Machine Learning thật thú vị (Phần 2)
Trong phần 1, chúng ta đã đề cập đến việc Học Máy đã sử dụng các thuật toán di truyền để tìm ra những điều thú vị về dữ liệu bạn có mà không cần phải viết những dòng mã cụ thể để giải quyết bài toán của bạn. Trong phần này, chúng ta sẽ dành thời gian tìm hiểu một thuật toán di truyền làm được ...
Trong phần 1, chúng ta đã đề cập đến việc Học Máy đã sử dụng các thuật toán di truyền để tìm ra những điều thú vị về dữ liệu bạn có mà không cần phải viết những dòng mã cụ thể để giải quyết bài toán của bạn.
Trong phần này, chúng ta sẽ dành thời gian tìm hiểu một thuật toán di truyền làm được những điều rất thú vị - tạo nên một trò chơi thực sự giống như được tạo bởi con người. Chúng ta sẽ xây dựng một mạng noron, cung cấp cho nó một tập dữ liệu văn bản và chờ xem nó sẽ tạo nên một văn bản khác từ đó.
Tạo nên những dự đoán thông minh hơn
Trong phần 1, chúng ta đã tạo một thuật toán đơn giản để dự đoán giá trị của một ngôi nhà dựa trên các đặc điểm của nó. Ví dụ về một ngôi nhà với những thông tin sau:

Giống như phần 1, chúng ta viết một hàm lượng giá cơ bản sau:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * 0.123 # and a big pinch of that price += sqft * 0.41 # maybe a handful of this price += neighborhood * 0.57 return price
Chúng ta đã ước lượng giá trị của ngôi nhà dựa trên trọng số của các thuộc tính của ngôi nhà. Đồ thị sau sẽ biểu diễn chức năng này:
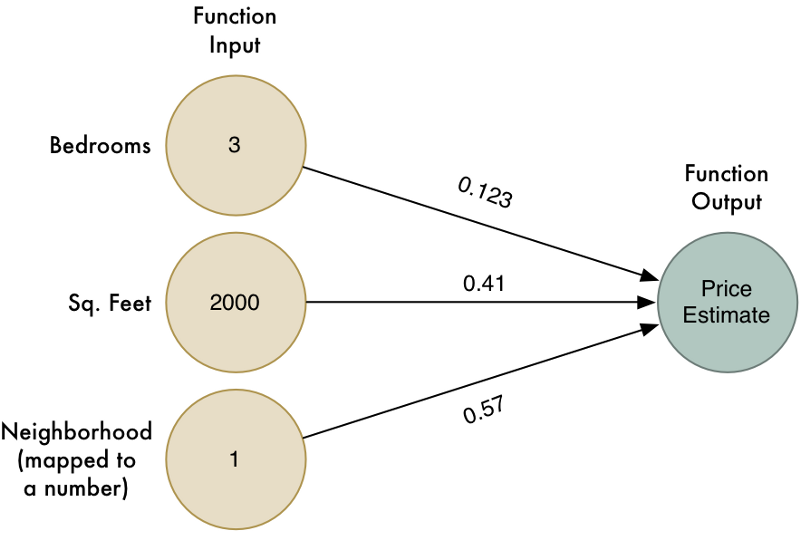
Tuy nhiên thuật toán này chỉ có thể hoạt động với những vấn đề đơn giản mà kết quả có mối quan hệ tuyến tính với dữ liệu đầu vào. Điều gì sẽ xảy ra nếu giá ngôi nhà thực sự không đơn giản như vậy. Ví dụ, khu vực lân cận có ảnh hưởng nhiều với những ngôi nhà có kích thước to hay nhà bé, nhưng lại không ảnh hưởng tới những ngôi nhà có kích thước trung bình. Làm thế nào chúng ta có thể nắm bắt được những loại chi tiết phức tạo trong mô hình của chúng ta.
