Machine Learning thật thú vị (6): Nhận diện giọng nói
Nhận diện giọng nói đang xâm nhập vào cuộc sống hiện đại. Nó được cài đặt trong những chiếc điện thoại, điều khiển trò chơi hay những chiếc đồng hồ thông minh. Chỉ với khoảng $$0, bạn có thể có Amazon Echo Dot - một chiếc hộp thần kỳ cho phép bạn đặt pizza, nhận thông tin dự báo thời tiết hoặc thậm ...
Nhận diện giọng nói đang xâm nhập vào cuộc sống hiện đại. Nó được cài đặt trong những chiếc điện thoại, điều khiển trò chơi hay những chiếc đồng hồ thông minh. Chỉ với khoảng $$0, bạn có thể có Amazon Echo Dot - một chiếc hộp thần kỳ cho phép bạn đặt pizza, nhận thông tin dự báo thời tiết hoặc thậm chí mua những vật dụng - chỉ bằng cách đưa ra mệnh lệnh:
 Echo Dot trở nên phổ biến trong kỳ nghỉ đến nỗi Amazon bị cháy hàng.
Echo Dot trở nên phổ biến trong kỳ nghỉ đến nỗi Amazon bị cháy hàng.
Nhưng nhận diện giọng nói đã được biết đến hàng thập kỷ, tại sao chỉ đến bây giờ, công nghệ mới thực sự bùng nổ? Sự ra đời của Deep Learning đã giúp nhận diện giọng nói chính xác, thậm chí ở ngoài môi trường phòng lab.
Andrew Ng đã dự đoán từ lâu rằng ngay khi độ chính xác của nhận diện giọng nói đạt ngưỡng 99%, nó sẽ trở thành phương thức giao tiếp chủ yếu với máy tính. Và nhờ có Deep Learning, cuối cùng chúng ta đã có thể chạm tới ngưỡng này.
Andrew Ng là giáo sư nổi tiếng về Machine Learning. Khóa học của ông trên Coursera được coi là kinh thánh cho những người nhập môn.
Hãy bắt đầu học nhận diện giọng nói cùng deep learning thôi nào!
Machine Learning không phải lúc nào cũng là chiếc hộp đen kỳ diệu
Nếu bạn biết cách mạng máy dịch thuật hoạt động, bạn có thể đoán rằng: chúng ta chỉ cần truyền đoạn ghi âm vào mạng nơron và đào tạo nó để tạo ra "bản dịch"
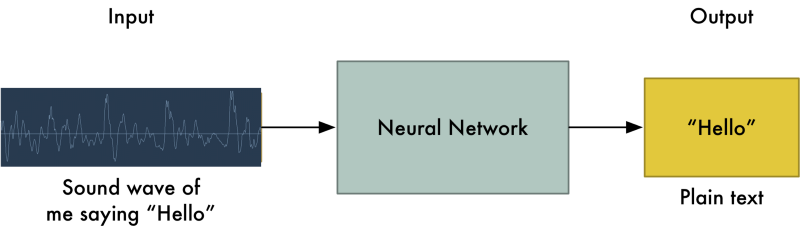 Đó cũng là điều mà nhận diện giọng nói với deep learning hướng tới, nhưng chúng ta chưa đạt đến trình độ đó (có thể cần phải thêm vài năm nữa).
Đó cũng là điều mà nhận diện giọng nói với deep learning hướng tới, nhưng chúng ta chưa đạt đến trình độ đó (có thể cần phải thêm vài năm nữa).
Vấn đề lớn nhất chính là tốc độ nói biến thiên. Một người có thể nói "Hello" rất nhanh và người khác nói "heeeellllllloooooo!" cực chậm, tạo ra âm thanh dài hơn với nhiều dữ liệu hơn. Cả 2 âm đều nên được nhận dạng chính xác là từ một - "hello!". Tự động chỉnh file âm thanh với nhiều biến thể độ dài khác nhau của từng từ để tạo ra văn bản đồng nhất lại khá khó.
