Crawl dữ liệu website bằng NodeJS cơ bản - NodeJS căn bản
Hướng dẫn cách crawl dữ liệu của một website sử dụng Node.js, sử dụng một vài package hỗ trợ, tùy thuộc vào độ phức tạp của dữ liệu của trang web mà có những cách để crawl khác nhau. Crawl là một kĩ thuật dùng để lấy dữ liệu từ một website bằng cách bóc tách dữ liệu từ một website nào đó, đây là ...
Hướng dẫn cách crawl dữ liệu của một website sử dụng Node.js, sử dụng một vài package hỗ trợ, tùy thuộc vào độ phức tạp của dữ liệu của trang web mà có những cách để crawl khác nhau.
Crawl là một kĩ thuật dùng để lấy dữ liệu từ một website bằng cách bóc tách dữ liệu từ một website nào đó, đây là một kĩ thuật được sử dụng rất nhiều, điển hình là Google bot. Kỹ thuật crawl được sử dụng rộng rãi nhằm mục đích lấy dữ liệu từ các trang web khi không được cung cấp 1 API cho phép lấy dữ liệu trực tiếp.
1. Cần hiểu trước khi Crawl website bằng NodeJS
Có thể nói rằng crawl ( "cào" ![]() ) dữ liệu của 1 website là một kỹ thuật cho phép thu thập các dữ liệu có trên website. Công cụ crawl sẽ truy cập vào đường dẫn cần lấy dữ liệu, sau đó tiến hành bóc tách để lấy dữ liệu về.
) dữ liệu của 1 website là một kỹ thuật cho phép thu thập các dữ liệu có trên website. Công cụ crawl sẽ truy cập vào đường dẫn cần lấy dữ liệu, sau đó tiến hành bóc tách để lấy dữ liệu về.
Dữ liệu crawl được từ một website được sử dụng với nhiều mục đích. Có thể là tổng hợp tin tức từ những trang báo mạng để tạo ra 1 trang báo đầy đủ, hay lấy thời khóa biểu từ trang đăng ký học của nhà trường,...Nhưng về luật thì điều này là không được phép, chúng ta cần phải xin phép chủ website.
Có rất nhiều cách để crawl dữ liệu từ một website bằng NodeJS, tùy vào mức độ phức tạp của dữ liệu mà chúng ta sẽ có những cách khác nhau.
Hiện nay ứng dụng web được xây dựng theo 2 loại chính đó là SPA (single page application) và MPA( multiple page application), với mỗi loại sẽ có những cách crawl khác nhau.
Điển hình là Zaidap.com được xây dựng theo kiểu truyền thống đó là MPA, khi bạn view-source thì chúng ta sẽ thấy tất cả dữ liệu ở trong source.
Còn Zingmp3 thì xây dựng theo kiểu SPA, khi view-source ra thì toàn thấy các đọan mã script. Các trang SPA thì việc crawl đơn giản hơn rất nhiều vì họ sẽ nhận dữ liệu từ API, chúng ta chỉ cần gọi API là có thể lấy dữ liệu. MPA sẽ khó hơn bởi dữ liệu ở dạng HTML nên việc bọc tách sẽ khó hơn, không những thế có những trang web dữ liệu cần lấy khá phức tạp.
2. Crawl dữ liệu website bằng NodeJS
Bài viết này sẽ thực hiện crawl đối với những trang "truyền thống" và điển trong ví dụ này là lấy tên và link của một tutorial trên trang Zaidap.com.net. Trước tiên, chúng ta cần chuẩn bị một vài công cụ hỗ trợ.
Cài đặt công cụ hỗ trợ
Khi thực hiên crawl bằng NodeJS chúng ta cần phải cài đặt một số công cụ, vì trang mình muốn crawl là một trang MPA và dữ liệu cần bóc tách khá đơn giản nên chỉ cần một vài package như:
cheerio- hỗ trợ parse DOM giống như là jQuery, nó rất nhẹ và khá quen thuộc. Xem tài liệu về cheerio ở trang chủ.request-promise- hợ trợ việc lấy mã nguồn của trang cần cào, thư viện này được xây dựng dựa trên thư viện request và hỗ trợ promise.fs- thư viện hỗ trợ làm việc với file trong Node.js
Để cài đặt chúng ta chỉ cần mở terminal và gõ dòng lệnh:
npm i cheerio request-promise
Sau khi cài đặt hoàn tất, chúng ta sẽ đi vào phân tích sâu hơn trang web cần bóc tách dữ liệu.