Để rõ ràng hơn, chúng ta có thể chạy thuật toán này nhiều lần với những trọng số khác nhau:
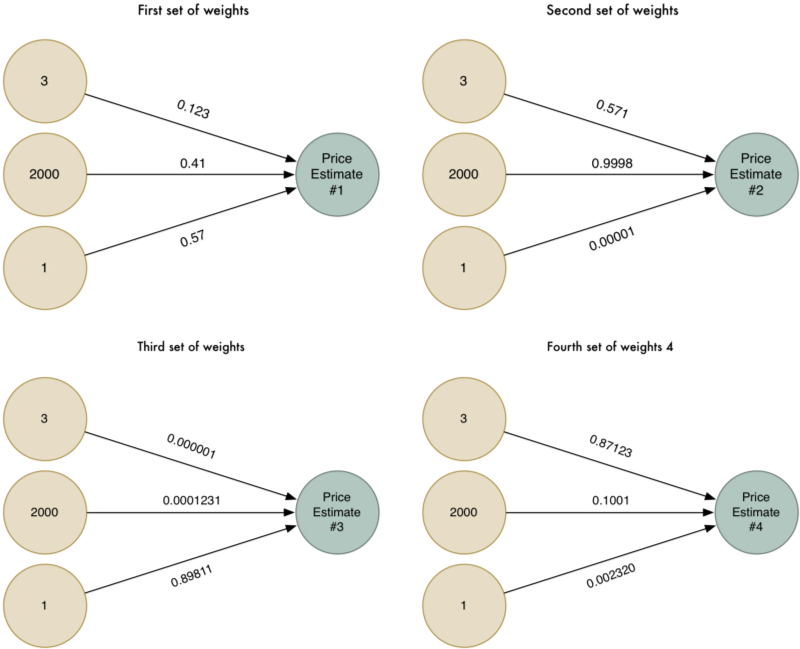
Giờ chúng ta có 4 giá trị ước lượng khác nhau. Hãy kết hợp 4 giá trị này vào thành kết quả cuối cùng.
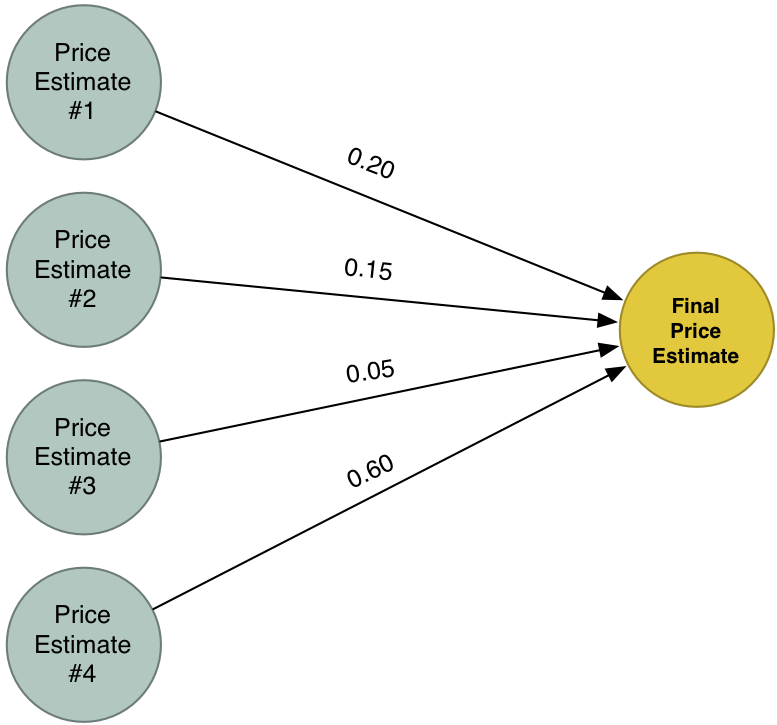
Bây giờ chúng ta đã có kết quả cuối cùng được kêt hợp từ 4 kết quả tạm thời khác nhau. (Tạm thời như vậy, chúng ta sẽ tìm hiểu sâu hơn cách làm này ở phần sau.)
Mạng thần kinh là gì?