Để xử lý vấn đề này, chúng ta sẽ sử dụng một số kỹ thuật đặc biệt và thêm một vài bước vào mạng deep learning.
Chuyển âm thanh thành số
Bước đầu tiên trong nhận diện giọng nói khá rõ ràng - chung ta cần truyền sóng âm vào máy tính.
Ở phần 3, chúng ta đã học cách coi hình ảnh là tập hợp giá trị, với mỗi giá trị đại diện cho độ sáng của điểm ảnh, để truyền vào mạng nơron.
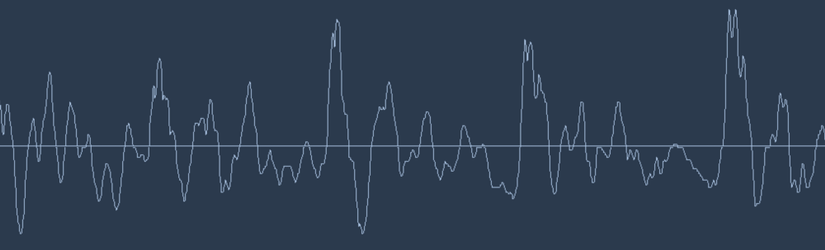
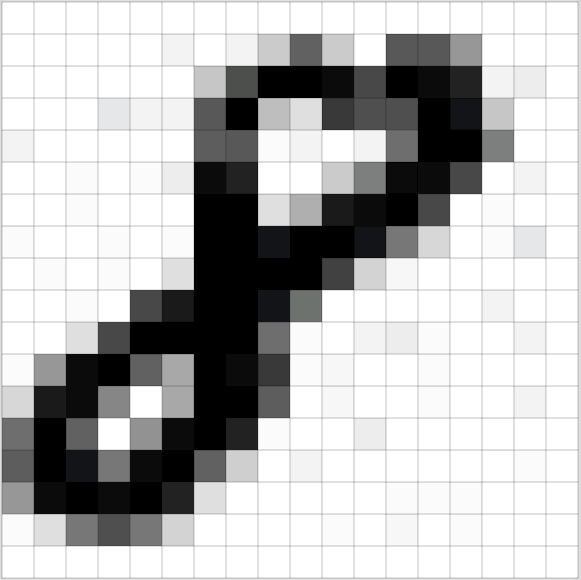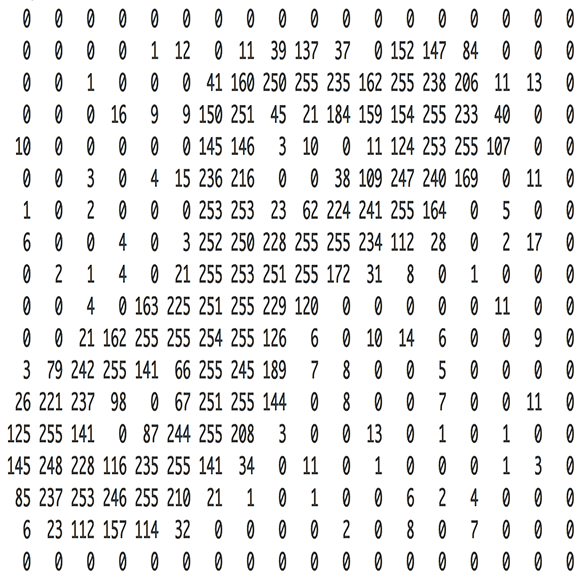 Nhưng âm thanh được truyền qua sóng âm. Làm thế nào chúng ta chuyển sóng âm thành số? Hãy sử dụng đoạn âm nói "Hello" dưới đây:
Nhưng âm thanh được truyền qua sóng âm. Làm thế nào chúng ta chuyển sóng âm thành số? Hãy sử dụng đoạn âm nói "Hello" dưới đây:
 Sóng âm có một chiều dữ liệu. Ở mỗi thời điểm, chúng có một giá trị cao độ. Hãy phóng to một đoạn nhỏ sóng âm để nhìn rõ hơn:
