Team Holistics đã xây dựng hệ thống Background Job Queue với PostgreSQL & Ruby như thế nào
Khi thiết kế các ứng dụng web, đặc biệt là đối với các ứng dụng cần xử lý các tác vụ có thời gian thực thi dài như: resize ảnh, phân tích workload, quét CV,... việc hiện thực một hệ thống background job queue là rất quan trọng. Hiện tại trên thị trường đã có những giải pháp tổng quát như ...
Khi thiết kế các ứng dụng web, đặc biệt là đối với các ứng dụng cần xử lý các tác vụ có thời gian thực thi dài như: resize ảnh, phân tích workload, quét CV,... việc hiện thực một hệ thống background job queue là rất quan trọng.
Hiện tại trên thị trường đã có những giải pháp tổng quát như RabbitMQ (message queue), Celery, ActiveMQ, Sidekiq v.v ... được thiết kế khá tốt và phổ biến. Tuy nhiên, do một vài lý do sẽ được trình bày bên dưới, team Holistics đã quyết định tự thiết kế và xây dựng một hệ thống multi-tenant job queue sử dụng Ruby/Rails + Postgres cho ứng dụng B2B SaaS của công ty.
Trong phạm vi bài viết này, mình sẽ giải thích cách team mình đã tiếp cận vấn đề, bắt đầu từ góc nhìn tổng quan, sau đến giải thích lý do tại sao và cách mà team mình đã xây dựng giải pháp.
Bài toán
Holistics là một SQL-based Business Intelligence Platform giúp các chuyên viên phân tích (data analyst) tự động hóa các báo cáo kinh doanh và chuyển đến cho người dùng cuối (business user) một cách nhanh chóng và dễ dàng. Sản phẩm hiện đang được sử dụng bởi nhiều start-up công nghệ đang phát triển nhanh cũng như các công ty có ứng dụng công nghệ với dữ liệu lớn.
Stack công nghệ team Holistics đang sử dụng là:
- Ruby và Rails, chạy trên database PostgreSQL
- HAProxy, nginx và Unicorn
- Sidekiq (và Redis) cho background job engine
Nguyên lý hoạt động cơ bản của hệ thống: bất cứ khi nào có ai đó gửi một request, hệ thống sẽ tạo ra một câu query SQL gửi đến database của khách hàng, chờ kết quả, và hiển thị các biểu đồ dựa trên kết quả.

Vì câu lệnh truy vấn SQL tốn khá nhiều thời gian (vài giây đến vài phút), nên việc sử dụng các request đồng bộ (synchronous) sẽ gây nghẽn hệ thống, do đó một hệ thống background job queue là buộc phải có trong tình huống này..
Trong quá trình cân nhắc các yếu tố để thiết kế (hoặc lựa chọn) hệ thống job queue, team có đề ra một vài yêu cầu sau đây:
- Persistent Jobs: Đối với mỗi background job, chúng ta cần phải theo dõi những thông tin thống kê cơ bản của job như: trạng thái, thời gian chạy, thời gian bắt đầu, thời gian kết thúc, số lượng record trả về, v.v...
- Multi-tenancy: Mỗi khách hàng nên có job queue riêng mà không ảnh hưởng lẫn nhau, mỗi job queue có thể có kích cỡ queue khác nhau (khách hàng A có 5 slot có thể chạy 5 job đồng thời, khách hàng B có 3 slot có thể chạy 3 job đồng thời).
- Độ tin cậy cao: do hệ thống được phục vụ để phân tích dữ liệu quan trọng của khách hàng, nên bản thân job queue cần phải có độ ổn định và chính xác cao. Các tác vụ phải được lựa chọn thực thi theo đúng thứ tự được gửi đến. Đồng thời, queue cũng cũng cần có một cơ chế retry để ngăn chặn những lỗi nhỏ có khả năng phát sinh như vấn đề về kết nối, lỗi đường truyền, ...
