Scraping và crawling Web với Scrapy và SQLAlchemy
Trong bài viết này, tôi sẽ giới thiệu cách xây dựng một công cụ scraping và crawling Web. Dữ liệu sẽ được thu về từ Stack Overflow và chúng ta sẽ trích xuất những câu hỏi mới nhất (Tiêu đề và URL). Dữ liệu thu được sẽ được lưu vào cơ sở dữ liệu. Tôi viết bài này với mục đích lớn nhất là học ...

Trong bài viết này, tôi sẽ giới thiệu cách xây dựng một công cụ scraping và crawling Web. Dữ liệu sẽ được thu về từ Stack Overflow và chúng ta sẽ trích xuất những câu hỏi mới nhất (Tiêu đề và URL). Dữ liệu thu được sẽ được lưu vào cơ sở dữ liệu.
Tôi viết bài này với mục đích lớn nhất là học hỏi một cách scrape và crawl Web bằng một thư viện của Python là Scrapy. Có thể Stack Overflow có API để làm những việc này, nhưng ở đây, nó không quan trọng. Khi làm việc thực tế thì bạn có thể chọn cách nào dễ dàng nhất cho mình. Còn trong bài viết này, chỉ đơn giản là học hỏi Scrapy mà thôi.
Chúng ta cần cài đặt Scrapy (v1.0.3) để scrape và SQLAlchemy (v1.0.9) để lưu dữ liệu thu được vào cơ sở dữ liệu. Bạn cũng cần cài đặt máy chủ cơ sở dữ liệu trên máy tính của mình hoặc bạn có thể kết nối đến máy chủ từ xa thì càng tốt. Trong bài viết này, tôi sẽ không đi vào chi tiết việc cài đặt này. Tôi sẽ sử dụng SQLite, một hệ cơ sở dữ liệu khá đơn giản.
Vào thời điểm bài viết này, Scrapy chưa hỗ trợ Python 3 nên chúng ta chỉ có thể làm việc với Python 2 mà thôi.
Cài đặt Scrapy
Nếu sử dụng hệ điều hành họ Unix thì việc cài đặt rất dễ dàng, bạn có thể cài Scrapy bằng bất cứ trình quản lý package của Python nào. Ví dụ tôi sử dụng pip, tôi cài đặt với lệnh sau. Bạn cũng có thể cấu hình và sử dụng môi trường ảo của Python để cài đặt các package làm việc trên đó.
$ pip install Scrapy
Khi đã cài đặt Scrapy xong rồi thì bạn có thể kiểm tra lại bằng lệnh sau trong shell của Python:
>>> import scrapy >>>
Nếu không có lỗi gì thì tức là chúng ta đã cài đặt Scrapy thành công.
SQLAlchemy
Tiếp theo là cài đặt SQLAlchemy, ví dụ với pip bằng lệnh sau:
$ pip install SQLAlchemy
Sau khi cài đặt Scrapy và SQLAlchemy là chúng ta đã sẵn sàng để xây dựng một chương trình scraping và crawling Web.
Khởi tạo một project với Scrapy bằng lệnh sau:
$ scrapy startproject stack
2015-12-10 14:43:54 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-12-10 14:43:54 [scrapy] INFO: Optional features available: ssl, http11
2015-12-10 14:43:54 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/home/naa/Works/python/crawl/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Lệnh này sẽ khởi tạo một project mới với đầy đủ các file cần thiết có cấu trúc như dưới đây.
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Đặc tả dữ liệu
File items.py được sử dụng để khai báo metadata cho những dữ liệu mà chúng ta muốn scrape. Trong file này có class StackItem là class được kế thừa từ class Item của Scrapy. Trong class này đã định nghĩa trước một số đối tượng mà Scrapy cần dùng để scrape.
import scrapy class StackItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass
Bây giờ, chúng ta sẽ thêm vào những dữ liệu mà chúng ta cần. Ví dụ, chúng ta cần tiêu đề và URL của các câu hỏi trên Stack Overflow, chúng ta sẽ định nghĩa trong file items.py như sau:
import scrapy class StackItem(scrapy.Item): title = scrapy.Field() url = scrapy.Field()
Tạo một Spider
Tạo một file tên là stack_spider.py trong thư mục spiders đã được tạo ở trên. Thư mục này khá đặc biệt, bởi nó là nơi chúng ta đưa ra các chỉ định cho Scrapy biết chính xác chúng ta muốn thu thập dữ liệu gì. Trong thư mục này, bạn có thể định nghĩa các Spider khác nhau cho các trang Web khác nhau.