Sóng âm có một chiều dữ liệu. Ở mỗi thời điểm, chúng có một giá trị cao độ. Hãy phóng to một đoạn nhỏ sóng âm để nhìn rõ hơn:
 Để chuyển sóng âm thành số, chúng ta chỉ cần ghi lại độ cao của sóng ở từng khoảng:
Để chuyển sóng âm thành số, chúng ta chỉ cần ghi lại độ cao của sóng ở từng khoảng:
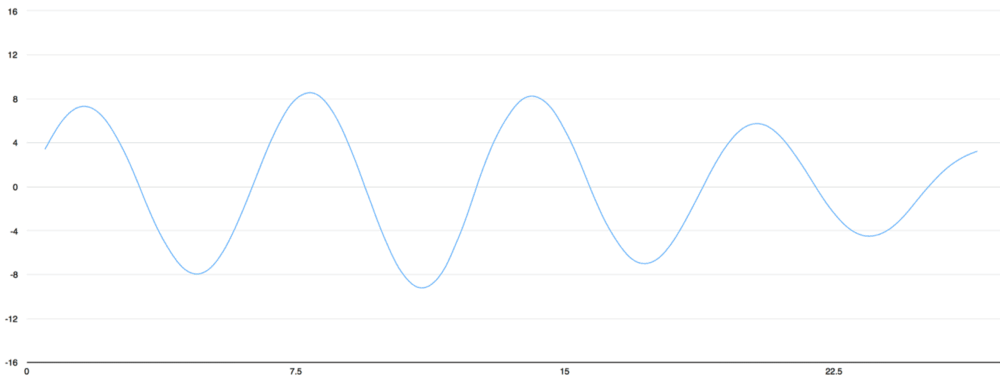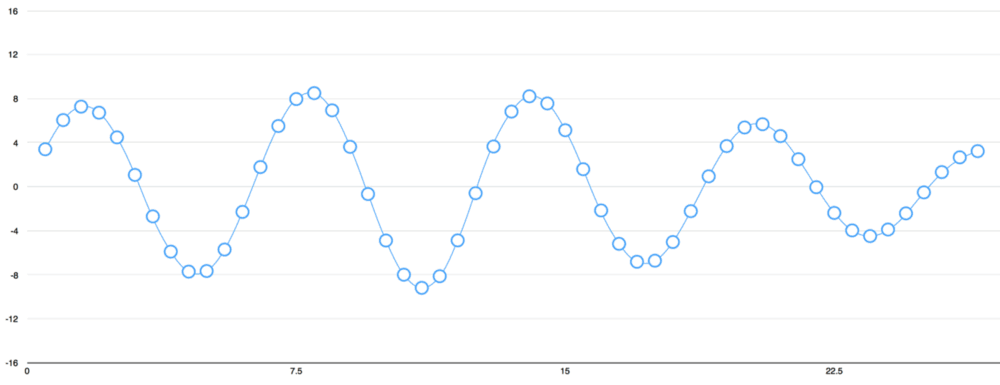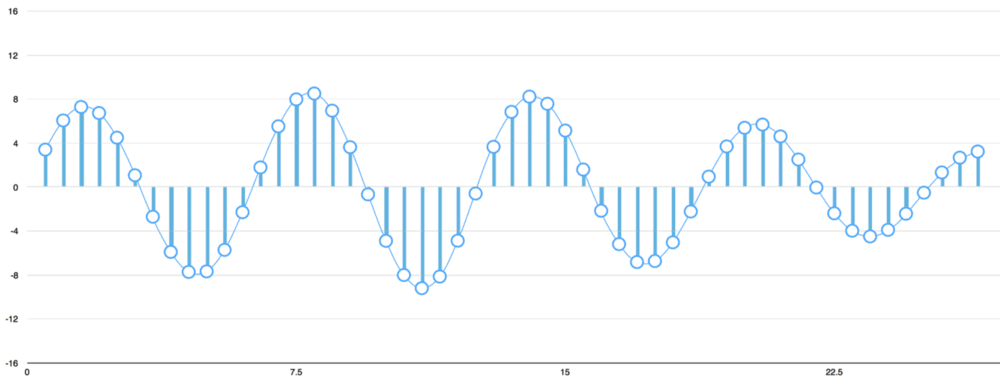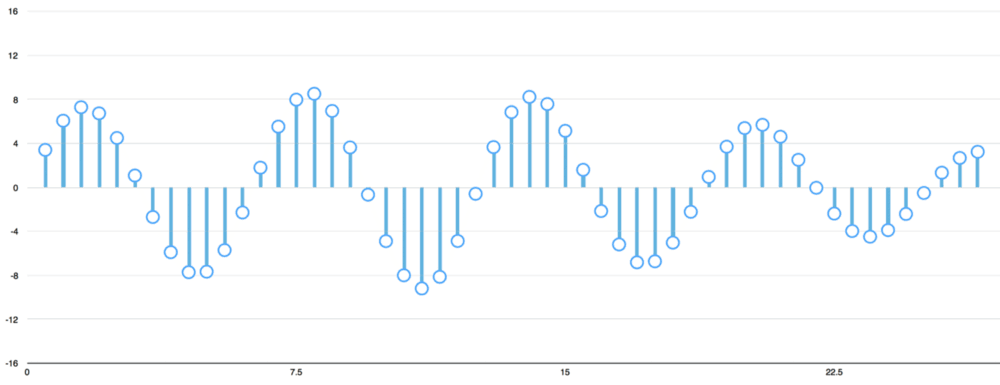 Phương pháp này gọi là sampling - lấy mẫu. Chúng ta đọc mẫu mỗi 1/1000s và ghi lại con số đại diện chiều cao cùa sóng âm. Đây chính là file .wav khi không bị nén.
Phương pháp này gọi là sampling - lấy mẫu. Chúng ta đọc mẫu mỗi 1/1000s và ghi lại con số đại diện chiều cao cùa sóng âm. Đây chính là file .wav khi không bị nén.