Vì đây là một trang với dữ liệu không quá phức tạp và dữ liệu không thay đổi theo thời gian thực nên mình sử dụng request-promise và cheerio, nhưng đối với những web phức tạp thì người ta sẽ dùng puppeteer. Bạn có thể tìm hiểu thêm về nó nhé ! Pupperteer khá mạnh trong khoản crawl này nhưng cũng khá nặng vì nó "vác" luôn hẳn cái trình duyệt vào
Phân tích website cần crawl
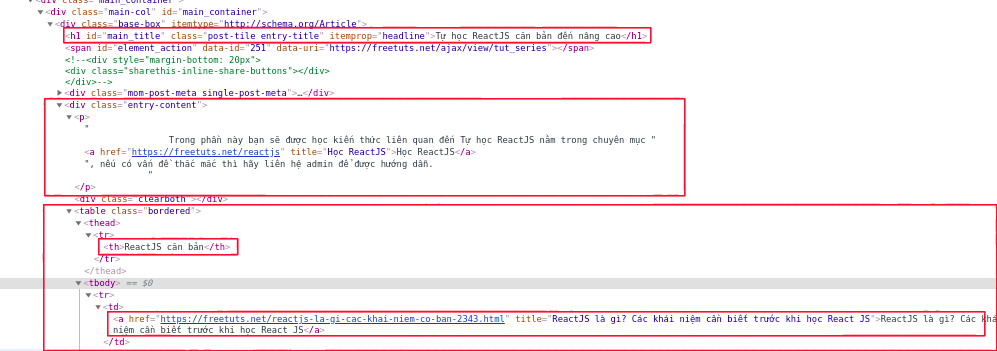
Chúng ta sẽ thực hiện crawl ở các bài viết ở phần ReactJS căn bản, với những dữ liệu cần thu thập là tên, miêu tả của tutorial và các bài viết trong mỗi chương đó. Sau khi phân tích thì sẽ thấy được vị trí của dữ liệu chúng ta cần lấy:
- Tên tutorial: nằm trong thẻ
h1có id làmain_title. - Miêu tả của tutorial: nằm trong class
entry-contentvới thẻp. - Các chương của bài viết sẽ nằm trong một table, với tên chương là
table -> theadvà các bài viết nằm trong thẻtable -> tbody.
Tiến hành crawl dữ liệu
Sau khi cài đặt các package và phân tích các thành phần chúng ta sẽ tiến hành crawl dữ liệu. Mình sẽ làm việc với file index.js. Trước tiên, chúng ta cần import các module cần thiết.
//file: index.js
const rp = require("request-promise");
const cheerio = require("cheerio");
const fs = require("fs");
const URL = `https://Zaidap.com.net/reactjs/tu-hoc-reactjs`;
const options = {
uri: URL,
transform: function (body) {
//Khi lấy dữ liệu từ trang thành công nó sẽ tự động parse DOM
return cheerio.load(body);
},
};
(async function crawler() {
try {
// Lấy dữ liệu từ trang crawl đã được parseDOM
var $ = await rp(options);
} catch (error) {
return error;
}
/* Lấy tên và miêu tả của tutorial*/
const title = $("#main_title").text().trim();
const description = $(".entry-content > p").text().trim();
/* Phân tích các table và sau đó lấy các posts.
Mỗi table là một chương
*/
const tableContent = $(".entry-content table");
let data = [];
for (let i = 0; i < tableContent.length; i++) {
let chaper = $(tableContent[i]);
// Tên của chương đó.