Xây dựng Multi-tenant Job Queue trong PostgreSQL
Sau một khoảng thời gian phát triển, team mình đã xây dựng được một hệ thống job queue bằng Rails/Ruby và Postgres. Mỗi khi job được chọn, hệ thống sẽ chuyển chúng xuống Sidekiq để thực hiện chạy nền (background).
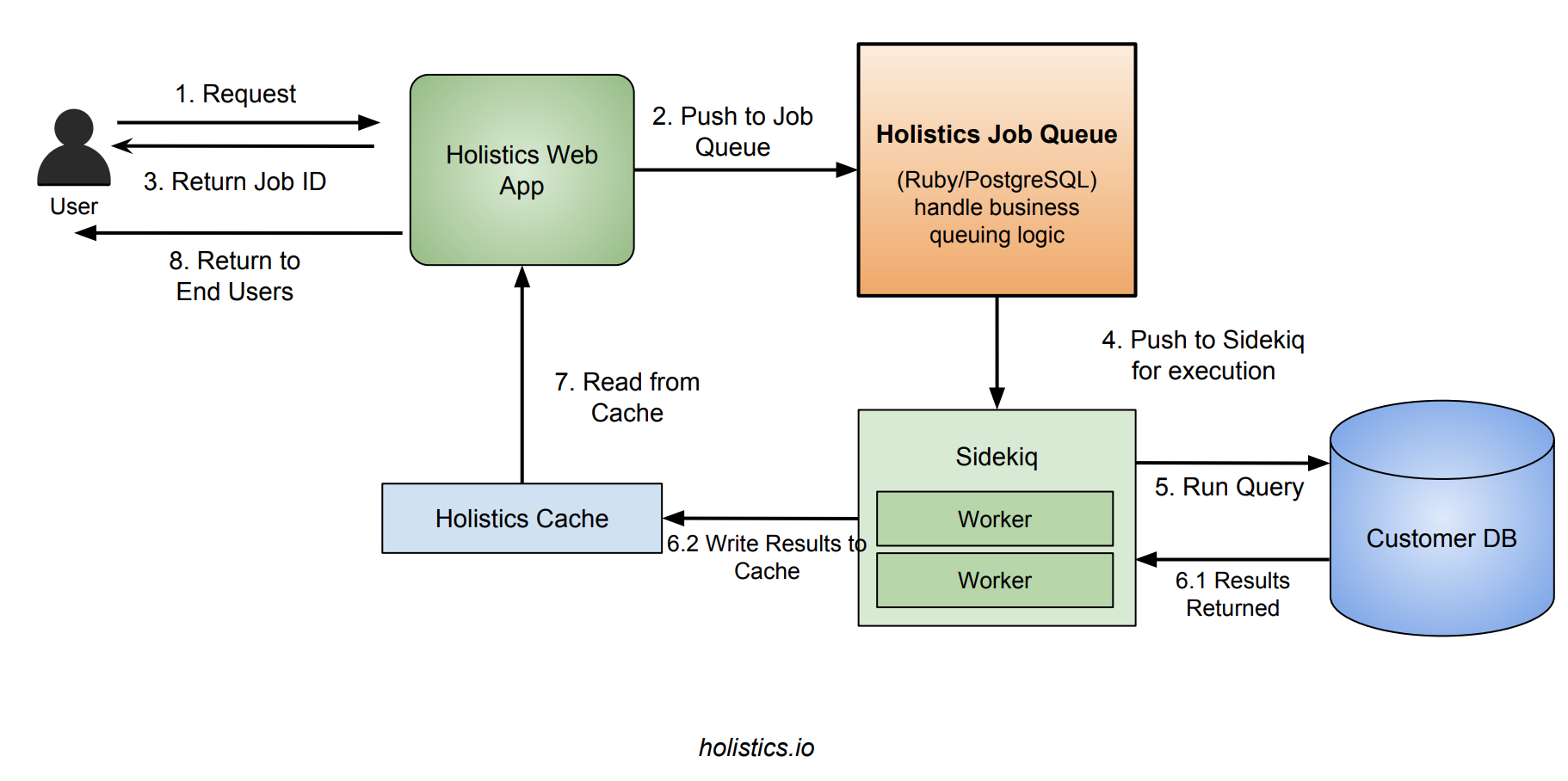
Quy trình xử lý một request của hệ thống sẽ như sau:
- User gửi request đến web server, web server tạo ra một job mới và đẩy những job đó vào queue. Web server trả về một job id cho client.