Những âm thanh chất lượng tốt được ghi ở tần số 44.1khz (44,100 lần đọc mỗi giây). Nhưng với nhận diện giọng nói, tốc độ lấy mẫu ở 16khz (16,000 mẫu mỗi giây) là quá đủ.
Thử lấy mẫu giọng nói "Hello" trong ví dụ trên với tần suất 16,000 lần mỗi giây. Và đây là 100 mẫu đầu tiên.

Lấy mẫu liệu có được chính xác?
Bạn có thể nghĩ rằng, lấy mẫu chỉ tạo ra đồ thị xấp xỉ so với sóng âm, bởi vì nó chỉ đọc dữ liệu theo từng khoảng. Liệu chúng ta có bị mất dữ liệu giữa mỗi lần đọc?
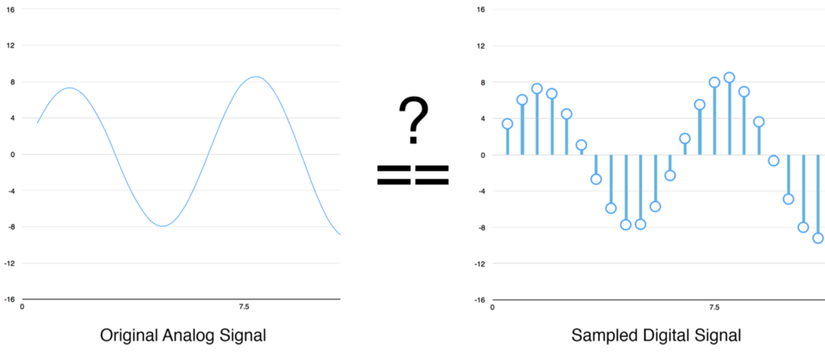 Nhờ có lý thuyết Nyquist, chúng ta có thể sử dụng toán học để tái tạo chính xác sóng âm gốc từ những mẫu tách biệt - miễn là chúng ta lấy mẫu với tần số gấp đôi tần số âm chúng ta muốn ghi lại. Không phải cứ lấy mẫu với tần số càng cao thì chất lượng âm thanh càng tốt (!).
