Chỉ mục(index) trong cơ sở dữ liệu (Phần 3)
Ở bài viết trước chúng ta đã tìm hiểu về việc sử dụng chỉ mục với toán tử bằng cũng như tìm kiếm theo khoảng. Ở bài viết lần này, chúng ta sẽ tiếp tục tìm hiểu các vấn đề thường gặp của chỉ mục khi sử dụng mệnh đề WHERE. Tuy đây là những vấn đề rất thường xuyên gặp phải nhưng dường như việc xử lí ...
Ở bài viết trước chúng ta đã tìm hiểu về việc sử dụng chỉ mục với toán tử bằng cũng như tìm kiếm theo khoảng. Ở bài viết lần này, chúng ta sẽ tiếp tục tìm hiểu các vấn đề thường gặp của chỉ mục khi sử dụng mệnh đề WHERE. Tuy đây là những vấn đề rất thường xuyên gặp phải nhưng dường như việc xử lí chỉ mục như thế nào thì còn là một câu hỏi lớn. Mong rằng bài viết sẽ đem lại những cách xử lí thông minh cho các bạn khi sử dụng chỉ mục trong cơ sở dữ liệu
Chỉ mục một phần (partial index hay filtered index) có thể hiểu đơn giản là việc ta đánh chỉ mục trên một cột nào đó nhưng không phải toàn bộ, mà chỉ trên một phần của cột đó với một điều kiện xác định. Chỉ mục một phần thường được sử dụng khi trong mệnh đề WHERE có thêm một điều kiện hằng số nào đó. Ví dụ như trường hợp sau:
SELECT message FROM messages WHERE processed = 'N' AND receiver = ?;
Câu truy vấn này lấy ra tất cả các thông điệp chưa được xử lý cho một người nhận cụ thể. Những tin nhắn mà đã được xử lý thì hiếm khi được cần đến. Nếu được dùng đến thì chúng được truy xuất bởi những điều kiện cụ thể hơn như là khóa chính.
Chúng ta có thể tối ưu hóa câu truy vấn này bằng chỉ mục kết hợp trên hai cột. Chỉ mục này đáp ứng hoàn toàn yêu cầu, nhưng nó chứa nhiều hàng mà không bao giờ được tìm kiếm, cụ thể là những thông điệp mà đã được xử lý. Tuy nó vẫn chạy rất tốt nhưng sẽ làm lãng phí rất nhiều bộ nhớ để lưu trữ dữ liệu của cây chỉ mục.
Với chỉ mục một phần, bạn có thể giới hạn để chỉ mục chỉ bao gồm các thông điệp chưa được xử lý. Cú pháp của nó cực kỳ đơn giản:
CREATE INDEX message_todo ON messages (receiver) WHERE processed = 'N';
Chỉ mục này chỉ bao gồm những hàng mà thỏa mãn điều kiện WHERE. Trong trường hợp này chúng ta thậm chí còn loại bỏ được cột processed bởi vì nó luôn luôn là ‘N’. Có nghĩa là chỉ mục đã được giảm kích thước theo cả hai chiều: theo chiều dọc, vì nó chứa ít hàng hơn; theo chiều ngang, bởi vì cột được loại bỏ. Chỉ mục này tiết kiệm khá nhiều bộ nhớ khi dữ liệu xử lí lớn.
SQL tiêu chuẩn không định nghĩa NULL như là một giá trị mà thay vào đó là một sự thay thế cho những giá trị bị thiếu hoặc không biết. Do đó, không có giá trị nào có thể là NULL. Tuy nhiên, cơ sở dữ liệu Oracle lại coi một xâu rỗng là NULL. Rắc rối hơn, thậm chí có trường hợp cơ sở dữ liệu Oracle còn xử lý giá trị NULL như là một xâu rỗng.
Khái niệm NULL được sử dụng trong nhiều ngôn ngữ lập trình. Bạn có thể nhìn thấy ở bất kỳ đâu, một xâu rỗng không bao giờ là một giá trị NULL… ngoại trừ trong cơ sở dữ liệu Oracle. Nghĩa là, trong thực tế, bạn không thể nào lưu trữ một giá trị xâu rỗng trong một trường VARCHAR. Nếu bạn làm thế, cơ sở dữ liệu Oracle chỉ lưu trữ giá trị NULL. Điều kỳ dị này không chỉ lạ, mà nó còn nguy hiểm. Thêm vào đó, vấn đề giá trị NULL khác thường của cơ sở dữ liệu Oracle không dừng lại ở đây mà nó còn tiếp tục với việc đánh chỉ mục.
