Tìm hiểu về SSD MultiBox Real-Time Object Detection
Ngày nay, những mô hình mạng neural đang trở nên ngày càng phổ biến, và trong bài toán phân loại ảnh (image classification) chúng thậm chí còn vượt trội hơn con người về độ chính xác. Tuy nhiên, con người xử lí rất nhiều bài toán hàng ngày hơn là chỉ ngồi phân loại ảnh ví dụ như quan sát và tương ...
Ngày nay, những mô hình mạng neural đang trở nên ngày càng phổ biến, và trong bài toán phân loại ảnh (image classification) chúng thậm chí còn vượt trội hơn con người về độ chính xác. Tuy nhiên, con người xử lí rất nhiều bài toán hàng ngày hơn là chỉ ngồi phân loại ảnh ví dụ như quan sát và tương tác với môi trường xung quanh. Chúng ta có thể định vị và phân loại từng đối tượng trong tầm mắt một cách dễ dàng do sức mạnh của não bộ vượt xa những gì mà mạng neural "hàng fake" có thể làm. Trong thực tế, có rất nhiều bài toán có thể giải quyết bằng mạng neural nhưng hầu hết chúng vẫn chưa thể đạt được hiệu năng như con người, và Object Detection là một trong số những bài toán đó. Trong bài viết này mình sẽ giới thiệu tổng quan về một mô hình mạng với tên gọi SSD (Single Shot MultiBox Detector) được sử dụng phổ biến và đem lại hiệu quả khá cao khi chạy với thời gian thực.
Với những bước nhảy lớn trong những bài toán về thị giác máy tính với mạng CNNs, một mô hình mạng mang tên R-CNNs đã được công bố để giải quyết bài toán Object Detection, Localization và Classification. Nhìn chung, R-CNN là một loại CNN đặc biệt có khả năng định vị và nhận biết được các đối tượng trong ảnh: đầu ra của mạng thường là một tập những bounding box bao quanh những đối tượng được nhận biết, cũng như nhãn của đối tượng được phân vào. Hình ảnh dưới dây minh họa đầu ra của mạng R-CNN:
 Sau R-CNN, một vài mô hình mạng khác cũng được phát triển (Fast-R-CNN, Faster-R-CNN) dựa trên nó với mục đích chính là cải thiện thời gian huấn luyện và độ chính xác của mô hình với mong muốn áp dụng được với những bài toán chạy với thời gian thực. Tuy nhiên chúng vẫn tồn tại một số hạn chế:
Sau R-CNN, một vài mô hình mạng khác cũng được phát triển (Fast-R-CNN, Faster-R-CNN) dựa trên nó với mục đích chính là cải thiện thời gian huấn luyện và độ chính xác của mô hình với mong muốn áp dụng được với những bài toán chạy với thời gian thực. Tuy nhiên chúng vẫn tồn tại một số hạn chế:
- Việc huấn luyện mô hình vẫn quá cồng kềnh và tiêu tốn nhiều thời gian.
- Quá trình huấn luyện xảy ra trên nhiều phase.
- Mô hình mạng làm việc chậm so với thời gian thực.
May mắn thay, trong những năm trở lại đây, những kiến trúc mạng mới được phát triển để giải quyết những vấn đề tồn tại trong R-CNN, khiến việc giải quyết bài toán Object Detection có thể thực hiện được trong thời gian thực. Những mô hình mạng nổi tiếng nhất là YOLO (You Only Look Once) và SSD MultiBox. Phần tiếp theo của bài viết sẽ tập trung sâu vào ý tưởng và kiến trúc mạng SSD.
Để hiểu được ý tưởng mà mô hình sử dụng, đầu tiên ta hãy tìm hiểu xem tên của mô hình có ý nghĩa gì:
- Single Shot: Có nghĩa là việc định vị và phân loại đối tượng được thực hiện trên 1 phase duy nhất từ đầu đến cuối.
