Từ sự diệt vong của nhân loại (Mark Zuckerberg vs Elon Musk) tới trí thông minh nhân tạo
Gần đây, một cuộc khẩu chiến giữa 2 con người có tầm ảnh hưởng rất lớn trên thế giới: Mark Zuckerberg, nhà sáng lập mạng xã hội lớn nhất thế giới facebook, và Elon Musk, người cố gắng biến những giấc mơ của con người thanh hiện thực, nhà sáng lập SpaceX và đồng lập Tesla Motor và Paypal. Và chủ đề ...
Gần đây, một cuộc khẩu chiến giữa 2 con người có tầm ảnh hưởng rất lớn trên thế giới: Mark Zuckerberg, nhà sáng lập mạng xã hội lớn nhất thế giới facebook, và Elon Musk, người cố gắng biến những giấc mơ của con người thanh hiện thực, nhà sáng lập SpaceX và đồng lập Tesla Motor và Paypal. Và chủ đề họ tranh luận cũng nóng không kém tên tuổi của 2 con người này: liệu trí thông minh nhân tạo (Artificial Intelligence - AI) có dẫn đến sự diệt vong của loài người.
Trong khi Mark Zuckerberg lại ám chỉ CEO Tesla vô trách nhiệm khi nói AI là nguy cơ đối với sự tồn vong của con người thì Elon Musk cho rằng hiểu biết về AI của CEO Facebook là hạn chế. Vậy, thực chất AI là gì, mà lại có thể khiến cho 2 con người tiên phong của thế giới tranh luận gay gắt như thế.
Trí thông minh nhân tạo là ngành khoa học nghiên cứu lý thuyết và sự phát triển của hệ thống máy tính để có thể thực hiện công việc yêu cầu trí thông minh của con người như nhận diện hình ảnh, giọng nói, đưa ra quyết định, dịch ngôn ngữ…
Để tìm ra cách thức giúp máy móc giải quyết được những vấn đề phức tạp trong cuộc sống, ta cần đi từ những vấn đề đơn giản trước đã. Những vấn đề đại diện nhất, lại đến từ một bộ môn được được rất nhiều người yêu thích - trò chơi (gaming), nơi tồn tại những luật lệ cố định và mục tiêu rõ ràng. Và để tìm hiểu về trí thông minh nhân tạo, chúng ta cùng tìm hiểu về lịch sử cách thức (thuật toán) máy tính giải quyết các trò chơi trong thực tế.
1. Caro 3x3
Caro 3x3 có lẽ là một trò chơi phổ biến mà có lẽ không bạn nào không biết đến. Luật lệ vô cùng đơn giản, đánh X, O sao cho tạo được 1 cột, 1 hàng hoặc 1 đường chéo là thắng. Và với trò chơi dân dã này, cách thức máy tính giải quyết cũng đơn giản không kém: liệt kê tất cả các trường hợp có thể xảy ra.
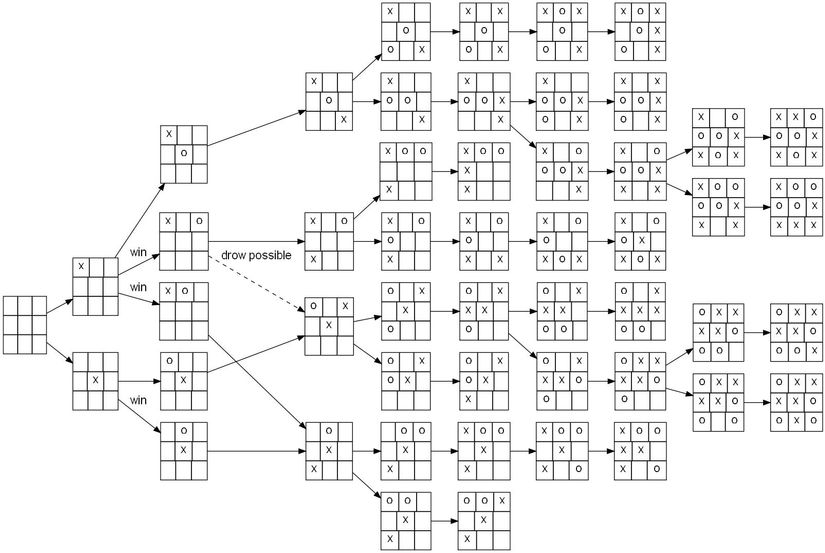 Rõ ràng, với một chiếc máy có thể nắm rõ 100% các trường hợp xảy ra ở những nước tiếp theo thì việc đưa ra những nước cờ tối ưu không phải là một điều gì khó khăn.