- Job engine chọn job tiếp theo để được xử lý, và đẩy chúng xuống Sidekiq
- Sidekiq chọn job và thực thi chúng, sau đó ghi kết quả vào vùng cache và cập nhật trạng thái của job trong bảng jobs
- Client sẽ giữ kết nối polling từ web server để cập nhật trạng thái của job cho đến khi nhận được kết quả là success hoặc error. Sau khi success, web server sẽ fetch kết quả từ cache và trả về cho client.
Tại sao lại xây dựng một job queue khác? Và tại sao lại chọn Postgres?
Việc tự xây dựng lại một hệ thống job queue là tốn công, về một khía cạnh nào đó, thì đây hoàn toàn có thể xem như là "re-inventing the wheel". Tuy nhiên, sau khi phân tích và so sánh các hệ thống hiện đang có sẵn, thì hệ thống của Holistics đòi hỏi một vài yêu cầu đặc biệt về mặt tính năng khiến việc "re-inventing the wheel" là không thể tránh khỏi.
- Persistence: Không giống như với các hệ thống job queue khác, hệ thống của Holistics cần lưu trữ mọi thông tin về job đã thực thi dù job đã kết thúc. Việc lưu trữ thông tin về job sẽ giúp phục vụ cho việc audit hệ thống cũng như phục vụ cho các báo cáo quản trị, kiểm soát khi khách hàng yêu cầu sau này.
- Custom Queuing Logic: hệ thống của Holistics cần phải đáp ứng được logic scheduling của chúng tôi có một số logic tùy biến làm cho việc sử dụng job queue phức tạp hơn. Logic như multi-tenancy ở trên, hoặc giới hạn số lượng job đồng thời cho mỗi tài khoản của người thuê.
Sử dụng hệ thống job queue khác sẽ làm cho việc đạt được 2 điều ở trên phức tạp hơn.
Mặt khác, việc tự xây dựng lại một hê thống job queue mới cũng có những nhược điểm sau:
- Scalability: hệ thống sẽ gặp khó khăn trong việc mở rộng quy mô theo chiều ngang (horizontal scaling) khi lượng request tăng cao, tuy nhiên đối với một ứng dụng B2B như Holistics thì nhược điểm này có thể chấp nhận được, vì lượng request trong ứng dụng B2B sẽ không tăng đột biến nhiều như ứng dụng B2C.
- Performance: Việc xử lý nhiều logic trong job queue cũng gây ra tình trạng thời gian xử lý chậm lại khi bảng jobs trở nên phình to. Tuy nhiên việc này có thể tránh được bằng cách đánh index thích hợp và cũng như tìm cách tối ưu hóa cấu hình database. Team Holistics cũng đã thực hiện việc phân vùng table để giữ cho các tập dữ liệu thường truy xuất có kích thước nhỏ.
Quá trình lưu trữ & submit job
Khi user gửi request, team Holistics cần một số cơ chế để lưu trữ metadata của mỗi job. Team đã tạo ra bảng jobs để làm điều này.