- MultiBox: Tên của kĩ thuật về bounding box được sử dụng bởi Szegedy et al.
- Detector: Mạng này có khả năng nhận biết và phân loại được đối tượng.
Kiến trúc mạng
 Các bạn có thể thấy trên lưu đồ, kiến trúc của SSD được xây dựng trên VGG-16 được loại bỏ tầng fully-connected. Lí do mà VGG-16 được sử dụng như tầng cơ sở là vì sự hiệu quả của nó trong bài toán phân loại ảnh với các ảnh có độ phân giải cao. Thay vì sử dụng tầng fully-connected của VGG, một tập các tầng convolution phụ trợ (cụ thể là 6 trong lưu đồ) được thêm vào, vì vậy ta có thể trích xuất được các features với nhiều tỉ lệ khác nhau, và giảm gần kích thước của đầu vào trong từng tầng mạng.
Các bạn có thể thấy trên lưu đồ, kiến trúc của SSD được xây dựng trên VGG-16 được loại bỏ tầng fully-connected. Lí do mà VGG-16 được sử dụng như tầng cơ sở là vì sự hiệu quả của nó trong bài toán phân loại ảnh với các ảnh có độ phân giải cao. Thay vì sử dụng tầng fully-connected của VGG, một tập các tầng convolution phụ trợ (cụ thể là 6 trong lưu đồ) được thêm vào, vì vậy ta có thể trích xuất được các features với nhiều tỉ lệ khác nhau, và giảm gần kích thước của đầu vào trong từng tầng mạng.
Multibox
Kĩ thuật bounding box được sử dụng trong SSD được lấy ý tưởng từ Szegedy (https://arxiv.org/abs/1412.1441), một phương pháp sử dụng nhiều bounding box phù hợp với mọi đối tượng lớn nhỏ. Dưới đây là kiến trúc của multi-scale convolution prediction được sử dụng trong SSD.
 Hàm lỗi của MultiBox là sự kết hợp của 2 thành phần tương ứng với 2 chức năng của SSD:
Hàm lỗi của MultiBox là sự kết hợp của 2 thành phần tương ứng với 2 chức năng của SSD:
- Confidence Loss: thành phần này tính toán tỉ lệ rơi vào class mà bounding box được tính toán. Độ đo cross-entropy được sử dụng để đo thành phần này.
- Location Loss: Thành phần này ước lượng sự sai lêch thực tế của bounding box so với tập dữ liệu mẫu. L2-Norm được sử dụng ở đây.
Mình sẽ không đi quá sâu vào phần toán học trong mô hình (bạn có thể đọc thêm trong paper (https://arxiv.org/abs/1512.02325) nếu thực sự muốn tìm hiểu. Hàm loss được xây dựng với 2 thành phần trên có công thức như sau:
multibox_loss = confidence_loss + alpha * location_loss
Giá trị alpha giúp chúng ta cân bằng được sự ảnh hưởng của location loss. Cũng như nhiều mô hình mạng trong deep learning, mục tiêu của chúng ta là tìm những giá trị tham số có thể tối thiểu được hàm Loss tốt nhất, theo đó đưa ra được những dự đoán càng gần với dữ liệu mẫu.
MultiBox Prior And IoU
Logic xoay quanh việc taoj ra bounding box thực sự khá phức tạp. Trong MultiBox, một khái niệm được sử dụng là priors (hay thuật ngữ anchors trong Faster-R-CNN), là những bounding box được tính toán trước với kích thước cố định tuân theo phân phối gần với phân phối của bounding box mẫu. Trong thực tế, những priors này được lựa chọn khi tỉ lệ Intersection/Union (IoU) lớn hơn ngưỡng 0.5. Như mô tả trong hình dưới dây, giá trị IoU tại 0.5 vẫn chưa đủ tốt nhưng nó sẽ là một điểm bắt đầu tương đối ổn cho thuật cho giải thuật bounding box regression (chính là việc học tham số của mạng) - điểu này thực sự sẽ tiết kiệm thời gian và đem lại kết quả tốt hơn rất nhiều so với việc bắt đầu tại một vị trí ngẫu nhiên.
