Loại bỏ dữ liệu trùng lặp với lệnh DISTINCT trong Oracle - Oracle căn bản
Trường hợp dữ liệu trả về bị trùng lặp thì bạn có thể sử dụng lệnh DISTINCT để loại bỏ dữ dữ liệu bị trùng, chỉ để lại một record duy nhất. Ví dụ bạn lấy danh sách sinh viên đã từng đăng ký tham dự cuộc thi viết phần mềm, nếu sinh viên A đã tham gia nhiều lần thì kế quả trả về sẽ bị trùng, mà ta chỉ ...
Trường hợp dữ liệu trả về bị trùng lặp thì bạn có thể sử dụng lệnh DISTINCT để loại bỏ dữ dữ liệu bị trùng, chỉ để lại một record duy nhất. Ví dụ bạn lấy danh sách sinh viên đã từng đăng ký tham dự cuộc thi viết phần mềm, nếu sinh viên A đã tham gia nhiều lần thì kế quả trả về sẽ bị trùng, mà ta chỉ cần một record là đủ nên sẽ dùng lệnh DISTINCT trong Oracle để loại bỏ.
1. Cú pháp lệnh DISTINCT trong Oracle
Lệnh này sẽ được đặt trước lệnh SELECT.
SELECT DISTINCT expressions FROM tables WHERE conditions;
Trong đó:
- expressions là danh sách các column bạn sẽ chọn
- tables là danh sách table cần truy vấn
- conditions là danh sách các điều kiện lọc dữ liệu
Đây là một ví dụ đơn giản:
SELECT DISTINCT id, name FROM students WHERE counter > 0;
2. Ví dụ khác về DISTINCT
Sau đây là một ví dụ khác sử dụng lệnh distinct trong Oracle.
Giả sử ta có một bảng như sau:
CREATE TABLE "CUSTOMERS"
( "NAME" VARCHAR2(4000),
"AGE" NUMBER,
"SALARY" NUMBER,
"STATE" VARCHAR2(4000)
) Và đây là danh sách dữ liệu.
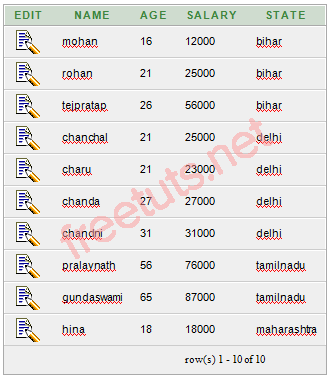
Bây giờ muốn muốn lấy danh sách state có trong bảng này và không được trùng thì sẽ dùng lệnh sau:
SELECT DISTINCT state FROM customers
Nếu không dùng DISTINCT thì sẽ trả về 10 records, nhưng nếu dùng DISTINCT thì chỉ tra về 4 records.
Lời kết
Như vậy là mình đã giới thiệu xong cách sử dụng của lệnh distinct trong Oracle, lệnh này rất hữu ích trong trường hợp muốn loại bỏ dữ liệu bị trùng lặp.
Có một lưu ý là nó chỉ loại bỏ dữ liệu khi tất cả các column trùng nhé, chỉ cần có một column khác thôi thì cũng không được xem là dữ liệu trung lặp.