Bắt đầu bằng một class kế thừa từ class Spider của Scrapy và chúng ta sẽ thêm vào các thuộc tính cần thiết.
from scrapy import Spider class StackSpider(Spider): name = "stack" allowed_domains = ["stackoverflow.com"] start_urls = [ "http://stackoverflow.com/questions?pagesize=50&sort=newest", ]
Những thuộc tính ở đây khá dễ hiểu, chúng thể hiện ý nghĩa qua chính tên của mình. Nếu cần thêm thông tin, bạn có thể tham khảo ở đây:
- name định nghĩa tên của Spider.
- allowed_domains chứa URL gốc của trang Web bạn muốn scrape.
- start_urls là danh sách các URL để Spider bắt đầu quá trình scraping. Tất cả mọi dữ liệu sẽ được Spider download từ các URL ở trong start_urls này.
XPath selector
Một điều rất quan trọng, đó là Scrapy sử dụng XPath selector để trích xuất dữ liệu từ các trang Web. Nói một cách khác, đó là chúng ta có thể chọn lọc ra một thành phần chính xác trên một trang Web bằng cách sử dụng XPath.
XPath is a language for selecting nodes in XML documents, which can also be used with HTML.
- Scrapy’s documentation -
XPath khá là khó hiểu, nhưng rất may, trình duyệt Chrome với Developer Tools có hỗ trợ chúng ta làm việc với XPath. Chúng ta chỉ cần inspect một đối tượng trên trang Web, sau đó copy XPath của nó và chỉnh sửa nếu muốn.
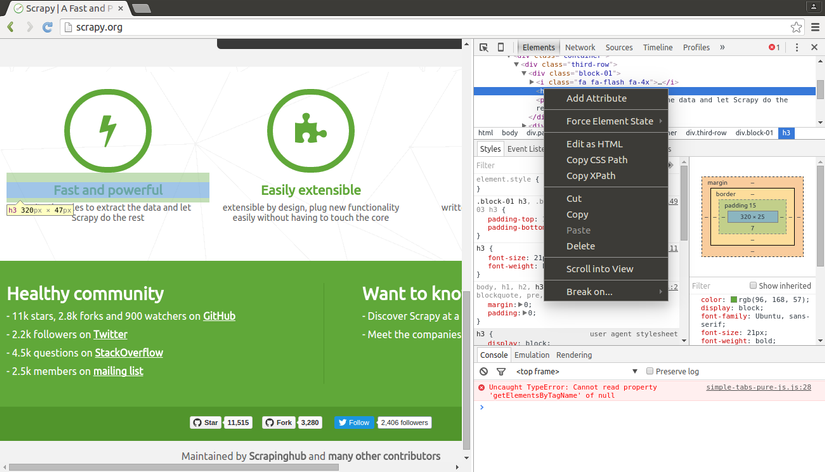
Developer Tools của Chrome cũng cho phép chúng ta test thử XPath trên console của Javascript, bằng cách sử dụng cú pháp $x, ví dụ như $x("//img"):
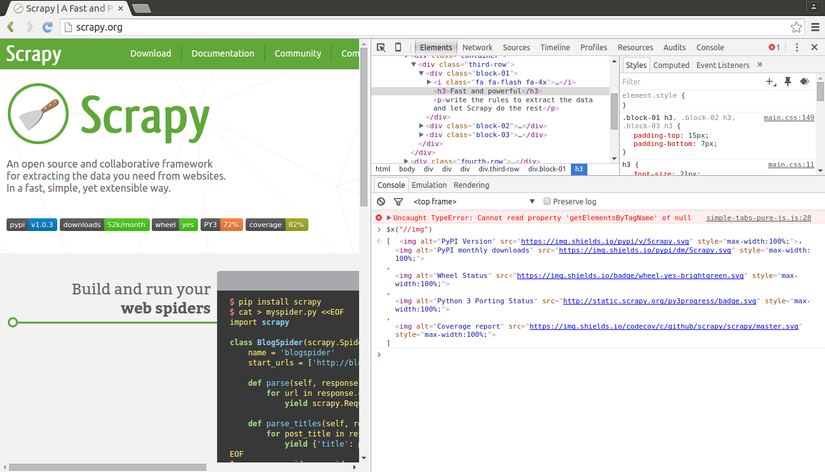
Bây giờ, chúng ta cần khai báo XPath của đối tượng mà chúng ta muốn trích xuất thông tin. Việc này cũng không khó lắm. Dùng Chrome vào Stack Overflow và chúng ta sẽ tìm XPath của chúng.
