Viết những truy vấn hiệu quả trong Rails
Viết ra những câu truy vấn hiệu quả mà có thể cân bằng hiệu suất và bộ nhớ sử dụng là một phần vô cùng quan trọng của một ứng dụng tốt. Còn nhớ, khi mới bắt đầu làm quen với Rails, làm việc trong những dự án nhỏ, tôi thường ít quan tâm đến việc tối ưu hóa các câu truy vấn của mình, vì số lượng ...
 Viết ra những câu truy vấn hiệu quả mà có thể cân bằng hiệu suất và bộ nhớ sử dụng là một phần vô cùng quan trọng của một ứng dụng tốt.
Viết ra những câu truy vấn hiệu quả mà có thể cân bằng hiệu suất và bộ nhớ sử dụng là một phần vô cùng quan trọng của một ứng dụng tốt.
Còn nhớ, khi mới bắt đầu làm quen với Rails, làm việc trong những dự án nhỏ, tôi thường ít quan tâm đến việc tối ưu hóa các câu truy vấn của mình, vì số lượng dữ liệu cũng như quan hệ giữa các bảng trong cơ sở dữ liệu là không nhiều, nên việc ứng dụng chạy nhanh hay chậm khá là khó để nhận biết. Nhưng khi vào những dự án lớn, số lượng các bảng nhiều, cộng với lượng dữ liệu trong mỗi bảng cũng rất lớn, tôi mới thực sự cảm nhận được sự chậm chạp của ứng dụng. Lúc đó, tôi đã tìm hiểu và tìm ra được một số cách giúp cải thiện điều này.
Giả sử có 2 bảng users và posts trong database với quan hệ như sau:
class User < ActiveRecord::Base
has_many :posts
end
class Post < ActiveRecord::Base
belongs_to :user
end
Sử dụng includes
Vấn đề N+1 queries
Xem xét đoạn code sau đây, nó tìm 5 bài post và in ra tên của những user đã viết ra:
posts = Post.limit(5) posts.each do |post| puts post.user.name end
Thoạt nhìn, đoạn code trên có vẻ ổn đó. Nhưng hãy xem xét đến số lượng truy vấn nó đã thực thi:
Post Load (0.5ms) SELECT `posts`.* FROM `posts` LIMIT 5 User Load (0.3ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 User Load (0.3ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 User Load (0.3ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 2 LIMIT 1 User Load (0.3ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 2 LIMIT 1 User Load (0.3ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1
Nó đã thực thi 1 truy vấn (để tìm 5 posts) + 5 truy vấn (mỗi truy vấn trên một post để load user) = 6 truy vấn tất cả.
Giải quyết vấn đề N+1 queries
Bằng cách sử dụng includes, Active Record sẽ đảm bảo rằng tất cả các associations xác định sẽ được load sử dụng số lượng truy vấn ít nhất có thể. Xem xét lại trường hợp trên, chúng ta sẽ viết lại Post.limit(5) để eager load các users:
posts = Post.includes(:user).limit(5) posts.each do |post| puts post.user.name end
Đoạn code trên sẽ chỉ thực thi 2 truy vấn, thay vì 6 truy vấn trong trường hợp trên:
Post Load (0.3ms) SELECT `posts`.* FROM `posts` LIMIT 5 User Load (0.3ms) SELECT `users`.* FROM `users` WHERE `users`.`id` IN (1, 2)
Tiết kiệm thời gian với Transaction
Khi cập nhật nhiều records với cùng một dữ liệu giống nhau, ví dụ khi muốn đổi tất cả các User có role là admin thành role là member, việc đó khá là dễ dàng với update_all():
User.where(role: :admin).update_all(role: :member)
Và kết quả sẽ chỉ cần sử dụng 1 query duy nhất:
SQL (88.5ms) UPDATE `users` SET `users`.`role` = 'member' WHERE `users`.`role` = 'admin'
Nhưng, khi những records cần được cập nhật với những giá trị khác nhau, tình hình sẽ trở nên khó khăn. Việc cập nhật trong trường hợp này sẽ không thể nào trong 1 query. Tuy nhiên, bao chúng trong một transaction block sẽ nâng cao hiệu năng đáng kể.
Điều quan trọng cần nhớ ở đây là việc bao các updates vào trong một transaction sẽ không cập nhật tất cả các records một lần, và nó vẫn sẽ sử dụng cùng số lượng truy vấn, nhưng nó sẽ cam kết "giao dịch" chỉ một lần.
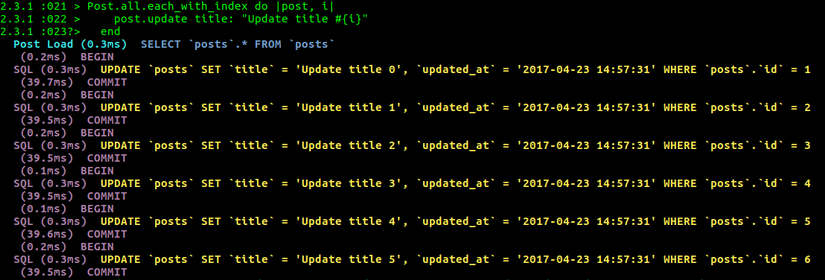
Để hiểu được điều này, hãy xem xét đoạn code để cập nhật title của nhiều posts khi mà chúng chưa được bao trong một transaction:
Post.all.each_with_index do |post, i| post.update title: "Update title #{i}" end
Bạn sẽ thấy những truy vấn sau đây:
Nhưng khi chúng ta bao các updates ở trong transaction như sau:
ActiveRecord::Base.transaction do Post.all.each_with_index do |post, i| post.update title: "Update title #{i}" end end
Kết quả truy vấn trong trường hợp này sẽ như sau:
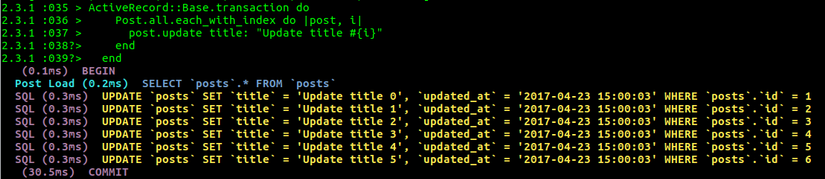
Bạn thấy rồi đấy, thời gian được cải thiện hơn rất nhiều khi sử dụng transaction đúng không nào ^^
select, map or pluck?