let chaperTitle = chaper.find("thead").text().trim();
//Tìm bài viết ở mỗi chương
let chaperData = []
const chaperLink = chaper.find("tbody").find("a");
for (let j = 0; j < chaperLink.length; j++) {
const post = $(chaperLink[j]);
const postLink = post.attr("href");
const postTitle = post.text().trim();
chaperData.push({
postTitle,
postLink,
});
}
data.push({
chaperTitle,
chaperData,
});
}
// Lưu dữ liệu về máy
fs.writeFileSync('data.json', JSON.stringify(data))
})();Như đã phân tích ở trên thì mỗi table sẽ là một chương, bởi vậy chúng ta sẽ dùng cheerio để tìm và phân tích. Sau khi phân tích thành công chúng ta sẽ lưu về dưới dạng JSON. Để chạy dự án sử dụng câu lệnh:
node index
Và đây là kết quả nhận được sau khi crawl thành công:
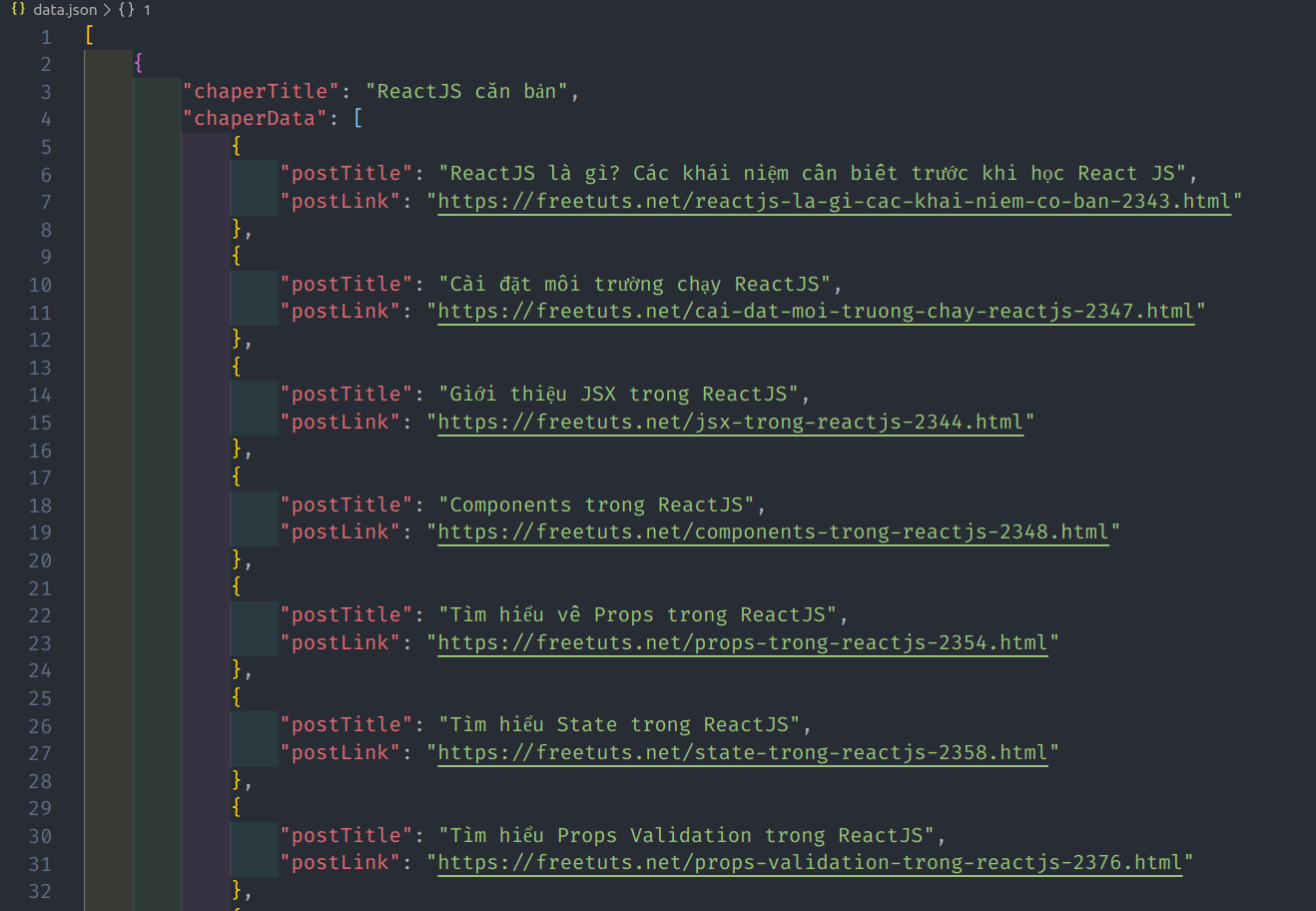
Trên đây là những kiến thức cơ bản về crawl dữ liệu website bằng NodeJS. Mong bài viết này có thể giúp ích cho bạn cho việc lập trình với NodeJS, cảm ơn bạn đã quan tâm bài viết này.