Click phải chuột vào câu hỏi đầu tiên và chọn "Inspect Element"
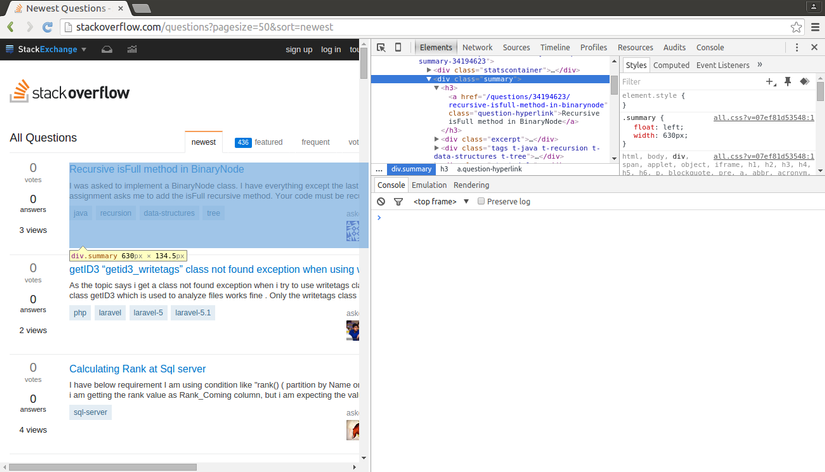
Bây giờ, chúng ta lấy XPath của phần tử đầu tiên <div class="summary">, kết quả sẽ tương tự //*[@id="question-summary-34194623"]/div[2]. Chúng ta sẽ test trong Javascript console.
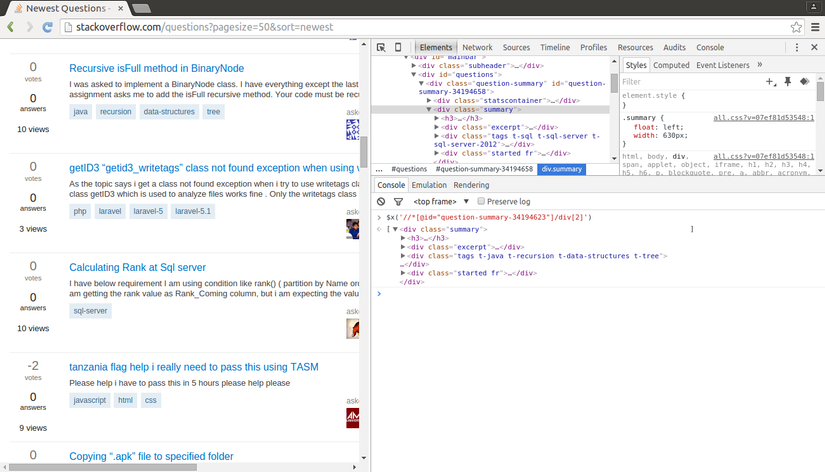
XPath lấy ra bằng cách trên chỉ lấy ra được 1 câu hỏi mà thôi. Cái chúng ta cần là lấy ra tất cả các câu hỏi. Điều này cũng rất đơn giản, chúng ta không sử dụng id mà sẽ sử dụng class cho XPath trên. Và XPath để lấy ra các câu hỏi sẽ là //div[@class="summary"]/h3. XPath này khá dễ hiểu, nó sẽ lấy ra tất cả các thành phần <h3> là con của một <div> có class là summary. Bạn có thể test lại XPath này trên Chrome.