Rõ ràng, với một chiếc máy có thể nắm rõ 100% các trường hợp xảy ra ở những nước tiếp theo thì việc đưa ra những nước cờ tối ưu không phải là một điều gì khó khăn.
2. Cờ vua
Nếu như Caro 3x3 là một trò chơi đơn giản, thì cờ vua lại không hề dễ dàng đến thế. Bàn cờ có 64 quân, mỗi quân lại có cách đi khác nhau, 1 trận đấu hoàn toàn có thể kéo dài từ 50-100 nước. Để liệt kê được toàn bộ khả năng xảy ra là một điều không tưởng.
Năm 1997, Deep Blue được sáng chế bởi IBM đã đánh bại Garry Kasparov, kỳ thủ cờ vua hàng đầu thế giới. Deep Blue cũng sử dụng thuật toán tìm kiếm (liệt kê tất cả các nước) ở 6-8 nước tiếp theo dựa vào sức mạnh của máy tính. Thêm vào đó, IBM đã tập hợp dữ liệu của hàng trăm ngàn các thế cờ khác nhau (4.000 thế khai cờ, 700.000 thế trung và tàn cuộc), dựa trên kết quả thắng thua của các trận đấu để tìm ra một thuật toán đưa ra khả năng thắng ở mỗi nước đi. Thuật toán đó gồm 8.000 phần khác nhau, và rất nhiều phần được viết riêng biệt cho các thế đặc biệt.
Như vậy, Deep Blue dựa vào công nghệ máy tính để liệt kê các trường hợp xảy ra xa nhất có thể, dựa vào khả năng chiến thắng ở bước cuối để đưa ra bước đi chuẩn xác nhất. Và cuối cùng, thì máy tính có thể đánh bại con người trong cờ vua.
Mặc dù đã thành công trong việc giành chiến thắng, thuật toán của Deep Blue cũng đưa ra rất nhiều hạn chế: yêu cầu sức mạnh công nghệ, tính chính xác của thuật toán và công sức bỏ ra để khởi tạo thuật toán đó.
3. Cờ vây
Với những hạn chế đó, thuật toán không thể áp dụng được với cờ vây. Trò chơi với luật lệ đơn giản hơn nhưng số trường hợp xảy ra game đấu lại lớn hơn rất nhiều (10 ^ 761 so với 10 ^ 120 ở cờ vua). Chính bởi lẽ đó, phải gần 20 năm sau, tháng 3 năm 2016, trí thông minh nhân tạo, cỗ máy Alpha Go mới có thể đánh bại con người (Lee Sedol - kỳ thủ có chỉ số Elo cao thứ 2 thế giới, tỉ số 4-1). Câu hỏi lớn nhất dặt ra là: làm cách nào?
Alpha Go dựa vào 2 thuật toán chính: Cây tìm kiếm Monte Carlo (Monte Carlo Search Tree) và mạng nơ-ron tích chập (Convolutional Neuron Network).