CREATE TABLE jobs (
id INTEGER PRIMARY KEY,
source_id INTEGER,
source_type VARCHAR,
source_method VARCHAR,
args JSONB DEFAULT '{}',
status VARCHAR,
start_time TIMESTAMP,
queue_time TIMESTAMP,
end_time TIMESTAMP,
created_at TIMESTAMP,
stats JSONB DEFAULT '{}'
)
Theo thiết kế, trạng thái của một job có thể có các giá trị sau:
- created: khi job được tạo ra lần đầu
- queued: khi job được chọn và đẩy đến Sidekiq
- running: khi Sidekiq worker chọn job và thực hiện nó
- success: job đã thành công
- error: job không thành công
Điều thú vị ở đây là bởi vì bản chất dual queue của hệ thống được thiết kế (job queue quản lý logic, và Sidekiq về cơ bản cũng là một job queue), chúng ta sẽ tách biệt 2 trạng thái created và queued cho một job.
Từ đó, với cách thiết kế này, giá trị start_time - queue_time phải gần như bằng không, nhưng nếu số này tăng lên (job đang được đẩy sang cho Sidekiq, nhưng không có đủ Sidekiq worker để handle chúng) sau đó chúng ta biết cần thêm nhiều Sidekiq worker hơn nữa.
Quá trình xử lý logic Job Queue với PostgreSQL
Một hệ thống job queue sẽ cần phải hỗ trợ những điều sau đây:
- Khả năng chọn ra một job đang ở trạng thái sẵn sàng tiếp theo mà không bị claim, và claim nó
- Không có hai process nào có thể nhận cùng một job và mỗi job chỉ được xử lý chính xác một lần. (Yêu cầu này nghe có vẻ đơn giản, nhưng việc hiện thực không dễ.)
- Nếu bằng cách nào đó việc xử lý job không thành công do một lỗi xảy ra (lỗi mạng, lỗi đĩa cứng, …) mà không phải lỗi do logic của job, job cần được đưa lại vào queue để được xử lý lại sau đó.
Thực tế cho thấy, việc xây dựng một job queue sử dụng PostgreSQL/SQL hỗ trợ những yêu cầu trên là không dễ. Vấn đề khó nhất phải kể đến, chính là phải xây dựng được cơ chế đánh dấu một job là đã lấy, nhưng phải phục hồi lại job khi có lỗi xảy ra do worker xử lý job không thành công (timeout, OOM, network failure...), nếu không job sẽ bị mất.
Để giải quyết bài toán này, team Holistics đã thử các phương án khác nhau, cho đến khi bắt gặp tính năng SKIP LOCKED của Postgres 9.5, một tính năng được thiết kế đặc biệt phù hợp cho mục đích này. Đọc link này của tác giả Craig Ringer để tìm hiểu thêm [1].
Về cơ bản, ý tưởng của việc sử dụng tính năng SKIP LOCKED của Postgres 9.5 là:
- Trong một transaction, bạn viết một câu query SQL để lấy được row tiếp theo có sẵn mà không bị lock, sau đó bạn thực hiện việc khóa row trên đó, do đó, miễn là transaction vẫn tiếp tục (bạn vẫn yêu cầu nó), không có process nào có thể yêu cầu điều đó.
- Nếu job thành công, bạn cập nhật trạng thái của row thành success và kết thúc transaction
- Nếu process của bạn bị crash, transaction sẽ tự động bị hủy bỏ, và hủy bỏ yêu cầu với row.
Vui lòng đọc code dưới đây để hiểu thêm.
Hỗ trợ Multi-tenancy
Một bài toán khác mà team Holistics phải hỗ trợ đó là chia tách hàng đợi job của các khách hàng khác nhau. Để làm được điều này, team mình thiết kế một bảng tenant queue như sau, trong đó field (tenant_id) là duy nhất (unique) cho từng khách hàng
CREATE TABLE tenant_queues ( id INTEGER PRIMARY KEY, tenant_id INTEGER, num_slots INTEGER )
Cơ chế chống trùng lặp Job và cơ chế retry
Rất nhiều thời điểm người dùng vô tình lạm dụng hệ thống khi nhấn refresh nhiều lần trong trang báo cáo, gây ra một job mới được tạo ra và gửi đến hàng đợi để thực thi, vô tình gây nên quá tải cho hệ thống một cách không cần thiết.