Cơ sở dữ liệu Oracle không thêm các hàng vào trong chỉ mục nếu mà các cột được sử dụng đánh chỉ mục đó đều nhận giá trị NULL. Điều đó có nghĩa là những chỉ mục đó đều là chỉ mục một phần. Ta sẽ xem xét ví dụ sau:
Giả sử ta chỉ đánh chỉ mục trên trường date_of_birth:
CREATE INDEX emp_dob ON employees(date_of_birth);
Tuy nhiên, khi thêm vào cơ sở dữ liệu một record không có trường date_of_birth:
INSERT INTO employees(subsidiary_id, employee_id, first_name, last_name, phone_number) VALUES (?, ?, ?, ?, ?);
Câu lệnh INSERT không xác định giá trị date_of_birth do đó giá trị mặc định là NULL – vì thế nó không được thêm vào trong chỉ mục emp_dob. Hậu quả là chỉ mục không thể hỗ trợ một câu truy vấn cho những bản ghi mà có điều kiện date_of_birth = NULL:
SELECT first_name, last_name FROM employees WHERE date_of_birth IS NULL;
Kết quả của câu truy vấn trên:
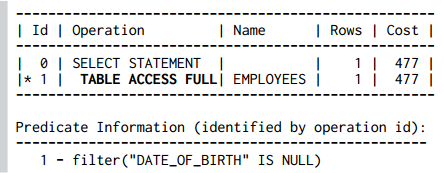
Để xử lí vấn đề này, chúng ta cần thiết kế một chỉ mục mà có ít nhất một cột có giá trị khác NULL :
CREATE INDEX demo_null ON employees (subsidiary_id, date_of_birth);
Hàng đã tạo bên trên sẽ được thêm vào chỉ mục bởi vì subsidiary_id là khác NULL. Chỉ mục này có thể hỗ trợ truy vấn tất cả các nhân viên có giá trị trường subsidiary_id cụ thể và không có giá trị date_of_birth:
SELECT first_name, last_name FROM employees WHERE subsidiary_id = ? AND date_of_birth IS NULL;
Và kết quả là:
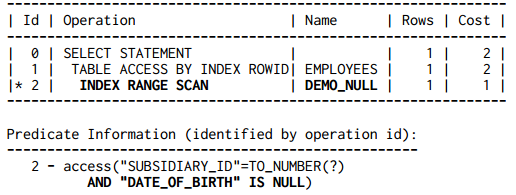
Chúng ta có thể mở rộng ý tưởng này cho câu truy vấn lúc đầu để tìm kiếm tất cả các bản ghi mà có điều kiện date_of_birth IS NULL. Trong đó, cột date_of_birth phải nằm ở vị trí trái nhất trong chỉ mục để có thể sử dụng như vị từ truy cập trong chỉ mục (access predicate). Mặc dù chúng ta không dùng cột chỉ mục thứ hai cho bản thân câu truy vấn, chúng ta thêm một cột khác đảm bảo rằng cột này không bao giờ nhận giá trị NULL, do đó chỉ mục chứa tất cả các bản ghi. Chúng ta có thể sử dụng bất kỳ cột nào có ràng buộc NOT NULL, như subsidiary_id, cho mục đích đó.
Một cách khác chúng ta có thể dùng một biểu thức hằng, cái mà không bao giờ NULL. Điều này đảm bảo rằng chỉ mục chứa tất cả các hàng mặc dù cột date_of_birth có thể NULL:
CREATE INDEX emp_dob ON employees(date_of_birth, '1');
Điều kiện bị mờ là những mệnh đề WHERE mà được trình bày theo một cách mà ngăn cản việc sử dụng chỉ mục đúng đắn. Phần này là một tập các anti-patterns mà mọi developer nên biết và tránh.
5.1. Các kiểu dữ liệu ngày
Thông thường, chúng ta sử dụng hàm TRUNC nhằm mục đích loại bỏ thành phần thời thời gian vì Oracle không có kiểu dữ liệu DATE tuần túy. Ví dụ, để tìm kiếm doanh số bán hàng ngày hôm qua, ta thực hiện truy vấn như sau:
SELECT * FROM sales WHERE TRUNC(sale_date) = TRUNC(sysdate - INTERVAL '1' DAY);
Với truy vấn trên, ta không thể sử dụng được chỉ mục được đánh trên cột sale_date bởi TRUNC(sale_date) là hoàn toàn khác với sale_date. Để giải quyết vấn đề này, ta chỉ cần đánh chỉ mục trên hàm TRUNC(sale_date):
CREATE INDEX index_name ON table_name(TRUNC(sale_date));
Điều này sẽ diễn ra tương tự với các hàm thời gian của các hệ quản trị cơ sở dữ liệu khác và chúng ta cũng sẽ xử lí tương tự.