- select() sẽ fetch các trường đã chọn và trả về một ActiveRecord::Relation object chứa các user object với các trường đã chọn mà bạn có thể truy cập được đến tất cả methods và relations của chúng.
- map() sẽ fetch data từ tất cả các trường trong một bảng, nhưng nó trả về một Array chỉ chứa các giá trị của trường đã chọn.
- pluck() sẽ chỉ fetch các trường đã chọn, sau đó nó trả về một Array chứa các giá trị của trường đã chọn và sử dụng ít bộ nhớ hơn.
Khi chỉ cần lấy ra giá trị của một vài trường nhất định nào đó từ một bảng với một điều kiện nhất định, ta sẽ sử dụng pluck(). Còn khi chúng ta chỉ muốn truy cập đến các method hoặc relations của những record đang tìm kiếm, ta sẽ dùng select().
find_each vs each
Giả sử bạn cần thực hiện một số xử lý trên mỗi một đối tượng Post. Đối với một tập dữ liệu nhỏ, sử dụng each sẽ làm việc ổn:
Post.all.each { |p| .... }
Nhưng khi mà tập dữ liệu lên đến hàng trăm nghìn bản ghi, .all.each sẽ nạp toàn bộ kết quả vào bộ nhớ để duyệt trên array. Tại thời điểm này, rất có thể ứng dụng sẽ bị tràn bộ nhớ do quá tải.
Để ngăn việc này xảy ra, ActiveRecord cung cấp phương thức find_each, trong đó các truy vấn sẽ được đặt theo batch 1000 (giá trị mặc định), để toàn bộ kết quả không được nạp vào bộ nhớ cùng một lúc. Chúng ta sử dụng find_each như sau:
Post.all.find_each { |p| ...}
SQL#distinct or Array#uniq
Giả sử bạn muốn tạo ra một list các user_id từ bảng posts. Sử dụng phương thức pluck ở trên, chúng ta dễ dàng có được list này. Có 2 cách để lọc những user_id bị trùng lặp từ list:
Post.pluck(:user_id).uniq
Post.distinct.pluck(:user_id)