Để xử lý vấn đề này, team mình cũng đã xây dựng cơ chế chống trùng lặp job. Mỗi lần job được gửi, nó sẽ kiểm tra xem có job nào tương tự (job tạo ra có chung query như job cũ) đã được gửi nhưng chưa hoàn thành trong 10 phút vừa qua hay chưa. Nếu tìm thấy, hệ thống sẽ chỉ đơn giản trả về ID của job cũ vừa tìm được.
Team cũng đã thêm một cơ chế retry, tự động chạy lại job trong trường hợp process crash (OOM hoặc event bất ngờ) theo một số lần nhất định.
Code minh họa
Để dễ cho bạn đọc hình dung, mình đính kèm một vài đoạn code minh họa cho các thiết kế ở trên.
Đầu tiên, hãy xem xét câu lệnh SQL có chức năng sau: tìm job đầu tiên trong danh sách thỏa mãn yêu cầu tiếp theo sẵn sàng (theo thứ tự) mà tenant vẫn còn slot trống, đó là không ai đã claim (SKIP LOCKED) và claim nó cho bản thân mình (FOR UPDATE)
-- finds out how many jobs are running per queue, so that we know if it's full
WITH running_jobs_per_queue AS (
SELECT
tenant_id,
count(1) AS running_jobs from jobs
WHERE (status = 'running' OR status = 'queued') -- running or queued
AND created_at > NOW() - INTERVAL '6 HOURS' -- ignore jobs running past 6 hours ago
group by 1
),
-- find out queues that are full
full_queues AS (
select
R.tenant_id
from running_jobs_per_queue R
left join tenant_queues Q ON R.tenant_id = Q.tenant_id
where R.running_jobs >= Q.num_slots
)
select id
from jobs
where status = 'created'
and tenant_id NOT IN ( select tenant_id from full_queues )
order by id asc
for update skip locked
limit 1
Team mình định nghĩa một method queue_next_job() để chọn job tiếp theo và chuyển chúng xuống cho Sidekiq thực hiện. Lưu ý là job này được wrap trong một transaction, do đó, trong khi update status thành queued, không có process khác có thể claim job, đảm bảo nó không bao giờ bị chọn hai lần.
class Job
def queue_next_job()
ActiveRecord::Base.transaction do
ret = ActiveRecord::Base.connection.execute queue_sql
return nil if ret.values.size == 0
job_id = ret.values[0][0].to_i
job = Job.find(job_id)
# send to background worker
job.status = 'queued' && job.save
JobWorker.perform_async(job_id)
end
end
end
Và trong JobWorker chạy bởi Sidekiq, chúng mình thiết lập trạng thái của job tương ứng là running, sau đó bắt đầu quá trình thực thi job.
# simplified code
class JobWorker
include Sidekiq::Worker
def perform(job_id)
job = Job.find(job_id)
job.status = 'running' && job.save
obj = job.source_type.constantize.find(job.source_id)
obj.call(job.source_method, job.args)
job.status = 'success' && job.save
rescue
job.status = 'error' && job.save
ensure
Job.queue_next_job()
end
end
Chú ý method queue_next_job() được gọi trong block. Không giống như hệ thống job queue khác, nơi thường có một process supervisor để theo dõi queue, chọn job và đưa cho worker tiếp theo. Với hệ thống của Holistics, team mình đã gỡ bỏ khái niệm supervisor/worker, và chỉ cần sử dụng worker hiện tại để gọi queue_next_job ngay sau khi hoàn thành việc xử lý job hiện tại (scheduling work) và để Sidekiq handle việc chạy background worker.
| Job Queue Khác | Job Queue của chúng tôi | |
|---|---|---|
| Master | Dành riêng process để nhận request | SQL + inline with Rails hiện tại hoặc process Sidekiq |
| Workers | Dành riêng process hoặc thread | Đi qua Sidekiq |
Comment về Sidekiq: Sidekiq là một hệ thống background job worker rất tốt. Sau một thời gian sử dụng bản free, team cũng đã quyết định trả tiền cho các tính năng có trả phí vì dùng khá hiệu quả. Postgres job queue của Holistics chạy trên Sidekiq, xử lý các logic business của job tốt hơn, trong khi Sidekiq sẽ lo việc thực hiện job.