Một trường hợp khác của kiểu dữ liệu ngày: Vấn đề xảy ra với cơ sở dữ liệu có kiểu DATE rõ ràng nếu bạn tìm kiếm cho một khoảng thời gian dài hơn như trong câu truy vấn MySQL dưới đây:
SELECT * FROM sales WHERE DATE_FORMAT(sale_date, "%Y-%M") = DATE_FORMAT(now(), "%Y-%M");
Câu truy vấn sử dụng một định dạng date chỉ bao gồm năm và tháng. Tuy nhiên, giải pháp ở trên không được áp dụng ở đây vì MySQL không có function-based index. Sử dụng một khoảng điều kiện như một giải pháp thay thế. Đây chính là một phương pháp chung để làm việc với tất cả cơ sở dữ liệu:
SELECT *
FROM sales
WHERE sale_date BETWEEN quarter_begin(?)
AND quater_end(?);
Và chúng ta chỉ cần sử dụng một chỉ mục trực tiếp trên cột sale_date để tối ưu hóa câu truy vấn này.
5.2. Kiểu chuỗi số
Chuối số là các số mà được lưu trữ trong các cột kiểu text. Mặc dù đó là một thói quen không tốt, nó chỉ không sử dụng chỉ mục nếu chúng ta không tiếp tục coi nó như string.
SELECT ... FROM ... WHERE numeric_string = '42';
Đương nhiên, câu lệnh này có thể sử dụng một chỉ mục trên numeric_string. Tuy nhiên, nếu bạn dùng một số để so sánh chúng, cơ sở dữ liệu không còn có thể sử dụng điều kiện này như một vị từ truy cập, tức là chỉ mục sẽ trở nên vô nghĩa:
SELECT ... FROM ... WHERE numeric_string = 42;
Mặc dù một số cơ sở dữ liệu gây ra lỗi (như PostgreSQL) nhiều cơ sở dữ liệu tự động thêm chuyển đổi kiểu dữ liểu ẩn.
SELECT ... FROM ... WHERE TO_NUMBER(numeric_string) = 42;
Tương tự như vấn đề trước. Một chỉ mục trên numeric_string không được sử dụng bởi lời gọi hàm. Giải pháp xử lí vấn đề này cũng giống như trước: chuyển đổi điều kiện tìm kiếm thay vì chuyển đổi giá trị của cột trong bảng.
SELECT ... FROM ... WHERE numeric_string = TO_CHAR(42);
Có lẽ bạn muốn hỏi tại sao cơ sở dữ liệu không làm điều này một cách tự động. Đó là bởi vì khi chuyển một string sang một number luôn trả về một kết quả rõ ràng. Điều này không đúng theo chiều ngược lại. Một số được định dạng như là text có thể chứa khoảng trắng, các dấu câu và nhiều chữ số 0 đứng đầu. Ví dụ như 42 khi biểu diễn thành chuỗi có thể viết thành nhiều định dạng khác nhau như "042", "0042", "00042",... Cơ sở dữ liệu không biết được định dạng số đã dùng trong cột numeric_string , vì thế nó có cách khác: cơ sở dữ liệu chuyển đổi string sang number – phép chuyển đổi này rất rõ ràng.
5.3. Biểu thức toán học
Việc sử dụng các biểu thức toán học cũng làm cản trở việc sử dụng chỉ mục. Ví dụ như trường hợp sau:
SELECT numeric_number FROM table_name WHERE numeric_number - 1000 > ?
Chỉ mục đánh trên cột numeric_number sẽ không được sử dụng. Hay như trường hợp sau:
SELECT a,b FROM table_name WHERE 3*a + 5 = b
Cách xử lí đơn giản đó là biến đổi biểu thức tương đương một cách thông minh và sử dụng chỉ mọc trên hàm đó
SELECT a,b FROM table_name WHERE 3*a -b = -5
CREAT INDEX math ON table_name(3*a-b)
- Ở bài viết này, chúng ta có thể thấy việc sử dụng chỉ mục một cách thông minh có thể đem lại hiệu quả không ngờ trong nhiều trường hợp khác nhau.
- Bài viết này là những phần kiến thức cuối cùng trong series mà mình muốn truyền đạt về chỉ mục trong cơ sở dữ liệu. Những bài viết của mình trong series chỉ mang tính chất chia sẻ kiến thức mà mình tìm hiểu được thông qua việc đọc cuốn sách SQL Performance Explained - Markus Winand. Còn rất nhiều kiến thức khác khá hay và hữu ích về chỉ mục trong cuốn này nên mọi người có thể tìm đọc.