3.1. Cây tìm kiếm Monte Carlo
Cây tìm kiếm Monta Carlo tập trung vào việc chạy quá trình giả lập thật nhiều lần. Ở thời điểm ban đầu, máy tính sẽ bắt đầu những hành động ngẫu nhiên cho đến khi kết thúc trò chơi. Với mỗi hành động xảy ra và điểm số sau mỗi lượt, kết quả sẽ được lưu trữ vào bộ nhớ máy tính. Khi dữ liệu ngày càng nhiều lên, máy tính lại càng ngày càng có cơ sở để biết được hành động tốt hơn, và càng ngày, những hành động được thực hiện lại trở lên ít ngẫu nhiên hơn, đem lại kết quả tốt hơn.
Cây tìm kiếm Monta Carlo cần tìm điểm cân bằng giữa khai phá và khai thác (exploration vs exploitation). Khai phá - sẵn sàng sáng tạo thực hiện một hành động chưa từng thực thi trước đó bao giờ sẽ mở rộng dữ liệu và những tình huống xảy ra, giúp kết quả chính xác hơn nhưng tiêu tốn nhiều bộ nhớ và thời gian thực hiện cũng lâu hơn. Trong trường hợp cây tìm kiếm đã tìm được điểm tối ưu (hoặc gần tối ưu) thì việc tăng cường độ khai phá có thể không mang lại kết quả tốt hơn. Khai thác - tập trung tận dụng dữ liệu đã có để giải quyết bài toán thay vì đi tìm hướng mới.
Để tìm hiểu rõ hơn về cây tìm kiếm Monte Carlo, hãy cùng nhau theo dõi trí thông minh nhân tạo đã chơi game Mario như thế nào
3.2. Mạng nơ-ron tích chập
Mạng nơ-ron tích chập tập trung vào nhận diện và phân loại, được ứng dụng rất nhiều trong nhận diện hình ảnh, giọng nói. Thuật toán này lấy dữ liệu đầu vào, dữ liệu sẽ được đi qua một loạt các lớp, ở mỗi lớp lại có thêm những thuật toán, cứ lặp lại như vậy cho tới khi trích xuất được kết quả cuối cùng.
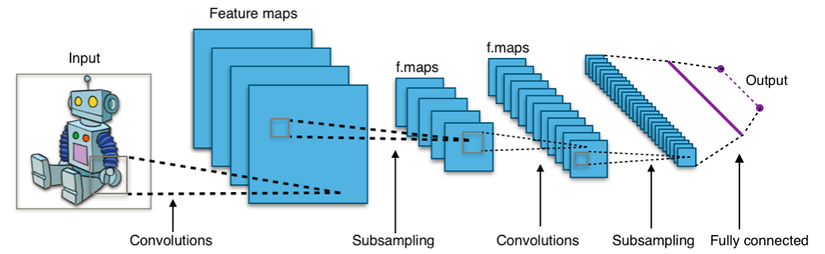
Dưới đây là 1 trong những ứng dụng đầu tiên của mạng nơ-ron tích chập - nhận diện chữ số với hình dạng, kích thước, chữ viết tay khác nhau (như một con người thật sự)
Từ hơn 30 triệu thế cờ vây khác nhau, ứng dụng mạng nơ-ron tích chập tạo ra mạng lưới chính sách (policy network): tập hợp khả năng một nước có thể đi và tần suất lặp lại ở một thế cờ nhất định, từ đó làm định hướng cho hành động của máy tính.
Bằng việc so sánh nước đi được gợi ý của mạng lưới chính sách và nước đi thật sự của các kỳ thù, 57% nước đi được tìm thấy là giống nhau. Điều này nói lên rằng hầu hết các nước đi của các kỳ thủ đến từ trực giác hơn là tự nhìn lại, nghiền ngẫm và cải tiến. (Hãy nhớ là mạng lưới chính sách được lập ra đơn giản dựa trên xác suất các nước đi - sự quen thuộc)
Dựa trên mạng lưới chính sách, hơn 30 triệu game nữa đã được chơi bởi máy tính, từ đó tạo nên mạng lưới giá trị (tương tự như xác suất chiến thắng ở mỗi nước đi trong Deep Blue). Giá trị của mỗi nước đi giờ đây đã được tạo ra bởi máy tính, thay vì hàm số hàng ngàn phần bởi còn người.