Ngoài ra, do tính chất job (thời gian xử lý job dài có thể dẫn đến tình trạng out-of-memory do job chiếm dụng bộ nhớ quá lâu), team mình cũng đã gợi ý thêm cho phía Sidekiq để nâng cấp bổ sung một process giám sát cũng như một cơ chế quản lý ngưỡng memory trên các process của Sidekiq. Mình sẽ quay lại với chủ đề này trong một bài viết khác.
Abstract Background Job Logic
Trước khi kết bài, còn một thiết kế nhỏ trong hệ thống job queue của Holistics mà mình muốn đề cập, đó là việc tạo ra method .async (nhờ cơ chế meta-programming của Ruby mà việc tạo ra method này khá đơn giản), giúp việc chuyển đổi giữa 2 cơ chế sync và async cực kỳ đơn giản).
Trong đoạn code dưới đây, method DataReport# có thể được viết một lần và chạy cho cả sync và async.
report = DataReport.find(report_id) # normal: execute synchronously, this returns the return value of `execute` method report_results = report.execute # execute asynchronously, this returns a job ID (int) job_id = report.async.execute
Bằng cách hiện thực này, team đã hoàn toàn ẩn Sidekiq khỏi code logic sử dụng nó. Nhờ vậy, khi muốn triển khai sử dụng một background worker khác, một adapter mới có thể dễ dàng được viết để hỗ trợ một hệ thống mới một cách dễ dàng.
Ngoài ra, lưu ý sự kết hợp (source_type, source_id, source_method) trong bảng jobs ở trên, là ứng dụng của đa hình (polymorphism), là cách team phân chia thành các loại job khác nhau.
Kết luận
Trong bài viết này, mình đã trình bày cách thức và lý do tại sao team Holistics thiết kế hệ thống multi-tenant job queue sử dụng Ruby, PostgreSQL và Sidekiq. Tính đến thời điểm hiện tại, hệ thống job queue đang chạy ổn, linh hoạt và đáng tin cậy cũng như đáp ứng được các yêu cầu đề ra ban đầu như:
- Các job đã được gửi được lưu trong job table, giúp hệ thống dễ dàng phân tích hoặc cung cấp thông tin cho khách hàng khi có yêu cầu troubleshoot.
- Hàng đợi job cho từng khách hàng được tách bạch, cho phép mỗi khách hàng có queue riêng của họ mà không ảnh hưởng lẫn nhau, giúp hệ thống sử dụng tài nguyên của CPU được chia sẻ tốt hơn.
- Hỗ trợ abstract code tốt, giúp cho các developer làm việc nâng cấp cũng như mở rộng hệ thống dễ dàng hơn sau này.
Nếu bạn có bất kỳ phản hồi hoặc nhận xét nào thì comment dưới đây để mọi người cùng trao đổi nhé.
Team cũng sẽ có 1 bài talk chia sẽ về hệ thống trên ở Grokking TechTalk #24 vào ngày 10 Mar 2018 tới, bạn nào ở Saigon hứng thú có thể đến tham dự và trao đổi thêm nhé.
Nếu bạn cảm thấy hứng thú với những bài toán hệ thống như trên, team mình đang cần tìm 1 đồng đội Fullstack Engineer & 1 đồng đội Backend Engineer (JD tương tự) ngồi ở HCM chung với team.
Team nhỏ & trẻ (7 engineers), môi trường hoà đồng & lầy, code đến đâu test & refactor đến đó, đã deploy thì integration tests phải pass hết mới deploy còn deadline thì tính sau....Bạn nào hứng thú xem thêm ở đây nha