Do đó MultiBox bắt đầu với priors như một prediction khởi tạo với mục đích hồi quy gần hơn với bounding box thực sự.
 Kiến trúc của Multibox bao gồm 11 priors với mỗi feature map cell (8x8, 6x6, 4x4, 3x3, 2x2) và chỉ 1 prior với 1x1 feature map dẫn đến tổng cộng có 1420 priors với mỗi hình ảnh, do đó cho phép bao phủ hoàn toàn một bức ảnh đầu vào trên những tỉ lệ khác nhau, khiến việc nhận diện những đối tượng ở các kích thước khác nhau trở nên dễ dàng.
Kiến trúc của Multibox bao gồm 11 priors với mỗi feature map cell (8x8, 6x6, 4x4, 3x3, 2x2) và chỉ 1 prior với 1x1 feature map dẫn đến tổng cộng có 1420 priors với mỗi hình ảnh, do đó cho phép bao phủ hoàn toàn một bức ảnh đầu vào trên những tỉ lệ khác nhau, khiến việc nhận diện những đối tượng ở các kích thước khác nhau trở nên dễ dàng.
SSD Improvements
Trở lại với SSd, một vài thay đổi nhỏ được thêm vào mạng để cải thiện khả năng nhận diện và phân loại đối tượng.
Fixed Priors:
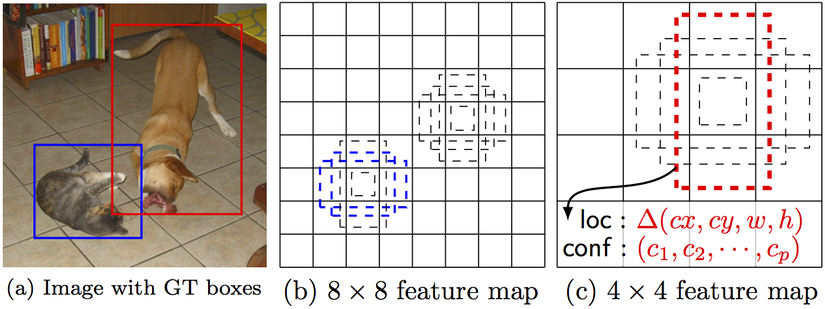
Không giống với MultiBox, mỗi feature map cell sẽ được gắn với một tập các bounding box mặc định với số chiều và tỉ lệ khác nhau. Các Priors này được lựa chọn bằng tay. Phương pháp này cho phép SSD tạo được bounding box cho bất kì kiểu đầu vào nào mà không yêu cầu một phase pre-trained nào cho việc tạo ra priors. Ví dụ, giả sử ta có 2 điểm là (x1, y1) và (x2, y2) với mỗi tập b bounding box mặc định cho mỗi feature map cell và c classes cho việc phan loại. Với một feature map có kích thước f = m x n, SSD sẽ tính ra f x b x (4+c) giá trị cho feature map này. Hình dưới đây minh họa cho ý tưởng của Fixed Priors:
Classification:
MultiBox không thể phân loại object,vì vậy, với mỗi bounding box được đưa ra, SSD tính toán luôn sự dự đoán cho việc phân loại của object vào các class có thể trong dataset.
Trong bài viết này, mình đã trình bày ý tưởng và những lí thuyết cơ bản của SSD, phần tiếp theo sẽ liên quan đến việc xây dựng mô hình và huấn luyện mạng này. Hãy chờ và đón đọc nhé.
(https://towardsdatascience.com/understanding-ssd-multibox-real-time-object-detection-in-deep-learning-495ef744fab) (https://medium.com/@jonathan_hui/ssd-object-detection-single-shot-multibox-detector-for-real-time-processing-9bd8deac0e06)
