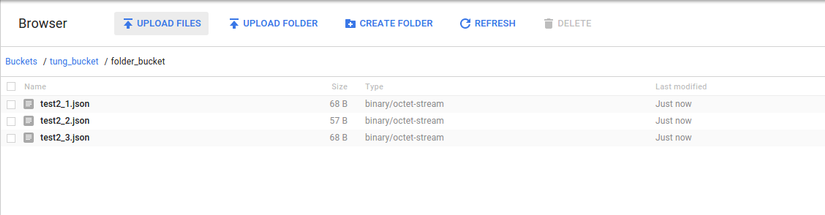
Click Upload files or Upload folder to upload files or folders.

Note: Folder uploads are only supported in Chrome. File uploads are supported in all browsers.
-
In the file dialog, select one or more files to upload, or select a folder.
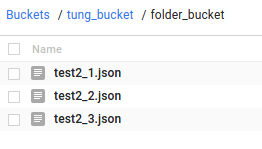
Create a folder in the bucket
-
Navigate to a bucket or existing folder in a bucket where you want to create a new folder.
-
Click Create folder.
-
Name your folder and click Create.
-
Your new folder will now appear in your bucket. Click the folder to open it.
-
At this point, you can:
- Upload data into the folder or create a new folder within it.
- Navigate up to the container of the folder by clicking the container name in the breadcrumb trail above the upload buttons.