Nhờ có lý thuyết Nyquist, chúng ta có thể sử dụng toán học để tái tạo chính xác sóng âm gốc từ những mẫu tách biệt - miễn là chúng ta lấy mẫu với tần số gấp đôi tần số âm chúng ta muốn ghi lại. Không phải cứ lấy mẫu với tần số càng cao thì chất lượng âm thanh càng tốt (!).
Tiền xử lý dữ liệu mẫu âm thanh
Chúng ta đã có dãy số với mỗi số đại diện cho cao độ âm tại 1/16,000s.
Ta có thể truyền những số này vào mạng nơron, nhưng cố gắng nhận diện cấu trúc âm thanh trực tiếp bằng những mẫu này rất khó. Thay vào đó, chúng ta giải quyết vấn đề dễ hơn bằng cách tiền xử lý dữ liệu.
Hãy bắt đầu nhóm mẫu âm thanh trong khoảng 20ms. Và đây là 320 mẫu âm thanh trong 20ms đó:
 Ghi lại những con số này trong đồ thị giúp chúng ta có ước lượng xấp xỉ về âm thanh gốc trong chu kỳ 20ms:
Ghi lại những con số này trong đồ thị giúp chúng ta có ước lượng xấp xỉ về âm thanh gốc trong chu kỳ 20ms:
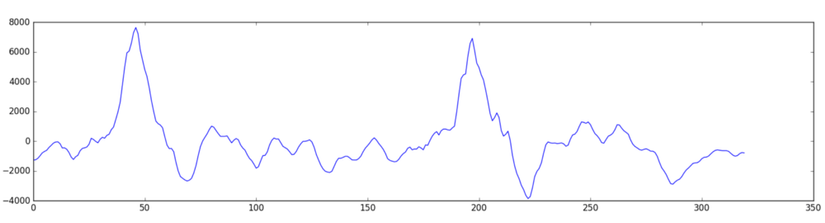 Bản ghi âm này chỉ khoảng 1/50s. Nhưng thậm chí một đoạn ghi âm rất ngắn là một mớ hỗn độn cao độ âm khác nhau. Có những âm thấp, âm trung và thậm chí cả âm cao. Nhưng cùng với nhau, những âm này tạo lên giọng nói.
Bản ghi âm này chỉ khoảng 1/50s. Nhưng thậm chí một đoạn ghi âm rất ngắn là một mớ hỗn độn cao độ âm khác nhau. Có những âm thấp, âm trung và thậm chí cả âm cao. Nhưng cùng với nhau, những âm này tạo lên giọng nói.
Để giúp mạng nơron xử lý dữ liệu dễ hơn, ta tách sóng âm phức tạp này thành từng phần: phần chứa âm thấp, âm cao hơn, cao hơn nữa... Sau đó, ta tính tổng năng lượng ở những những dải tần số (từ thấp đến cao) và kết nối lại tạo ra fingerprint - nhận dạng duy nhất cho từng đoạn trích âm thanh.
Chúng ta làm điều đó nhờ vào việc sử dụng Fourier transform trong toán học. Nó chia nhỏ những sóng âm phức tạp thành sóng âm đơn tạo ra nó, và ta có thể tính tổng năng lượng ở mỗi đơn âm.
Sau khi sử dụng lý thuyết Nyquist ở trên, sóng âm đã trở thành một dải liên tục. Và sử dụng Fourier transform, chúng ta lại tách dải liên tục đó ra thành các notes riêng biệt (được tính toán bởi thuật toán Fourier) để tìm ra tổng năng lượng ở từng note.