Kết hợp 4 mô hình ước lượng trên thành một mô hình lớn như sau:
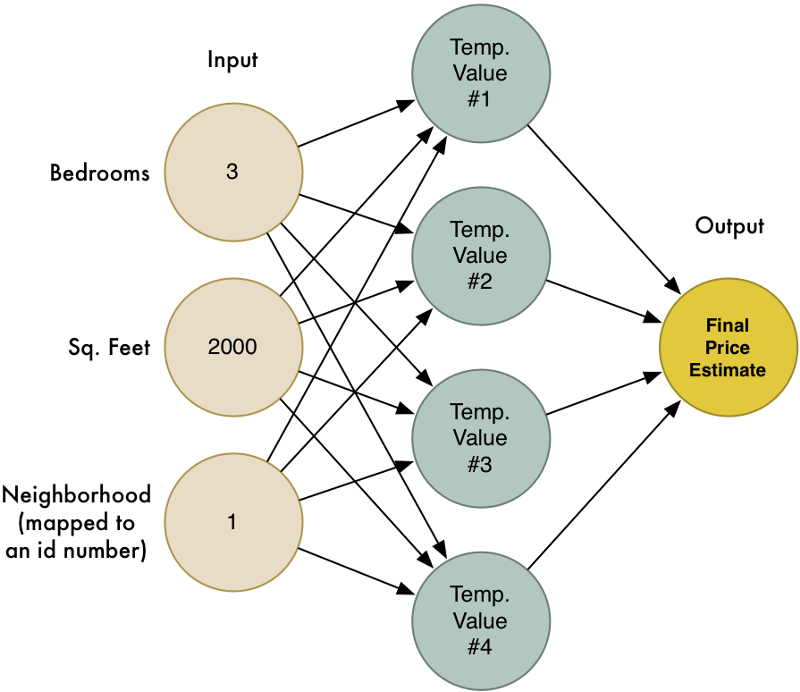
Đây chính là mạng thần kinh! Mỗi nút sẽ nhận các giá trị đầu vào, áp dụng trọng số cho chúng và tính toán được kết quả đầu ra. Bằng cách kết hợp rất nhiều nút với nhau, chúng ta có thể mô hình hóa các chức năng phức tạp.
Ý tưởng đơn giản trên có thể được diễn đạt lại theo cách sau:
- Chúng ta tạo nên những chức năng đơn giản, thực hiện tính toán với những trọng số khác nhau dựa trên các giá trị đầu vào. Những chức năng này được gọi là một tế bào thần kinh.
- Kết hợp nhiều tế bào thần kinh lại với nhau, chúng ta có thể mô hình hóa nhiều chức năng phức tạp.
Tư tưởng trên giống như bộ ghép hình LEGO. Nếu như có đủ những mảnh ghép cơ bản, bằng cách kết hợp chúng lại với nhau chúng ta có thể tạo nên rất nhiều mô hình phức tạp.
Cung cấp bộ nhớ cho mạng thần kinh (NN)
Mạng thần kinh trên luôn luôn trả về kết quả giống nhau với những tập dữ liệu đầu vào giống nhau. Nó không có bộ nhớ. Trong thuật ngữ lập trình, đó là một thuật toán phi trạng thái.
Trong nhiều trường hợp (giống như ước lượng giá trị ngôi nhà), đó chính xác là điều bạn mong muốn. Nhưng một việc mà loại mô hình này không thể làm là đáp ứng với các mô hình dữ liệu theo thời gian.
Tưởng tượng tôi đưa cho bạn một bàn phím và yêu cầu bạn viết một câu chuyện. Nhưng trước khi bạn bắt đầu, tôi sẽ dự đoán ký tự đầu tiên bạn sẽ gõ. Tôi nên đoán đó là chữ gì?
Tôi có thể sử dụng kiến thức về tiếng Anh của mình để nâng cao tỉ lệ đoán đúng của tôi. Ví dụ, bạn có thể sẽ gõ một ký tự phổ biến trước tiên. Nếu tôi đã xem qua những câu chuyện bạn viết trước đó, tôi có thể thu hẹp tập kết quả dự đoán hơn nữa dựa trên những từ bạn thường sử dụng vào đầu mỗi câu chuyện. Khi tôi đã có được tất cả những dữ liệu đó, tôi có thể xây dựng một mạng thần kinh để mô hình hóa khả năng bạn sẽ bắt đầu một lá thư với ký tự nào.