Mục đích của việc tạo ra cỗ máy không đơn thuần chỉ để giải và đạt đến trình độ của con người, mà còn vượt lên trên cả giới hạn đó. Chính vì vậy, đơn thuần sử dụng mạng chính sách (bị giới hạn bởi tập nước đi trước đó) là không đủ.
3.3. Sự kết hợp hoàn hảo
Alpha Go = mạng nơ-ron tích chập + cây tìm kiếm Monta Carlo ~= mạng giá trị + kết quả của những game giả lập.
Điều này có nghĩa là, Alpha Go tự “khai phá” và “khai thác” các nước đi mới, cập nhật bổ sung kết quả của những game giả lập vào mạng lưới chính sách và giá trị của mình. Và từ đó tạo nên những nước cờ “so beautiful, not by human” - theo kỳ thủ Lee Sedol.
Sự chiến thắng của máy tính trong cờ vây đã tạo nên một bước đột phá rất lớn, bởi con người đã không còn phải tạo ra những mạng giá trị bằng tay như trước nữa. Trí thông minh nhân tạo cũng đã tự biết suy nghĩ để tìm ra giải pháp mới thay thế những gì cố hữu. Và quan trọng nhất, thuật toán này hoàn toàn có thể áp dụng trong rất rất nhiều ngành nghề khác nữa.
4. Dota
Chỉ sau hơn 1 năm kể từ khi Alpha Go đánh bại con người, lại một trí thông minh nhân tạo khác được tạo ra, nhưng ở một trò chơi khó và phức tạp hơn rất nhiều. Và trí thông minh này, được bắt nguồn không phải từ ai khác, mà chính là Elon Musk. Để chứng minh sự nguy hiểm của trí thông minh nhân tạo, ông đã tạo ra nhóm OpenAI, nghiên cứu trí thông minh nhân tạo ở những trò chơi thậm chí còn khó khăn hơn rất nhiều nữa – Dota, một trò chơi có hàng ti tỉ hành động và cách đi tại mỗi thời điểm. Sau 1 tháng được đào tạo, trí thông minh nhân tạo đã khiến những con game thủ tài năng nhất thể giới chỉ có thể thốt lên rằng: “it is a smarter version of me”.
Với tốc độ phát triển vũ bão như hiện nay, liệu thế giới này sẽ đi về đâu? “Thậm chí khi robot cầm súng giết hại con người, chúng ta vẫn còn đang chưa biết phải ứng phó như thế nào” - đó là quan ngại của Elon Musk, trong khi Mark Zuckerberg lại tin tưởng vào việc sử dụng trí thông minh nhân tạo để làm những công việc không tưởng “hạn chế sự nóng lên của trái đất, bảo vệ bầu khí quyển, cung cấp đủ lương thực...”.
Có người háo hức với sự phát triển của trí thông minh nhân tạo, có người lo sợ, nhưng dù thế nào, đó là con đường 1 chiều mà thế giới chắc chắn sẽ trải qua. Và mỗi người trong chúng ta đều có những kịch bản riêng.
Liệu có khi nào, một cỗ máy được tạo ra với nhiệm vụ tối cao là bảo vệ sự tồn tại của trái đất, và rồi sau rất nhiều phân tích, máy tính nhận ra rằng, cách duy nhất là tiêu diệt loài người...
Nguồn: https://www.theatlantic.com/technology/archive/2017/07/musk-vs-zuck/535077/ https://www.tastehit.com/blog/google-deepmind-alphago-how-it-works/ https://qz.com/1052409/openai-just-beat-a-professional-dota-2-player-at-the-international-2017/