Kết quả cuối cùng là một bảng số thể hiện độ năng lượng của mỗi khoảng tần số, từ âm thấp tới âm cao. Mỗi số dưới đây đại diện cho năng lượng dải 50hz trong clip 20ms:
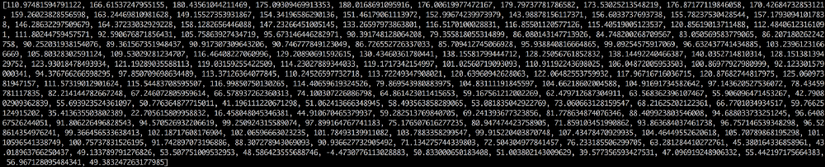 Nhưng sẽ dễ dàng hơn nhiều khi bạn biểu diễn dãy số trên trên đồ thị:
Nhưng sẽ dễ dàng hơn nhiều khi bạn biểu diễn dãy số trên trên đồ thị:

Bạn có thể thấy dài tần số này có rất nhiều năng lượng tần số thấp, và ít năng lượng tần số cao. Đây là một giọng nam điển hình
Nếu chúng ta lặp lại quá trình trên cho mỗi khoảng 20ms, chúng ta sẽ có quang phổ (mỗi cột từ trái qua phải là một khoảng 20ms):
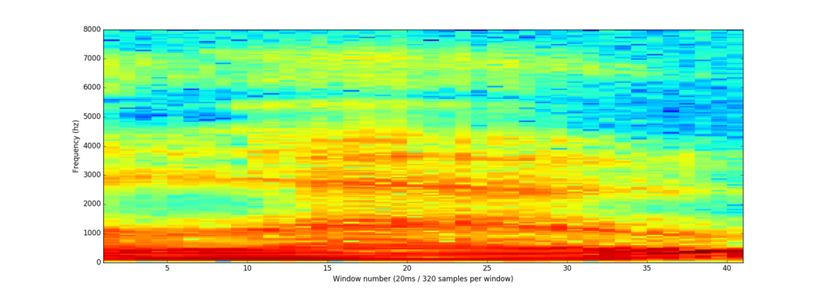 Tạo ra quang phổ giúp chúng ta thực sự nhìn thấy âm thanh và cấu trúc độ cao của nó. Mạng nơron có thể tìm những cấu trúc trong dữ liệu này dễ dàng hơn so với sóng âm thô. Do đó, đây chính là đặc trưng mà ta truyền vào mạng nơron.
Tạo ra quang phổ giúp chúng ta thực sự nhìn thấy âm thanh và cấu trúc độ cao của nó. Mạng nơron có thể tìm những cấu trúc trong dữ liệu này dễ dàng hơn so với sóng âm thô. Do đó, đây chính là đặc trưng mà ta truyền vào mạng nơron.
Mọi người để ý sẽ thấy, hầu hết dữ liệu thô đều chứa nhiều nhiễu và khó xử lý: trong cả ảnh và âm thanh. Một cách giúp hạn chế nhiễu là tổng quát hóa: như trong mạng CNN là trích lọc đặc trưng thông qua convolution - tích chập và max pooling - tách lọc lớn nhất, hay ở trong xử lý âm thanh là lấy tổng năng lượng theo từng âm. Việc tổng quát hóa giúp giảm chiều dữ liệu và hạn chế ảnh hưởng từ nhiễu. Chú ý là nếu quá tổng quát hóa thì lại có thể làm tiêu biến đặc trưng, khiến học máy không thể tìm ra lời giải.
Nhận diện ký tự từ đoạn âm ngắn
Bây giờ chúng ta truyền từng dải âm 20ms vào mạng nơron đa lớp. Với mỗi mảng cắt âm thanh, chúng ta cố gắng tìm ra ký tự đại diện cho âm thanh phát ra.