Mô hình của tôi có thể như sau:

Nhưng hãy làm vấn đề này khó khăn hơn. Làm sao để tôi có thể dự đoán ký tự tiếp theo bạn sẽ gõ tại bất kỳ thời điểm nào trong câu chuyện của bạn. Đây quả là một vấn đề thú vị hơn nhiều.
Lấy ví dụ về câu văn của Hemingway như sau:
Robert Cohn was once middleweight boxi
Ký tự nào sẽ xuất hiện tiếp theo?
Bạn có thể sẽ đoán chứ "n" - có vẻ như là chữ "boxing".
Để giải quyết vấn đề này với mạng thần kinh, chúng ta cần đặt thêm trạng thái vào mô hình của chúng ta. Mỗi lần sử dụng mạng thần kinh, chúng ta có thể lưu trữ kết quả tính toán và tái sử dụng chúng vào những lần tiếp theo như là một dữ liệu đầu vào. Bằng cách đó, mô hình của chúng ta sẽ điều chỉnh dự đoán dựa trên những đầu vào gần đây.
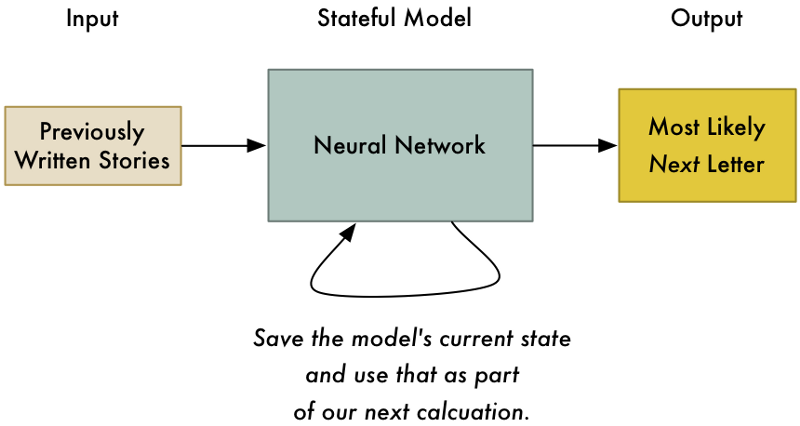
Việc đặt thêm trạng thái vào trong mô hình của chúng ta không chỉ giúp dự đoán chữ cái đầu tiên khả thi nhất trong câu chuyện, mà còn có khả năng dự đoán chữ cái có khả năng xuất hiện tiếp theo dựa trên tất cả các chữ cái đã xuất hiện trước đó.
Đây là ý tưởng cơ bản về Recurrent Neural Network (tạm dịch là mạng thần kinh tái phát). Chúng ta ddang cập nhật mạng mỗi khi chúng ta sử dụng nó. Điều này cho phép nó cập nhật các dự đoán của nó dựa trên những gì nó bắt gặp trong thời gian gần đây. Nó thậm chí có thể mô hình hóa các khuôn mẫu theo thời gian miễn là chúng ta cung cấp cho nó đủ bộ nhớ.
Một ký tự đơn có vai trò gì?
Việc dự đoán ký tự tiếp theo trong một câu chuyện dài có vẻ như khá ít ứng dụng. Nhưng vấn đề ở đây là gì? Một ứng dụng khá thú vị là bàn phím điện thoại tự động dự đoán ký tự sẽ được gõ.
Nhưng nếu chúng ta đẩy ý tưởng này tới cực độ? Nếu chúng ta yêu cầu mô hình dự đoán các ký tự tiếp theo và tiếp theo nữa thì sẽ thu được điều gì? Chúng ta sẽ mong muốn yêu cầu mô hình đó viết nên một câu chuyện hoàn chỉnh cho chúng ta!
Tạo ra một câu chuyện
Trước đó chúng ta đã bắt đầu với việc dự đoán một ký tự tiếp theo trong một câu văn của Hemingway. Bây giờ hãy thử sức để tạo nên một câu chuyện hoàn chỉnh theo phong cách Hemingway.