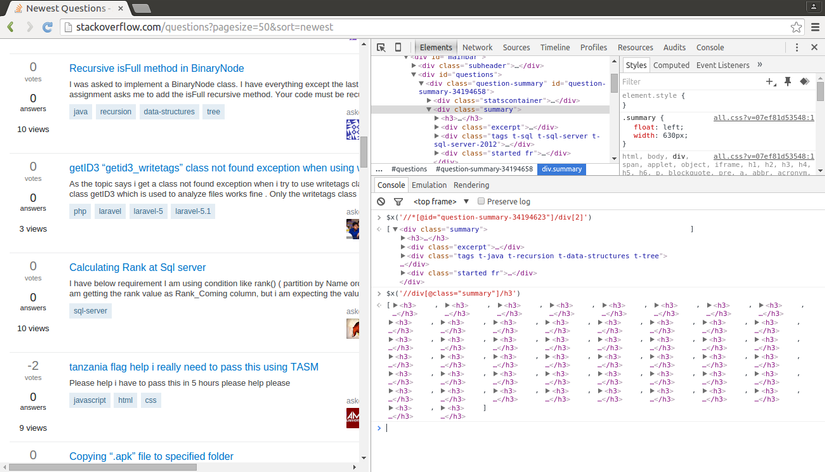
Chúng ta không sử dụng XPath copy từ Chrome bởi chúng chỉ lấy được 1 câu hỏi mà thôi. Trong phần lớn các trường hợp, chúng ta phải tự tìm 1 XPath phù hợp với mục địch của bạn. Tuy nhiên, nên dùng Chrome vì nó cho chúng ta giá trị ban đầu, từ đó chúng ta thay đổi thì dễ dàng hơn, trừ khi bạn là một pro có thể tự viết XPath cho mình.
Bây giờ, chúng ta sẽ chỉnh sửa stack_spider.py để thêm vào XPath mà chúng ta muốn.
from scrapy import Spider from scrapy.selector import Selector class StackSpider(Spider): name = "stack" allowed_domains = ["stackoverflow.com"] start_urls = [ "http://stackoverflow.com/questions?pagesize=50&sort=newest", ] def parse(self, response): questions = Selector(response).xpath('//div[@class="summary"]/h3')
Trích xuất dữ liệu
Chúng ta vẫn cần phân tích và scrape các dữ liệu mà chúng ta muốn. Tất cả chúng đều ở trong <div class="summary"><h3> và nhiệm vụ của chúng ta là lấy chúng ra. Bạn có thể update file stack_spider.py như sau:
from scrapy import Spider from scrapy.selector import Selector from stack.items import StackItem class StackSpider(Spider): name = "stack" allowed_domains = ["stackoverflow.com"] start_urls = [ "http://stackoverflow.com/questions?pagesize=50&sort=newest", ] def parse(self, response): questions = Selector(response).xpath('//div[@class="summary"]/h3') for question in questions: item = StackItem() item['title'] = question.xpath( 'a[@class="question-hyperlink"]/text()').extract()[0] item['url'] = question.xpath( 'a[@class="question-hyperlink"]/@href').extract()[0] yield item
Với đoạn code trên, chúng ta sẽ duyệt qua lần lượt các câu hỏi, và gán các giá trị title và url cho các item từ dữ liệu thu thập được. Bạn hãy chắc chắc các XPath ở trên là đúng bằng cách test thử với Developer Tools của Chrome. Các XPath cần test là $x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()') và $x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href').
Test
Sau khi xây dựng được công cụ scrape trên, chúng ta cần test nó. Việc test rất đơn giản, chúng ta chỉ cần chạy lệnh sau ở trong thư mục stack:
$ scrapy crawl stack
Sau khi chạy lệnh trên, trên console sẽ hiển thị 50 câu hỏi với tiêu đề và URL của chúng. Bạn có thể ghi kết quả vào 1 file JSON với lệnh sau:
$ scrapy crawl stack -o items.json -t json
Lệnh trên sẽ xuất kết quả ra 1 file items.json.
Trên đây, chúng ta đã xây dựng công cụ scrape. Bây giờ, chúng ta cần lưu những dữ liệu thu được vào cơ sở dữ liệu với SQLAlchemy.
Lưu dữ liệu vào cơ sở dữ liệu với SQLAlchemy
Mỗi lần thu thập được dữ liệu, chúng ta sẽ kiểm tra chúng và sau đó thêm chúng vào cơ sở dữ liệu.
Trước hết, chúng ta cần khởi tạo một cơ sở dữ liệu để lưu trữ. Mở file settings.py và định nghĩa pipeline để lưu trữ như sau:
ITEM_PIPELINES = ['stack.pipelines.StackPipeline', ]
Quản lý pipeline
Chúng ta đã xây dựng Spider để scrape và phân tích dữ liệu HTML. Bây giờ, chúng ta cần thiết lập cơ sở dữ liệu và kết nối chúng với nhau thông qua pipeline. Tất cả chúng được định nghĩa trong pipelines.py.