- Cách thứ nhất, pluck sẽ query tất cả các user_id cho mỗi một record post, sau đó load kết quả vào một Array. Những user_id trùng lặp được lọc ra sử dụng Array#uniq
- Cách thứ hai, distinct là phương thức ActiveRecord::QueryMethods#uniq, nó sẽ sử dụng từ khóa DISTINCT trong câu lệnh SQL để chỉ lấy ra những giá trị user_id khác nhau. Do đó, nó sẽ hoạt động nhanh và hiệu quả hơn so với cách đầu tiên.
count vs length vs size
-
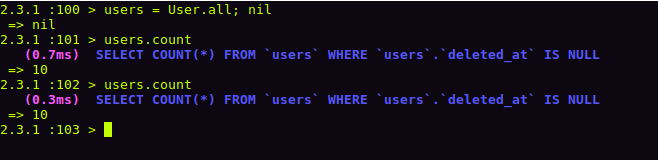
count
- Đếm số lượng records mà chúng ta truy vấn sử dụng câu lệnh SQL (SELECT COUNT(*) FROM...)
- #count không được lưu trữ trong vòng đời của đối tượng, vì vậy mỗi lần gọi phương thức này, nó sẽ thực hiện lại câu truy vấn. Tuy nhiên, truy vấn COUNT(*) trong SQL thực hiện rất nhanh
-
length
- Đếm số lượng records mà không cần thực hiện thêm câu truy vấn nếu như những records đó đã được load
- Ngược lại, #length sẽ load toàn bộ records vào trong bộ nhớ và thực hiện đếm (thật không hay chút nào (>'<) )

-
size
- Kết hợp khả năng của cả 2 phương thức trên
- Nếu những records đã được load, nó sẽ thực hiện đếm mà không truy vấn vào CSDL nữa
- Nếu những records chưa được load, nó sẽ thực hiện đếm sử dụng câu lệnh SQL (SELECT COUNT(*) FROM...)
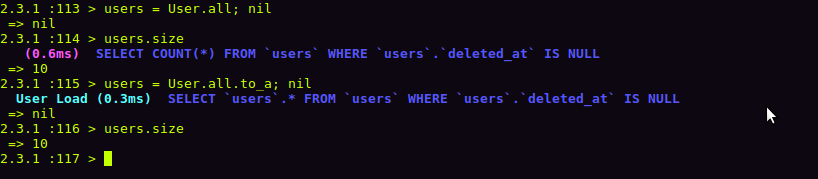
=> Từ đây ta có thể kết luận được rằng, dùng #size sẽ là sự lựa chọn hiệu quả và tốt nhất.
empty? or blank?
- blank? return true khi mà mối quan hệ trống
- empty? return true khi không tìm thấy record nào cả

Kết quả truy vấn ở trên có thể cho ta thấy cách thức hoạt động của 2 phương thức này như sau:
- blank?
- Truy vấn CSDL tất cả users có role là admin
- Load các users tìm được vào trong một mảng chứa các object
- Kiểm tra xem nếu kích thước mảng là 0.
- empty?
- Truy vấn CSDL với hàm COUNT các record có role là admin
- Kiểm tra xem nếu count đó bằng 0.
Như vậy, ta có thể thấy rằng, empty? sẽ hiệu quả hơn nhiều so với blank? đối với một tập dữ liệu lớn.
any? or exists?
any? và exists? đều return true khi mà có tồn tại bất cứ record nào thỏa mãn điều kiện, điều khác biệt giữa chúng là cách để đạt được điều đó.

Kết quả truy vấn ở trên cho ta thấy cách thứ hoạt động của chúng:
- any?
- Truy vấn CSDL tất cả users
- Load các users đó vào trong một mảng chứa các object
- Sử dụng Enumerable#any? để kiểm tra xem có object nào thỏa mãn điều kiện không
- exists?
- Truy vấn CSDL 1 record đầu tiên thỏa mãn điều kiện
- Kiểm tra xem có tồn tại record đó không
Như vậy, exists? hẳn là sẽ hiệu quả hơn any? đúng không nào