Để làm được điều này, chúng ta sẽ sử dụng Recurrent Neural Network implementation được viết bởi Andrej Karpathy - một nhà nghiên cứu về Deep-Learning ở Stanford.
Chúng ta sẽ tạo nên một mô hình từ một văn bản hoàn thiện "The Sun Also Rise" - 362.239 ký tự sử dụng 84 chữ cái duy nhất (bao gồm cả dấu chấm câu, chữ hoa, chữ thường, ...). Tập dữ liệu này thực sự hỏ bé khi so sánh với các dứng dụng thực tế điển hình. Để tạo ra một mô hình thực sự tốt về phong cách của Hemingway, sẽ tốt hơn nếu chúng ta có lượng dữ liệu gấp vài lần như trên. Nhưng từng đó cũng khá tốt cho ví dụ chúng ta đang tiến hành.
Trước hết, chúng ta chỉ cần bắt đầu huấn luyện RNN, nó không phải rất tốt ở khía cạnh dự đoán các chữ cái. Dưới đây là những gì nó tạo ra sau 100 vòng huấn luyện.
hjCTCnhoofeoxelif edElobe negnk e iohehasenoldndAmdaI ayio pe e h’e
btentmuhgehi bcgdltt. gey heho grpiahe.
Ddelnss.eelaishaner” cot AAfhB ht ltny
ehbih a”on bhnte ectrsnae abeahngy
amo k ns aeo?cdse nh a taei.rairrhelardr er deffijha
Bạn có thể thấy nó đã bắt đầu hình thành các từ được ngăn cách bởi các khoảng trống.
Sau 1000 vòng lặp huấn luyện, kết quả thu được đã hứa hẹn hơn nhiều:
hing soor ither. And the caraos, and the crowebel for figttier and ale the room of me? Streat was not to him Bill-stook of the momansbed mig out ust on the bull, out here. I been soms
inick stalling that aid.
“Hon’t me and acrained on .Hw’s don’t you for the roed,” In’s pair.”
“Alough marith him.”
Mô hình đã bắt đầu xác định được các khuôn mẫu của một cấu trúc câu cơ bản. Các dấu chấm câu đã được tạo ra, thậm chí cả những trích dẫn. Tuy nhiên vẫn còn nhiều từ còn chưa có nghĩa.
Tiếp tục với nhiều nghìn lần huấn luyện lặp lại, kết quả thu được thực sự rất tốt:
He went over to the gate of the café. It was like a country bed.
“Do you know it’s been me.”
“Damned us,” Bill said.
“I was dangerous,” I said. “You were she did it and think I would a fine cape you,” I said.
“I can’t look strange in the cab.”
“You know I was this is though,” Brett said.
“It’s a fights no matter?”
“It makes to do it.”
“You make it?”
“Sit down,” I said. “I wish I wasn’t do a little with the man.”
“You found it.”
“I don’t know.”
“You see, I’m sorry of chatches,” Bill said. “You think it’s a friend off back and make you really drunk.”
Thử so sánh với một đoạn văn thực tế trong cuốn sách
There were a few people inside at the bar, and outside, alone, sat Harvey Stone. He had a pile of saucers in front of him, and he needed a shave.
“Sit down,” said Harvey, “I’ve been looking for you.”
“What’s the matter?”
“Nothing. Just looking for you.”
“Been out to the races?”
“No. Not since Sunday.”
“What do you hear from the States?”
“Nothing. Absolutely nothing.”
“What’s the matter?”
Chúng ta đã không tạo nên một văn bản hoàn thiện từ đầu. Chúng ta có thể cung cấp cho thuật toán một vài chữ cái đầu tiên và để chúng tự hoàn thiện phần tiếp theo.
Một ví dụ cho vui, bằng cách tương tự chúng ta có thể tạo nên một cuốn sách được biết bởi thuật toán dựa trên cuốn sách dùng để huấn luyện thuật toán này bằng cách cung cấp các ký tự ban đầu là: "Er", "He" và "The S":

Kết quả không tồi phải không!