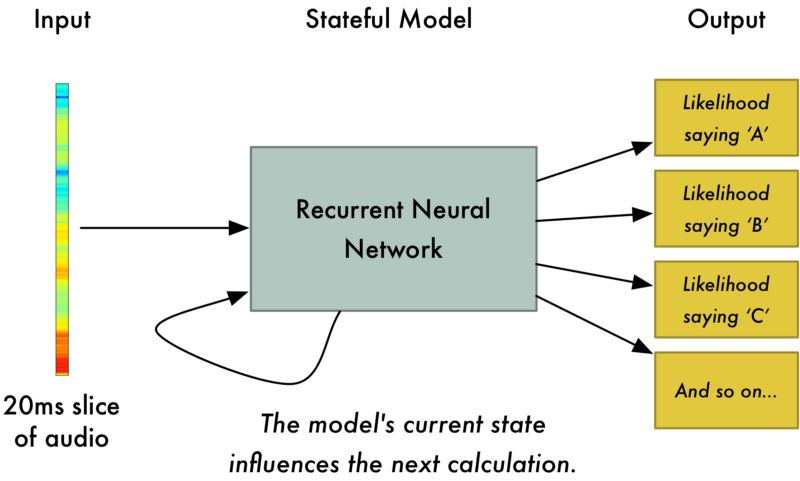 Chúng ta sử dụng Recurrent Neural Network - RNN - mạng nơron hồi quy: kết quả tiên đoán quá khứ có ảnh hưởng tới kết quả tiên đoán trong tương lai. Đó là bởi vì các ký tự có sự liên quan đến nhau. Ví dụ chúng ta đã tìm ra "HEL", thì rất có khả năng chúng ta sẽ nói tiếp "LO". Vì thế, những dự đoán trong quá khứ sẽ giúp dự đoán tương lai được tốt hơn.
Chúng ta sử dụng Recurrent Neural Network - RNN - mạng nơron hồi quy: kết quả tiên đoán quá khứ có ảnh hưởng tới kết quả tiên đoán trong tương lai. Đó là bởi vì các ký tự có sự liên quan đến nhau. Ví dụ chúng ta đã tìm ra "HEL", thì rất có khả năng chúng ta sẽ nói tiếp "LO". Vì thế, những dự đoán trong quá khứ sẽ giúp dự đoán tương lai được tốt hơn.
Sau khi chạy toàn bộ âm thanh thông qua mạng nơron, chúng ta kết nối mỗi dải âm với một ký tự có khả năng được nói cao nhất. Và đây là bản đồ kết nối của từ "HELLO":
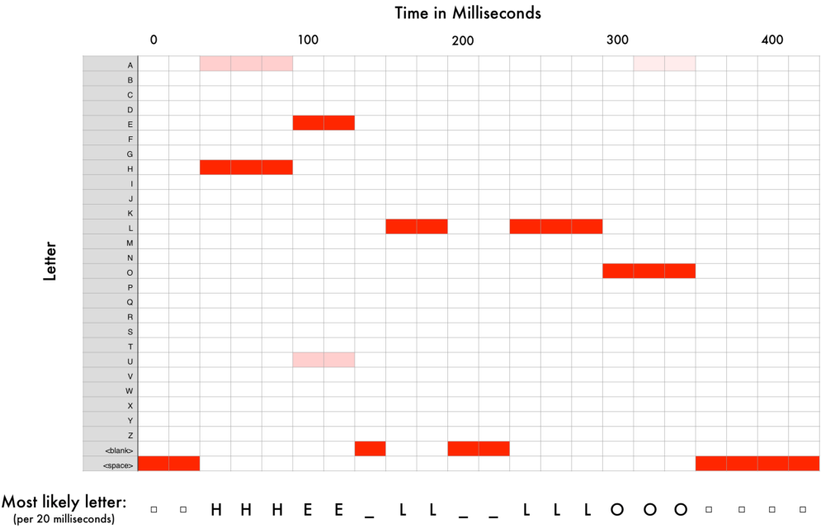 Mạng nơron trên dự đoán từ được nói là “HHHEE_LL_LLLOOO”, nhưng nó cũng nghĩ có khả năng từ đó là “HHHUU_LL_LLLOOO”, hoặc thậm chí là “AAAUU_LL_LLLOOO”
Mạng nơron trên dự đoán từ được nói là “HHHEE_LL_LLLOOO”, nhưng nó cũng nghĩ có khả năng từ đó là “HHHUU_LL_LLLOOO”, hoặc thậm chí là “AAAUU_LL_LLLOOO”
Chúng ta có thêm một vài bước để làm sạch kết quả. Đầu tiên, chúng ta bỏ đi những ký tự bị lặp, rồi bỏ đi khoảng trống:
- HHHEE_LL_LLLOOO => HE_L_LO => HELLO
- HHHUU_LL_LLLOOO => HU_L_LO => HULLO
- AAAUU_LL_LLLOOO => AU_L_LO => AULLO
Như vậy, ta có 3 khả năng phân âm là "Hello", "Hullo" và "Aullo". Nếu bạn nói chúng thật to, cả 3 đều nghe giống với "Hello". Bởi vì dự đoán từng ký tự một, mạng nơron tìm ra cách đọc các âm chứ không phải cách viết. Ví dụ: nếu bạn nói "He would not go", máy có thể dịch là "He wud net go".