Kết nối đến cơ sở dữ liệu
Chúng ta sẽ sử dụng SQLAlchemy để kết nối với cơ sở dữ liệu. Tôi sẽ sử dụng SQLite, tuy nghiên, SQLAlchemy hỗ trợ chúng ta kết nối đến rất nhiều cơ sở dữ liệu khác nhau như MySQL, PostgreSQL, v.v... bạn có thể dùng bất cứ hệ cơ sở dữ liệu nào mình muốn.
Tôi đã từng giới thiệu cách sử dụng SQLAlchemy làm ORM cho CherryPy. Tuy nhiên, lần này, chúng ta không sử dụng SQLAlchemy làm ORM nữa mà sẽ sử dụng SQLAlchemy Core.
from sqlalchemy import create_engine, Table, Column, MetaData, Integer, Text from scrapy.exceptions import DropItem class StackPipeline(object): def __init__(self): _engine = create_engine("sqlite:///data.db") _connection = _engine.connect() _metadata = MetaData() _stack_items = Table("questions", _metadata, Column("id", Integer, primary_key=True), Column("url", Text), Column("title", Text)) _metadata.create_all(_engine) self.connection = _connection self.stack_items = _stack_items
Ở code trên, chúng ta tạo ra class StackPipeline và ở đó, chúng ta khởi tạo các đối tượng cần thiết và kết nối với cơ sở dữ liệu.
Xử lý dữ liệu
Tiếp theo, chúng ta cần định nghĩa một phương thức để xử lý các dữ liệu thu về.
from sqlalchemy import create_engine, Table, Column, MetaData, Integer, Text from scrapy.exceptions import DropItem class StackPipeline(object): def __init__(self): _engine = create_engine("sqlite:///data.db") _connection = _engine.connect() _metadata = MetaData() _stack_items = Table("questions", _metadata, Column("id", Integer, primary_key=True), Column("url", Text), Column("title", Text)) _metadata.create_all(_engine) self.connection = _connection self.stack_items = _stack_items def process_item(self, item, spider): is_valid = True for data in item: if not data: is_valid = False raise DropItem("Missing %s!" % data) if is_valid: ins_query = self.stack_items.insert().values( url=item["url"], title=item["title"]) self.connection.execute(ins_query) return item
Ở đoạn code trên, phương thức này làm nhiệm vụ trích xuất dữ liệu, kết nối với cơ sở dữ liệu và ghi kết quả vào đó.
Vậy là toàn bộ công cụ scrape và lưu dữ liệu đã hoàn thành, bây giờ chúng ta sẽ test thêm một lần nữa.
$ scrapy crawl stack
Và kết quả là, chúng ta đã scrape và lưu kết quả thành công.
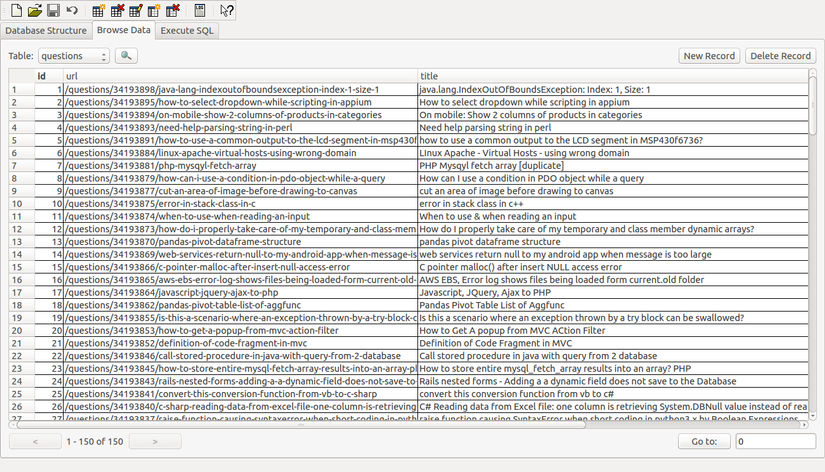
Trên đây là một ví dụ rất đơn giản. Chúng ta có thể dễ dàng scrape và crawl các trang Web bằng việc sử dụng Scrapy. Bạn có thể tự cài đặt và vận hành công cụ này, bởi nó cũng không quá khó. Bạn có thể tham khảo ví dụ của tôi trên Github nếu thầy cần thiết.
Bài viết gốc: https://manhhomienbienthuy.bitbucket.io/2015/Dec/11/web-scraping-and-crawling-with-scrapy-and-sqlalchemy.html (đã xin phép tác giả