Thủ thuật ở đây là kết hợp những dự đoán phiên âm này với khả năng xuất hiện trong các văn bản (sách, bài bảo...). Bạn sẽ loại bỏ đi những phiên âm ít có khả năng ngoài thực tế và giữ phiên âm thực tế nhất. Và trong 3 từ "Hello", Hullo" và "Aullo". Rõ ràng, "Hello" có tần xuất cao hơn rất rất nhiều, và đây chính là bản phiên âm chúng ta lựa chọn.
Tự xây dựng hệ thống nhận diện giọng nói?
Một trong những điều tuyệt vời nhất về học máy là tính đơn giản. Bạn có 1 tập dữ liệu, truyền vào thuật toán học máy, và đột nhiên, bạn có hệ thống trí thông minh nhân tạo hàng đầu thế giới... Có vẻ đúng?
Điều đó đúng trong rất nhiều trường hợp, nhưng không cho ngôn ngữ. Nhận diện ngôn ngữ là một vấn đề khó. Bạn có thẻ vượt qua thử thách không giới hạn: chất lượng micro kém, môi trường ghi âm ồn, tiếng dội lại, giọng điệu khác nhau... Tất cả những vấn đề này hiện hữu trong quá trình đào tạo, khiến mạng nơron không có độ chính xác cao.
Đây là một ví dụ khác: Khi bạn nói trong một phòng ồn, bạn tự động tăng cao độ giọng nói trong vô thức, con người chúng ta vẫn hiểu dễ dàng. Nhưng với mạng nơron, nó cần được đào tạo để xử lý các trường hợp đặc biệt này. Và để xử lý tiếng ồn, bạn cần dữ liệu đào tạo khi mà mọi người đang gào thét vào mặt người nói.
Để xây dựng hệ thống nhận diện âm thanh đạt tới trình độ của Siri, Google Now! hay Alexa, bạn cần rất nhiều dữ liệu. Bạn khó có được tập dữ liệu này trừ phi bạn thuê hàng trăm người tạo dữ liệu cho bạn. Và vì người sử dụng chịu đựng rất kém với hệ thống nhận diện không tốt, bạn không thể lờ đi những trường hợp đặt biệt. Không một ai muốn hệ thống nhận diện chỉ đạt 80% độ chính xác.
Với những công ty lớn như Google hay Amazon, hàng trăm ngàn giờ nói được ghi âm trong thực tế quý giá như vàng. Đó chính là điểm lớn nhất tạo lên hệ thống nhận diện hàng đầu thế giới. Mục đích lớn nhất của việc cho phép cài đặt Google Now! hay Siri miễn phí là để bạn có thể sử dụng nhiều nhất có thể. Những gì bạn nói sẽ được ghi âm mãi mãi và được sử dụng làm dữ liệu đào tạo cho các thuật toán nhận diện giọng nói trong tương lai.
Bạn không tin tôi ư? Nếu bạn có chiếc điện thoại Android cùng Google Now!, click vào đây để nghe lại tất cả những gì bạn từng nói.
Vì thế, nếu như bạn đang tìm kiếm ý tưởng khởi nghiệp, tôi sẽ không khuyến khích bạn xây dựng hệ thống nhận diện giọng nói để cạnh tranh với Google.
Nguồn:
Bài gốc: https://medium.com/@ageitgey/machine-learning-is-fun-part-6-how-to-do-speech-recognition-with-deep-learning-28293c162f7a
